网站设计开发软件各种推广平台
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握HIve的join;
⚪ 掌握HIve的查询和排序
⚪ 掌握HIve的beeline
⚪ 掌握HIve的文件格式
⚪ 掌握HIve的基本架构
⚪ 掌握HIve的优化;
一、join
1. 概述
1. 在Hive中,同MySQL一样,提供了多表的连接查询,并且支持left join,right join,inner join,full outer join以及笛卡尔积查询。
2. 在连接查询的时候,如果不指定,那么默认使用的是inner join。
3. 在Hive中,除了支持上述比较常用的join以外,还支持left semi join。当a left semi join b的时候,表示获取a表中的数据哪些在b表中出现过。
2. 案例:
#建表语句
create external table orders (orderid int, orderdate string, productid int, num int) row format delimited fields terminated by ' 'location '/orders';
create external table products (productid int, name string, price double) row format delimited fields terminated by ' ' location '/products';
#左连接 - 以左表为准
select * from orders o left join products p on o.productid = p.productid;
#右连接 - 以右表为准
select * from orders o right join products p on o.productid = p.productid;
#内连接 - 获取两个表都有的数据
select * from orders o inner join products p on o.productid = p.productid;
#全外连接
select * from orders o full outer join products p on o.productid = p.productid;
#笛卡尔积
select * from orders, products;
#需求一:获取每一天卖了多少钱
select o.orderdate, sum(o.num * p.price) from orders o inner join products p on o.productid = p.productid group by o.orderdate;
#需求二:查询哪些商品被卖出去过 - 实际上就是获取商品表中的哪些数据在订单表中出现过
select * from products p left semi join orders o on p.productid = o.productid;
二、查询和排序
1. having
1. 在Hive中,where可以针对字段来进行条件查询,但是where无法针对聚合结果进行条件查询;如果需要对聚合结果进行条件查询,那么此时需要使用having。
2. 案例:
#原始数据
1 Apollo 4900
1 Billy 5100
1 Cary 4800
1 Dylan 5000
1 Ford 4700
2 Apollo 5300
2 Billy 4600
2 Cary 4700
2 Dylan 5100
2 Ford 4500
3 Apollo 5200
3 Billy 4300
3 Cary 4600
3 Dylan 5200
3 Ford 4800
#建表语句
create table salaries (month int, name string, salary double) row format delimited fields terminated by ' ';
#加载数据
load data local inpath '/home/hivedemo/salaries.txt' into table salaries;
#获取平均工资超过5000的员工
select name, avg(salary) as avgsalary from salaries group by name having avgsalary > 5000;
#或者使用子查询
select * from (select name, avg(salary) as avgsalary from salaries group by name)tmp where avgsalary > 5000;
2. 排序
1. 在Hive中,提供了2种排序方式:
a. order by:在排序的时候忽略掉ReduceTask的个数,会将所有的数据进行统一的排序。
b. sort by:在排序的时候会按照ReduceTask的个数产生对应数量的结果文件。在每一个结果文件内部进行排序。在sort by的时候如果不指定,那么会根据排序数据的哈希码来分配到多个不同的文件中。
2. sort by经常结合distribute by来使用,其中利用distribute by对数据进行分类,然后再在每一个分类中对数据进行排序。
3. 如果distribute by和sort by的字段一致,那么可以写成cluster by。
4. 案例:
#原始数据
1 Max 69
1 Eric 70
1 Hank 95
1 Larry 82
2 Justin 74
2 Tim 79
2 Ken 81
2 Ivan 87
3 Nick 95
3 Leo 72
3 Mars 84
3 Reed 91
#建表语句
create table students(class int, name string, score int) row format delimited fields terminated by ' ';
#加载数据
load data local inpath '/home/hivedemo/students.txt' into table students;
#Hive底层会将SQL转化为MapReduce,如果不指定,则只有1个ReduceTask
#1个ReduceTask-> order by
insert overwrite local directory '/home/orderby1' row format delimited fields terminated by ' ' select * from students order by score desc;
#1个ReduceTask -> sort by
insert overwrite local directory '/home/sortby' row format delimited fields terminated by ' ' select * from students sort by score desc;
#在只有一个ReduceTask的前提下,order by和sort by的排序结果一致
#设置ReduceTask的数量
set mapred.reduce.tasks = 3;
#多个ReduceTask -> order by
insert overwrite local directory '/home/orderby2' row format delimited fields terminated by ' ' select * from students order by score desc;
#多个ReduceTask -> sort by
insert overwrite local directory '/home/sortby2' row format delimited fields terminated by ' ' select * from students sort by score desc;
#按班级来分别对学生的成绩排序
insert overwrite local directory '/home/distributeby' row format delimited fields terminated by ' ' select * from students distribute by class sort by score desc;
#如果distribute by和sort by的字段一致,那么可以替换为cluster by
insert overwrite local directory '/home/distributeby2' row format delimited fields terminated by ' ' select * from students distribute by score sort by score;
#等价于
insert overwrite local directory '/home/clusterby' row format delimited fields terminated by ' ' select * from students cluster by score;
三、beeline
1. 概述
1. beeline是Hive提供的一个远程连接工具,允许用户去远程连接指定节点上的Hive服务。
2. beeline底层实际上是利用了JDBC的方式来发起了连接。
3. 需要注意的是,beeline在连接过程中可能会收到Hadoop权限验证的阻拦,所以在启动beeline之前,还需要去更改Hadoop的一部分配置。
2. 步骤
1. 关闭Hadoop。
stop-dfs.sh
stop-yarn.sh
2. 关闭所有的Hive进程 -> RunJar进程。
3. 编辑Hadoop的配置文件。
vim /home/software/hadoop-3.1.3/etc/hadoop/core-site.xml
#添加如下配置
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
4. 重新启动Hadoop。
start-all.sh
5. 启动Hive进程。
hive --service metastore &
hive --service hiveserver2 &
6. 启动beeline。
beeline -u jdbc:hive2://hadoop01:10000/demo -n root
四、文件格式
1. 概述
1. Hive中的数据最终会以文件的形式落地到HDFS上,因此Hive落地的文件存在不同的存储格式,其中最主要的存储格式有4种:textfile,sequencefile,orc和parquet。
2. textfile和sequencefile底层采用的是行存储方式,orc和parquet采用的是列存储方式。
3. 在Hive中,如果不指定,则默认采用的是textfile格式。
2. orc
1. orc格式是Hive0.11开始引入的一种存储格式,采取的列存储方式。
2. 在每一个orc格式文件中,包含1个多个Stripe,1个File Footer以及1个Postscript:
a. Stripe用于orc文件的数据存储数据。
Ⅰ. 默认情况下,Stripe和Block一样的。
Ⅱ. 每一个Stripe中包含3部分:Index Data,Row Data,Stripe Footer:
1. Index Data:用于记录索引,默认情况下,在Stripe中每一万条数据建立一个索引,索引记录这一行数据在各个列中的offset(偏移量)。
2. Row Data:存储数据。在添加数据的时候,往往是按行添加的。在获取到一行数据之后,会将这行数据的每一个字段拆分出来,拆分之后按照列的形式来进行存储。在存储的时候,可以给不同的列执行不同的编码形式,编码之后会将这一列封装成一个或者多个Stream来进行存储。因为同一个列的字段类型是一样的,所以可以针对每一个列采取更好的压缩机制。
3. Stripe Footer:存储每一个Stream的类型、长度等信息。
b. File Footer:用于记录每一个Stripe中存储的数据的行数等信息。
c. Postscript:记录文件是否进行了压缩以及压缩编码等信息,还记录了File Footer在文件中的起始位置。
3. 在读取orc文件的时候,首先通过Postscript来获取File Footer的位置,再通过File Footer来获取Stream的位置,最后来读取Stream中的数据。
五、基本架构
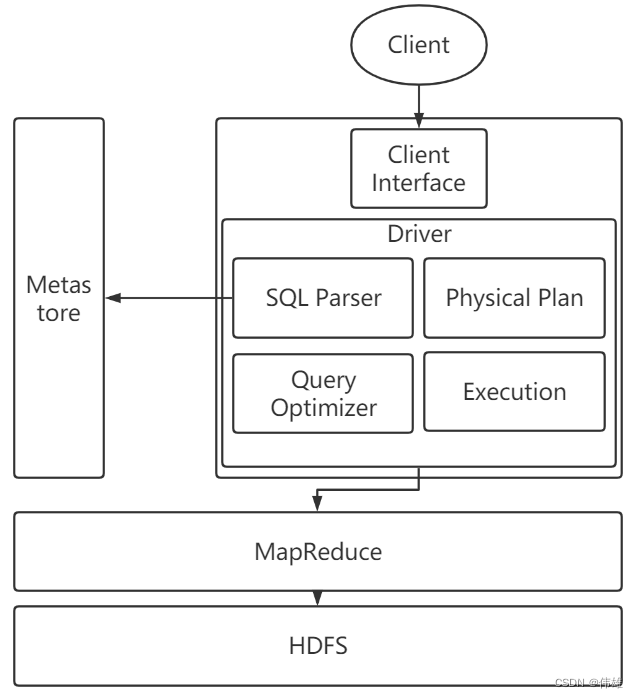
1. Client Interface:提供给用户用于操作Hive的接口,主要有3种:CLI(command-line interface,命令行接口),JDBC/ODBC(用Java代码操作Hive),WEBUI(WEB界面,通过浏览器页面来访问)。
2. Metastore:用于存储Hive的元数据的。如果不指定,Hive的元数据是维系在Derby。当操作Hive的时候,都会先访问Metastore来进行元数据的校验。
3. Driver:驱动器,包含了四个部分:
a. SQL Parser:SQL解析器,解析SQL语句,生成对应的抽象语法树AST。
b. Physical Plan:编译器,会将抽象语法树编译成要执行的逻辑计划。
c. Query Optimizer:优化器,会对逻辑计划进行优化。
d. Execution:将逻辑计划转化为物理计划,例如转化为MapReduce程序。
4. MapReduce:Execution产生程序之后,现阶段会交给MapReduce来执行。
5. HDFS:存储Hive中的数据。
六、优化
1. Fetch值修改
a. 在Hive中,可以通过hive.fetch.task.conversion属性来修改fetch的状态。在Hive3.X中,这个属性的默认值是more,在之前的版本中,这个属性的默认值是minimal。
b. 如果将这个属性的值改为none,那么Hive进行的所有的操作都会转为MapReduce程序,那么会导致部分操作的效率降低,例如select * from person;这个SQL是查询整表,实际上就是将文件从头到尾顺次读取,此时这个操作可以不适用MapReduce。
2. map side join
a. 开启之后,在大表和小表进行join的时候,会自动的将小表中的数据放到内存中,然后在处理大表数据的过程中,如果用到了小表中的数据,那么会自动的从内存中来读取小表的数据而不是再从磁盘上来读取,利用这种方式能够相对有效的提高执行效率。
b. 小表的大小可以通过属性hive.mapjion.smalltable.filesize来调节,默认值是25MB。
c. 可以通过hive.auto.convert.join属性来开启map side join,默认值是true。
d. 在Hive3.X之前,要求必须是小表join大表才会触发这个map side join;但是注意,从Hive3.X开始,不再要求小表的位置。
3. 启用严格模式
a. 将hive.strict.checks.no.partition.filter设置为true之后,要求在查询分区表的时候必须携带分区字段。
b. 将hive.strict.checks.orderby.no.limit设置为true之后,要求在对数据排序的时候必须添加limit字段。
c. 将hive.strict.checks.cartesian.product设置true之后,要求查询结果中不准出现笛卡尔积。
4. JVM重用
a. Hive会将SQL在底层转化为MapReduce来执行,MapReduce在执行的时候会拆分为MapTask和ReduceTask。NodeManager在执行任务的时候,会在本节点上来开启一个JVM子进程执行MapTask或者ReduceTask。默认情况下,每一个JVM子进程只执行一个子任务就会结束,所以如果存在多个子任务就需要开启和关闭多次JVM子进程。
b. 通过属性mapred.job.reuse.jvm.num.tasks来调节,默认为1。