自己能做企业网站吗上海网络推广优化公司
什么是PEFT?What is PEFT?
PEFT(Parameter Efficient Fine-Tuning)是一系列让大规模预训练模型高效适应于新任务或新数据集的技术。
PEFT在保持大部分模型权重冻结,只修改或添加一小部份参数。这种方法极大得减少了计算量和存储开销,但保证了大模型在多个任务上的复用性。
为什么需要PEFT?Why do we need PEFT?
扩展性挑战
大规模预训练模型如GPT、BERT或ViT拥有大量参数。为每个具体任务全参微调这些模型不仅耗费大量计算量,同时需要巨大的存储资源,这些资源往往难以承担。
提升迁移学习效率
PEFT很好地利用了预训练模型在通用任务上的能力,同时提升了模型在具体任务上的表现。同时PEFT能减少过拟合并提供更好的通用型。
PEFT如何工作?How does PEFT work?
1. 冻结大部人预训练模型的参数
2. 修改或添加小部份参数
3. 模型训练时,只修改小部份参数即可
PEFT方法分类
Additive PEFT(加性微调):在模型特定位置添加可学习的模块或参数。如:Adapters、Prompt-Tuning
Selective PEFT(选择性微调):在微调过程只更新模型中的一部份参数,保持其余参数固定。如:BitFit、HyperNetworks
Reparameterization PEFT(重参数化微调):构建原始模型参数的低秩表示,在训练过程中增加可学习参数以实现高效微调。如:LoRA (Low-Rank Adaptation)、Prefix-Tuning

Prefix Tuning
Prefix Tuning在每个Transformer Block层加入Prefix Learnable Parameter(Embedding层),这些前缀作为特定任务的上下文,预训练模型的参数保持冻结。相当于在seq_len维度中,加上特定个数的token。
class LoRA(nn.Module):def __init__(self, original_dim, low_rank):super().__init__()self.low_rank_A = nn.Parameter(torch.randn(original_dim, low_rank)) # Low-rank matrix Aself.low_rank_B = nn.Parameter(torch.randn(low_rank, original_dim)) # Low-rank matrix Bdef forward(self, x, original_weight):# x: Input tensor [batch_size, seq_len, original_dim]# original_weight: The frozen weight matrix [original_dim, original_dim]# LoRA weight updatelora_update = torch.matmul(self.low_rank_A, self.low_rank_B) # [original_dim, original_dim]# Combined weight: frozen + LoRA updateadapted_weight = original_weight + lora_update# Forward passoutput = torch.matmul(x, adapted_weight) # [batch_size, seq_len, original_dim]return output但Prefix Tuning在需要更深层次模型调整的任务上表现较差。

Adapters
Adapters是较小的,可训练的,插入在预训练模型层之间的模块。每个Adapter由一个下采样模块,一个非线性激活和一个上采样模块组层。预训练模型参数保持冻结,adapters用于捕捉具体任务的知识。

基于MindSpore的模型微调
环境需求:2.3.0-cann 8.0.rc1-py 3.9-euler 2.10.7-aarch64-snt9b-20240525100222-259922e
Prefix-Tuning
安装mindNLP
pip install mindnlp
加载依赖
# 模块导入 and 参数初始化
import os
import mindspore
from mindnlp.transformers import AutoModelForSeq2SeqLM
# peft相关依赖
from mindnlp.peft import get_peft_config, get_peft_model, get_peft_model_state_dict, PrefixTuningConfig, TaskTypefrom mindnlp.dataset import load_dataset
from mindnlp.core import opsfrom mindnlp.transformers import AutoTokenizer
from mindnlp.common.optimization import get_linear_schedule_with_warmup
from tqdm import tqdm# 演示模型 t5-small
model_name_or_path = "t5-small"
tokenizer_name_or_path = "t5-small"
checkpoint_name = "financial_sentiment_analysis_prefix_tuning_v1.ckpt"max_length = 128
lr = 1e-2
num_epochs = 5
batch_size = 8通过mindnlp.peft库加载模型并进行prefix配置
# Prefix-Tuning参数设置以及配置模型
peft_config = PrefixTuningConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, num_virtual_tokens=20)
# 加载预训练模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
# 加载加入prefix后的模型
model = get_peft_model(model, peft_config)model.print_trainable_parameters()加载、预处理数据集
# 微调 t5 for 金融情感分析
# input: 金融短句
# output: 情感类别
# 由于华为云无法连接huggingface,因此需要先本地下载,再上传至华为云
mindspore.dataset.config.set_seed(123)
# loading dataset
dataset = load_dataset("financial_phrasebank", cache_dir='/home/ma-user/work/financial_phrasebank/')train_dataset, validation_dataset = dataset.shuffle(64).split([0.9, 0.1])classes = dataset.source.ds.features["label"].names
# 将标签号映射为文本
def add_text_label(sentence, label):return sentence, label, classes[label.item()]
# 输入为两列,输出为三列
train_dataset = train_dataset.map(add_text_label, ['sentence', 'label'], ['sentence', 'label', 'text_label'])
validation_dataset = validation_dataset.map(add_text_label, ['sentence', 'label'], ['sentence', 'label', 'text_label'])# 加载t5模型的分词器
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)# tokenize 输入和text_label
import numpy as np
from mindnlp.dataset import BaseMapFunction
from threading import Lock
# 线程锁?
lock = Lock()class MapFunc(BaseMapFunction):def __call__(self, sentence, label, text_label):lock.acquire()model_inputs = tokenizer(sentence, max_length=max_length, padding="max_length", truncation=True)labels = tokenizer(text_label, max_length=2, padding="max_length", truncation=True)lock.release()# 提取 labels 中的 input_ids# 这些 ID 实际上是模型词汇表中相应单词或子词单元的位置索引。# 因此,input_ids 是一个整数列表,代表了输入文本序列经过分词和编码后的结果,它可以直接作为模型的输入。labels = labels['input_ids']# 将 labels 中的填充标记替换为 -100,这是常见的做法,用于告诉损失函数忽略这些位置。labels = np.where(np.equal(labels, tokenizer.pad_token_id), -100, lables)return model_inputs['input_ids'], model_inputs['attention_mask'], labelsdef get_dataset(dataset, tokenizer, shuffle=True):input_colums=['sentence', 'label', 'text_label']output_columns=['input_ids', 'attention_mask', 'labels']dataset = dataset.map(MapFunc(input_colums, output_columns),input_colums, output_columns)if shuffle:dataset = dataset.shuffle(64)dataset = dataset.batch(batch_size)return datasettrain_dataset = get_dataset(train_dataset, tokenizer)
eval_dataset = get_dataset(validation_dataset, tokenizer, shuffle=False)进行微调训练
# 初始化优化器和学习策略
from mindnlp.core import optimoptimizer = optim.AdamW(model.trainable_params(), lr=lr)# 动态学习率
lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0,num_training_steps=(len(train_dataset) * num_epochs),
)from mindnlp.core import value_and_graddef forward_fn(**batch):outputs = model(**batch)loss = outputs.lossreturn lossgrad_fn = value_and_grad(forward_fn, model.trainable_params())for epoch in range(num_epochs):model.set_train()total_loss = 0train_total_size = train_dataset.get_dataset_size()for step, batch in enumerate(tqdm(train_dataset.create_dict_iterator(), total=train_total_size)):optimizer.zero_grad()loss = grad_fn(**batch)optimizer.step()total_loss += loss.float()lr_scheduler.step()model.set_train(False)eval_loss = 0eval_preds = []eval_total_size = eval_dataset.get_dataset_size()for step, batch in enumerate(tqdm(eval_dataset.create_dict_iterator(), total=eval_total_size)):with mindspore._no_grad():outputs = model(**batch)loss = outputs.losseval_loss += loss.float()eval_preds.extend(tokenizer.batch_decode(ops.argmax(outputs.logits, -1).asnumpy(), skip_special_tokens=True))# 验证集losseval_epoch_loss = eval_loss / len(eval_dataset)eval_ppl = ops.exp(eval_epoch_loss)# 测试集losstrain_epoch_loss = total_loss / len(train_dataset)train_ppl = ops.exp(train_epoch_loss)print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")模型评估
# 模型评估
correct = 0
total = 0ground_truth = []correct = 0
total = 0ground_truth = []for pred, data in zip(eval_preds, validation_dataset.create_dict_iterator(output_numpy=True)):true = str(data['text_label'])ground_truth.append(true)if pred.strip() == true.strip():correct += 1total += 1
accuracy = correct / total * 100
print(f"{accuracy=} % on the evaluation dataset")
print(f"{eval_preds[:10]=}")
print(f"{ground_truth[:10]=}")模型保存
# 模型保存
# saving model
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)加载模型进行推理
# 加载模型并推理
from mindnlp.peft import PeftModel, PeftConfigconfig = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)model.set_train(False)example = next(validation_dataset.create_dict_iterator(output_numpy=True))
print("input", example["sentence"])
print(example["text_label"])
inputs = tokenizer(example['text_label'], return_tensors="ms")with mindspore._no_grad():outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)print(tokenizer.batch_decode(outputs.numpy(), skip_special_tokens=True))BitFit
BitFit需要冻结除Bias外的所有参数,只训练Bias参数。
for n, p in model.named_parameters():if "bias" not in n:p.requires_grad = Falseelse:p.requires_grad = True其余数据预处理代码和训练代码与上述相同。
LoRA
LoRA(Low Rank Adaptation)专注于学习一个低秩矩阵。通过在冻结的预训练权重中添加可学习的低秩矩阵。在前向传递过程中,冻结的权重和新的低秩矩阵参与计算。
低秩矩阵指的是相较于原矩阵,秩更低的矩阵。加入一个矩阵的形状为m x n,矩阵的秩最多为min(m, n),低秩矩阵的秩数远远小于原本的m和n。
LoRA微调不更新原本m x n的权重矩阵,转而更新更小的低秩矩阵A(m, r), B(r, n)。假设W0为512x512,低秩矩阵的r则可以为16,这样需要更新的数据只需要(512x16+16x512)=16384,相较于原来的512x512=262144,少了93.75%。
LoRA实现的基本思路代码
class LoRA(nn.Module):def __init__(self, original_dim, low_rank):super().__init__()self.low_rank_A = nn.Parameter(torch.randn(original_dim, low_rank)) # Low-rank matrix Aself.low_rank_B = nn.Parameter(torch.randn(low_rank, original_dim)) # Low-rank matrix Bdef forward(self, x, original_weight):# x: Input tensor [batch_size, seq_len, original_dim]# original_weight: The frozen weight matrix [original_dim, original_dim]# LoRA weight updatelora_update = torch.matmul(self.low_rank_A, self.low_rank_B) # [original_dim, original_dim]# Combined weight: frozen + LoRA updateadapted_weight = original_weight + lora_update# Forward passoutput = torch.matmul(x, adapted_weight) # [batch_size, seq_len, original_dim]return output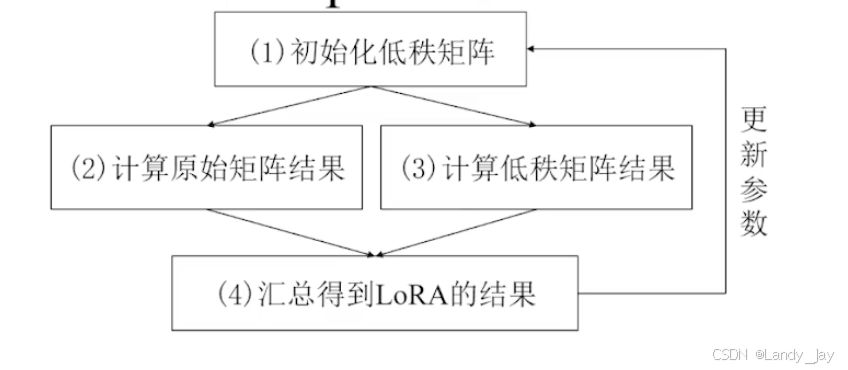
LoRA的MindSpore实现
# creating model
# r 控制适应层的秩,lora_alpha 是缩放因子,而 lora_dropout 定义了在训练期间应用于 LoRA 参数的 dropout 率。
# 缩放因子用于控制低秩矩阵对模型参数更新的影响程度。
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()其余数据预处理代码和训练代码与上述相同。
更多内容可以参考mindspore的官方视频:
【第二课】昇腾+MindSpore+MindSpore NLP:极简风的大模型微调实战_哔哩哔哩_bilibili