如何自己做彩票网站成都seo论坛
目录
- 注册 实名
- 得到API链接和账密
- Python3
- requests调用
- Scpay
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
注册 实名
注册巨量http
用户概览中领取1000ip,在动态代理中使用.用来测试一下还是不错的
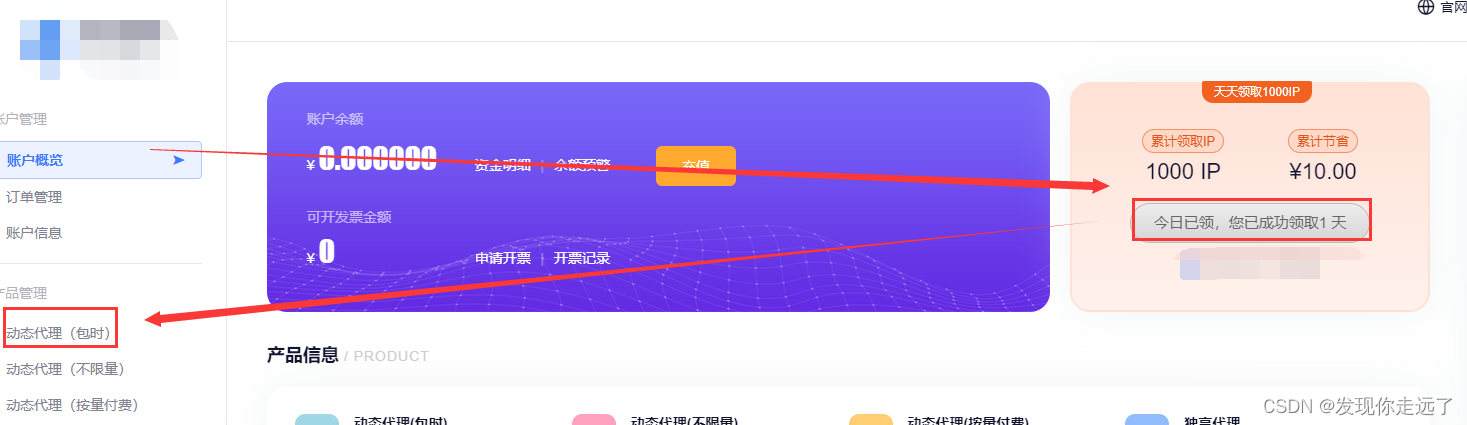

得到API链接和账密
初次测试建议你提取数量设置为1,api链接会用到
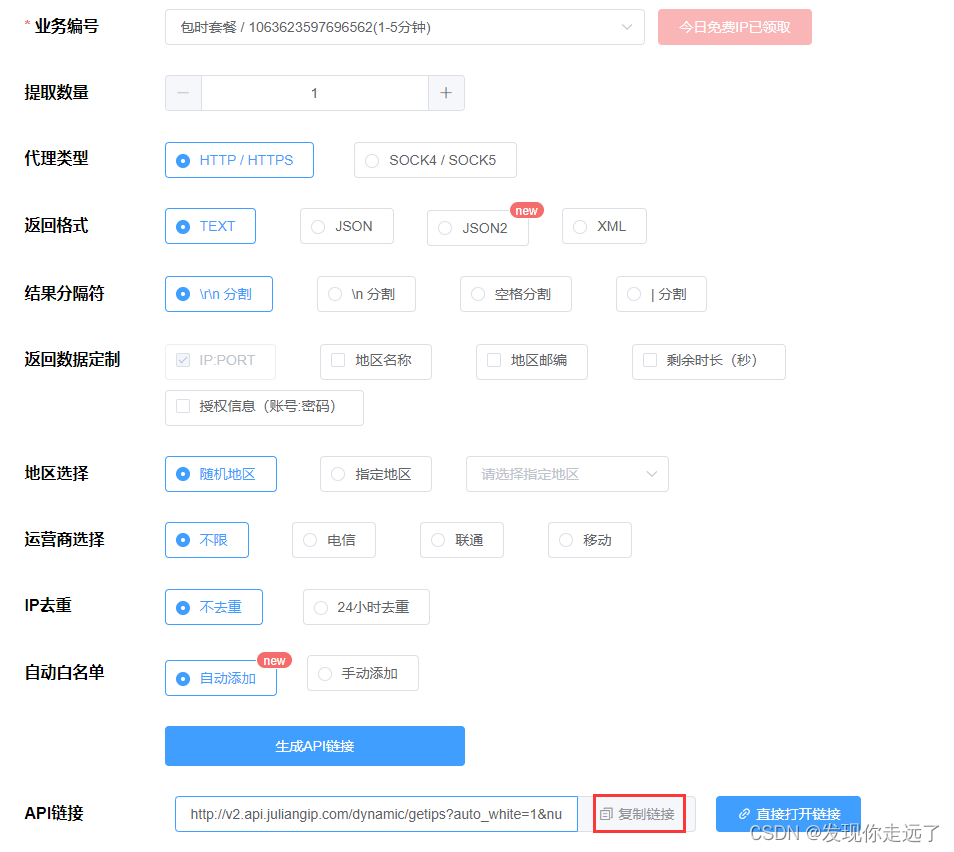
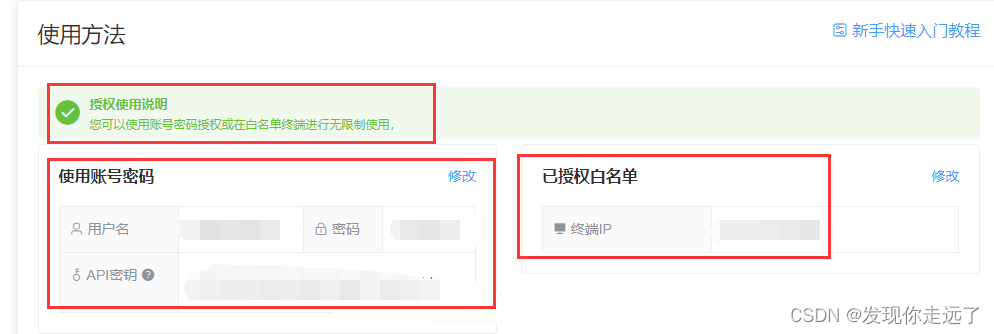
用户名和密码后面会用到
Python3
官方文档URLhttps://www.juliangip.com/help/sdk/http/#python3
requests调用
注意这里的返回格式是txt,修改下面的api和用户名密码即可使用

"""
使用requests请求代理服务器
请求http和https网页均适用
"""import requests# 提取代理API接口,获取1个代理IP
# api_url = "http://v2.api.juliangip.com/dynamic/getips?num=1&pt=1&result_type=text&split=1&trade_no=1834987042xxxxxx&sign=9e489baa3bf149593f149d7252efd006"
api_url = 'API链接'# 获取API接口返回的代理IP
proxy_ip = requests.get(api_url).text# 用户名密码认证(动态代理/独享代理)
username = "用户名"
password = "密码"proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": proxy_ip},
}# 白名单方式(需提前设置白名单)
# proxies = {
# "http": "http://%(proxy)s/" % {"proxy": proxy_ip},
# "https": "http://%(proxy)s/" % {"proxy": proxy_ip},
# }# 要访问的目标网页
target_url = "https://www.juliangip.com/api/general/Test"# 使用代理IP发送请求
response = requests.get(target_url, proxies=proxies)# 获取页面内容
if response.status_code == 200:print(response.text)
Scpay
下面以我的项目myscrapy为例子
在你的scrapy下新建extensions文件夹,新建JuLiang_IP_extend.py文件
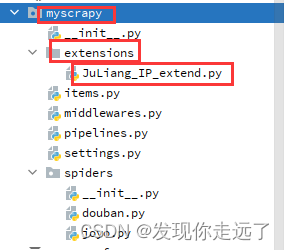
- JuLiang_IP_extend.py
修改api链接和time.sleep(15)
注意这里的api的返回格式

import time
import threadingimport requests
from scrapy import signals# 提取代理IP的api
api_url = 'API链接'
foo = Trueclass Proxy:def __init__(self, ):self._proxy_list = requests.get(api_url).json().get('data').get('proxy_list')@propertydef proxy_list(self):return self._proxy_list@proxy_list.setterdef proxy_list(self, list):self._proxy_list = listpro = Proxy()
print(pro.proxy_list)class MyExtend:def __init__(self, crawler):self.crawler = crawler# 将自定义方法绑定到scrapy信号上,使程序与spider引擎同步启动与关闭# scrapy信号文档: https://www.osgeo.cn/scrapy/topics/signals.html# scrapy自定义拓展文档: https://www.osgeo.cn/scrapy/topics/extensions.htmlcrawler.signals.connect(self.start, signals.engine_started)crawler.signals.connect(self.close, signals.spider_closed)@classmethoddef from_crawler(cls, crawler):return cls(crawler)def start(self):t = threading.Thread(target=self.extract_proxy)t.start()def extract_proxy(self):while foo:pro.proxy_list = requests.get(api_url).json().get('data').get('proxy_list')#设置每15秒提取一次iptime.sleep(15)def close(self):global foofoo = False
- middlewares.py
修改用户名和密码
from scrapy import signals
from myscrapy.extensions.JuLiang_IP_extend import pro
from w3lib.http import basic_auth_header
import random
class ProxyDownloaderMiddleware:def process_request(self, request, spider):proxy = random.choice(pro.proxy_list)request.meta['proxy'] = "http://%(proxy)s" % {'proxy': proxy}# 用户名密码认证(动态代理/独享代理)request.headers['Proxy-Authorization'] = basic_auth_header('用户名', '密码') # 白名单认证可注释此行return None
- 修改setting.py
启用插件和中间件
# 配置下载中间件
DOWNLOADER_MIDDLEWARES = {'myscrapy.middlewares.ProxyDownloaderMiddleware': 100, # ip代理中间件
}# 插件路径 注意路径
EXTENSIONS = {'myscrapy.extensions.JuLiang_IP_extend.MyExtend': 300, #ip代理拓展
}总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』