网站建设目的是什么全国31省市疫情最新消息今天
引言
我们知道Transformer很好用,但它设定的最长长度是512。像一篇文章超过512个token是很容易的,那么我们在处理这种长文本的情况下也想利用Transformer的强大表达能力需要怎么做呢?
本文就带来一种处理长文本的Transformer变种——Transformer-XL,它也是XLNet的基石。这里的XL取自EXTRAL LONG。
论文题目:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
论文地址:https://arxiv.org/pdf/1901.02860.pdf
Transformer
我们先来简单回顾下Transformer,不熟悉的可以先看关于Transformer论文全文翻译——[论文翻译]Attention Is All You Need
。

我们重点回顾输入向量的计算方式,如上图底部所示,词嵌入(Embedding) ➕ 位置编码(Positional Encoding)。
假设有两个输入token,它们的位置分别在i,ji,ji,j处,用xi,xjx_i,x_jxi,xj相应地表示。
记
ExiT∈R1×dE_{x_i}^T \in \Bbb R^{1 \times d}ExiT∈R1×d为token xix_ixi的词嵌入,ExjE_{x_j}Exj为 token xjx_jxj的词嵌入;
UiT∈R1×dU_i^T \in \Bbb R^{1 \times d}UiT∈R1×d和UjT∈R1×dU_j^T \in \Bbb R^{1 \times d}UjT∈R1×d分别为第iii和第jjj处的位置编码。
这里ddd为嵌入大小。
一般向量默认是列向量,而行向量表示需要加上个转置。所以,上面两个记号上有转置。
那么在计算token xjx_jxj相对于token xjx_jxj的Self-Attention时,首先会计算出qiq_iqi和kjk_jkj:
qi=(ExiT+UiT)WqT∈R1×dkj=(Exj+Uj)WkT∈R1×d(1)q_i = (E_{x_i}^T + U_i^T)W_q^T \in \Bbb R^{1\times d}\\ k_j = (E_{x_j} + U_j)W_k^T \in \Bbb R^{1\times d} \tag 1 qi=(ExiT+UiT)WqT∈R1×dkj=(Exj+Uj)WkT∈R1×d(1)
其中WqTW_q^TWqT和WkT∈Rd×dW_k^T \in \Bbb R^{d \times d}WkT∈Rd×d。
这里把词嵌入+位置编码分开写,后面会看到为什么这么做。
接下来,在计算它们两之间的注意力得分时,直接拿这两个向量做点积得到一个标量,注意维度:
qi⋅kjT=(ExiT+UiT)WqT⋅((ExjT+UjT)WkT)T=(ExiTWqT+UiTWqT)⋅(WkExj+WkUj)=ExiTWqTWkExj+ExiTWqTWkUj+UiTWqTWkExj+UiTWqTWkUj(2)\begin{aligned} q_i \cdot k_j^T &= (E_{x_i}^T + U_i^T)W_q^T \cdot \left ( (E_{x_j}^T + U_j^T)W_k^T \right)^T \\ &= (E_{x_i}^TW_q^T + U_i ^TW_q^T) \cdot ( W_k E_{x_j} + W_kU_j) \\ &= E_{x_i}^TW^T_qW_k E_{x_j} + E_{x_i}^TW^T_qW_kU_j + U_i ^TW_q^T W_k E_{x_j} + U_i ^TW_q^T W_kU_j \end{aligned} \tag 2 qi⋅kjT=(ExiT+UiT)WqT⋅((ExjT+UjT)WkT)T=(ExiTWqT+UiTWqT)⋅(WkExj+WkUj)=ExiTWqTWkExj+ExiTWqTWkUj+UiTWqTWkExj+UiTWqTWkUj(2)
相当于把它们进行了展开,整个过程应该没什么问题。
下面进入本文的主题。
Transformer-XL
我们先来看如果想在Transformer中处理长文本的话,要怎么做呢?
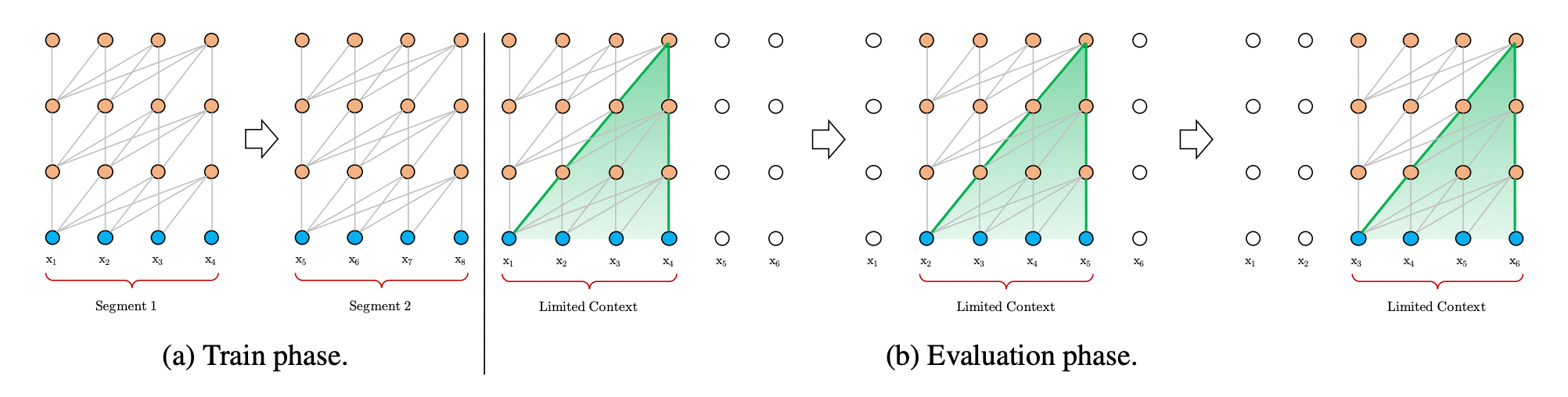
图1: Transformer中处理长文本的传统方法
而Transformer-XL的提出就是为了处理(address)上面的两个问题。
上图给出了块长度为4时的一个示例,可以看到,在训练阶段,Transformer分别对第一个块中的序列x1,x2,x3,x4x_1,x_2,x_3,x_4x1,x2,x3,x4和第二块中的序列x5,x6,x7,x8x_5,x_6,x_7,x_8x5,x6,x7,x8进行建模(modeling)。
而在评估(evaluation)阶段,为了不将文本切成块,会通过类似移动窗口的方式,一个一个token地向后移动,这种方法效率非常低下。
为此,Transformer-XL提出了两种改进策略——块级别循环(Segment-level Recurrent)和相对位置编码(Relative Positional Encoding)。
我们先来看第一个。
块级别循环
块级别循环,全称是状态复用的块级别循环(Segment-Level Recurrence with State Reuse)。如下图(a)部分:
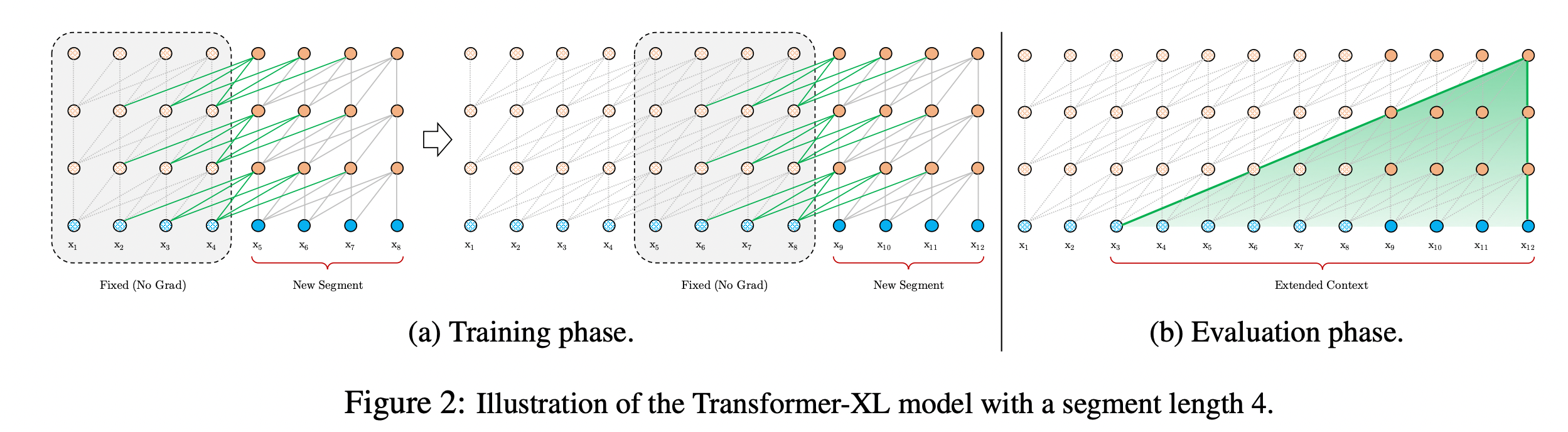
图2: Transformer-XL中处理长文本的方法
上面有两个块,每个块都会做Self-Attention,块之间有一些绿色的连线。在第二个块的时候,可以把第一个块的某些信息通过绿色的连线传递过来,那么它是怎么实现的呢?
实际上非常简单,它的思想是,在跑完第一个块的信息后,把它中间所有的隐藏层向量都缓存起来,然后跑第二个块的信息时,可以拿到这些缓存向量。
下面用公式描述一下,假设两个连续长度为LLL的块分别为sτ=xτ,1,⋯,xτ,L\pmb s_{\tau}=\pmb x_{\tau,1}, \cdots,x_{\tau,L}sτ=xτ,1,⋯,xτ,L和sτ+1=xτ+1,1,⋯,xτ+1,L\pmb s_{\tau+1}=\pmb x_{\tau+1,1}, \cdots,x_{\tau+1,L}sτ+1=xτ+1,1,⋯,xτ+1,L。记由第τ\tauτ个块sτ\pmb s_{\tau}sτ在第nnn层上产生的隐藏状态序列hτn∈RL×d\pmb h_{\tau}^n \in \Bbb R^{L\times d}hτn∈RL×d,ddd为隐藏层维度大小。
那么对于片段sτ+1\pmb s_{\tau +1}sτ+1在第nnn层上的隐藏状态hτ+1n\pmb h_{\tau+1}^nhτ+1n计算如下:
h~τ+1n−1=[SG(hτn−1)∘hτ+1n−1](3)\pmb {\tilde h _{\tau +1}^{n-1}} = [\text{SG}(\pmb {h _{\tau}^{n-1}}) \circ \pmb { h _{\tau +1}^{n-1}} ] \tag 3 h~τ+1n−1=[SG(hτn−1)∘hτ+1n−1](3)
qτ+1n,kτ+1n,vτ+1n=hτ+1n−1WqT,h~τ+1n−1WkT,h~τ+1n−1WvT(4)\pmb q_{\tau +1}^n, \pmb k_{\tau +1}^n,\pmb v_{\tau +1}^n = \pmb h_{\tau+1}^{n-1}W^T_q , \pmb { \tilde h_{\tau+1}^{n-1}}W^T_k, \pmb { \tilde h_{\tau+1}^{n-1}}W^T_v \tag 4 qτ+1n,kτ+1n,vτ+1n=hτ+1n−1WqT,h~τ+1n−1WkT,h~τ+1n−1WvT(4)
hτ+1n=Transformer-Layer(qτ+1n,kτ+1n,vτ+1n)(5)\pmb h_{\tau+1}^n = \text{Transformer-Layer}(\pmb q_{\tau +1}^n, \pmb k_{\tau +1}^n,\pmb v_{\tau +1}^n) \tag 5 hτ+1n=Transformer-Layer(qτ+1n,kτ+1n,vτ+1n)(5)
其中函数SG(⋅)\text{SG}(\cdot)SG(⋅)表示停止梯度传输;记号[hu∘hv][\pmb h_u \circ \pmb h_v][hu∘hv]表示沿着长度(时间步)维度拼接两个隐藏状态序列;WWW表示全连接权重。
这里通过拼接当前块第n−1n-1n−1层的隐藏状态和缓存的前一块第n−1n-1n−1层的隐藏状态来生成扩展的上下文h~τ+1n−1\pmb {\tilde h _{\tau +1}^{n-1}}h~τ+1n−1。
与传统的Transformer的主要不同点在于键kτ+1n\pmb k_{\tau +1}^nkτ+1n和值vτ+1n\pmb v_{\tau +1}^nvτ+1n的计算依赖于扩展的上下文h~τ+1n−1\pmb {\tilde h _{\tau +1}^{n-1}}h~τ+1n−1,即用到了前一块的缓存信息hτn−1\pmb {h _{\tau}^{n-1}}hτn−1。
同时可以看到在计算查询qτ+1n\pmb q_{\tau +1}^nqτ+1n时只会基于当前块来计算。这种设计体现在了上图(a)的绿线中。
这种状态复用的块级别循环机制应用于语料库中每两个连续的块,本质上是在隐藏状态下产生一个块级别的循环。在这种机制下,Transformer利用的有效上下文可以远远超出两个块。注意到这种在hτ+1n\pmb h_{\tau +1}^nhτ+1n和hτn−1\pmb h_{\tau}^{n-1}hτn−1的循环依赖每块间向下移动一层,与传统RNN中的同层循环不同。因此,最大可能的依赖长度随块的长度LLL和层数NNN呈线性增长。这种机制和RNN中常用的随时间反向传播机制(Back Propagation Through Time,BPTT)类似。然而,在这里是将整个序列的隐藏层状态全部缓存,而不是像BPTT机制中只会保留最后一个状态。
在训练的时候,先训练第一块,更新完第一块的权重后,然后固定中间的隐藏状态向量。在训练第二块的时候,读取刚才保存那些向量,在训练第二块的时候,还是只更新第二块的权重,不过可以隐式地用到第一块的信息(通过绿线传递过来)。梯度不会沿着绿线进行更新,因此实际上学的还是一个块之间的信息。
通过这种方式可以延长依赖的长度到N倍,N就是网络的深度(块的个数)。
这样解决了上下文碎片问题,让模型可以捕获到长期依赖的信息。而评估阶段就更简单了,此时可以直接拿到全部的上下文信息,沿着上面的绿线将信息向后传递,而不需要像图1(b)那样从头开始计算。每次可以以块进行移动,而不是以token为单位进行移动,大大加快了推理过程。
虽然它的思想很简单,但如果直接实现的话会发现表现很差,因为这里还有一个问题,就是不连贯的位置编码问题。这就涉及到了第二个改进策略,相对位置编码。
相对位置编码
如果直接简单地把原来Transformer的绝对位置编码信息应用到块级别的循环上就会很奇怪:
[0,1,2,3]→[0,1,2,3,0,1,2,3][0,1,2,3] \rightarrow [0,1,2,3,0,1,2,3] [0,1,2,3]→[0,1,2,3,0,1,2,3]
假设和上面的例子一样,块长度限制为4。现在长度为8之后就会变成两个单独的块,对应的位置编码就成了[0,1,2,3,0,1,2,3][0,1,2,3,0,1,2,3][0,1,2,3,0,1,2,3]。
这样模型无法区分第一个块的第2个位置编码和第二个块的第2个位置编码,认为是一样的,这显然是不合理的。因为位置编码的目的是为了引入位置信息。Transformer-XL针对这种情况提出了相对位置编码。
位置信息的重要性体现在注意力分数的计算上面,在传统Transformer中,同一块(segment)内的查询qiq_iqi和键向量kjk_jkj的注意力分数计算如下:

就是上文公式(2)(2)(2),拆分成四项后,为每项进行编号,从(a)(a)(a)到(d)(d)(d)。
ExiT∈R1×dE_{x_i}^T \in \Bbb R^{1 \times d}ExiT∈R1×d为token xix_ixi的词嵌入,ExjE_{x_j}Exj为 token xjx_jxj的词嵌入;
UiT∈R1×dU_i^T \in \Bbb R^{1 \times d}UiT∈R1×d和UjT∈R1×dU_j^T \in \Bbb R^{1 \times d}UjT∈R1×d分别为第iii和第jjj处的绝对位置编码。
原本的做法里面,位置嵌入是绝对位置,因此如果是第i个位置,这个UiU_iUi都会是一样的(不管是哪个块)。
基于仅依赖相对位置信息的思想,Transformer-XL提出了改进如下:

其中为每项进行编号,从下面展开描述一下它的改进点:
- 将(b)(b)(b)和(d)(d)(d)项中计算key向量的绝对位置嵌入UjU_jUj替换为相对位置Ri−jR_{i-j}Ri−j,代表一个相对距离信息。注意这里的RRR是传统Transformer中的正弦函数编码模式,是不需要学习的。
- 引入一个可学习的参数uuu∈Rd\in \Bbb R^d∈Rd去替换(c)(c)(c)项中的query向量UiTWqTU_i^TW_q^TUiTWqT。这样新的query向量uuu对于所有的位置都是一样的,因为是以位置iii为基准点,所以iii使用的位置嵌入是一个固定的嵌入,只需要考虑iii和jjj之间相关位置的关系。同理,用可学习的参数vvv∈Rd\in \Bbb R^d∈Rd去替换(d)(d)(d)项中的UiTWqTU_i^TW_q^TUiTWqT。
- 将WkW_kWk分成两个权重矩阵Wk,EW_{k,E}Wk,E和Wk,RW_{k,R}Wk,R,以分别产生基于内容的key向量和基于位置的key向量。
在新的计算公式中,每项都有直观的意义:
- (a)(a)(a)项表示基于内容的相关度,计算query xix_ixi和key xjx_jxj内容之间的关联信息;
- (b)(b)(b)项捕获内容相关的位置偏置,计算query xix_ixi的内容与key xjx_jxj的位置编码之间的关联信息,Ri−jR_{i-j}Ri−j表示两者的相对位置信息,取RRR中的第i−ji-ji−j行;
- (c)(c)(c)项表示全局内容偏置,计算query xix_ixi的位置编码与key xjx_jxj的内容之间的关联信息;
- (d)(d)(d)项表示全局位置偏置,计算query xix_ixi与key xjx_jxj的位置编码之间的关联信息;
把块级别循环和相对位置编码的信息合并后,我们就得到了Transformer-XL的最终架构。对于一个NNN层的Transformer-XL的单个注意力头,对于n=1,⋯,Nn=1,\cdots,Nn=1,⋯,N有:

这样对于每个query,所有的位置嵌入都是一样的,对于不同的token注意力偏差也是一样的。
这里的注意力偏差怎么理解?原始的Transformer中的位置编码,对于每个位置都会学一个向量,假设某个token经常出现在第一个位置,比如“今年”这个token,那么模型学到的位置编码可能会包含“今年”这个token的意思,而没有其他不常出现在第一个位置的token信息。也就说第一个位置编码对“今年”产生了偏差。