网站设计技术公司宁波seo排名外包公司
🚩🚩🚩Hugging Face 实战系列 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在PyCharm中进行
本篇文章配套的代码资源已经上传
从零构建属于自己的GPT系列1:文本数据预处理
从零构建属于自己的GPT系列2:语言模型训练
0 任务基本流程
- 拿到txt文本数据,本文以15本金庸小说为例
- CpmTokenizer预训练模型将所有文本处理成.pkl的token文件
- 配置训练参数
- token数据转化为索引
- 导入GPT2LMHeadModel预训练中文模型,训练文本数据
- 训练结束得到个人文本数据特征的新模型
- 搭载简易网页界面,部署本地模型
- text-to-text专属GPT搭建完成
- 获取新数据,模型更加个性化
- 优化模型,一次性读取更长文本,生成更长的结果
1 训练数据
在本任务的训练数据中,我选择了金庸的15本小说,全部都是txt文件
数据打开后的样子
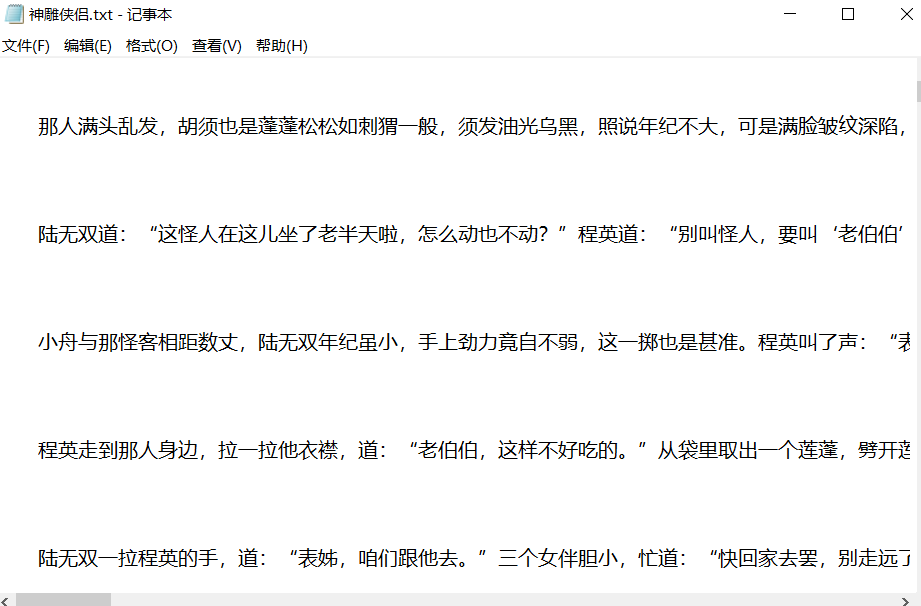
数据预处理需要做的事情就是使用huggingface的transformers包的tokenizer模块,将文本转化为token
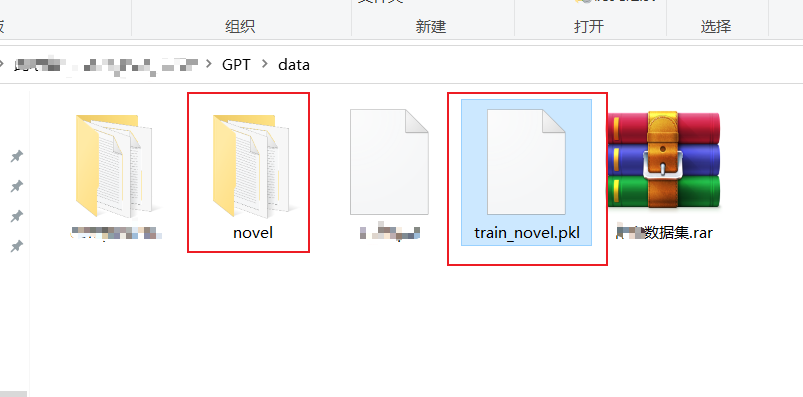
最后生成的文件就是train_novel.pkl文件,就不用在训练的时候读txt文件了
数据预处理:preprocess.py
2 设置参数
import argparse
from utils import set_logger
from transformers import CpmTokenizer
import os
import pickle
from tqdm import tqdm
parser = argparse.ArgumentParser()
parser.add_argument('--vocab_file', default='vocab/chinese_vocab.model', type=str, required=False,help='词表路径')
parser.add_argument('--log_path', default='log/preprocess.log', type=str, required=False, help='日志存放位置')
parser.add_argument('--data_path', default='data/novel', type=str, required=False, help='数据集存放位置')
parser.add_argument('--save_path', default='data/train.pkl', type=str, required=False,help='对训练数据集进行tokenize之后的数据存放位置')
parser.add_argument('--win_size', default=200, type=int, required=False,help='滑动窗口的大小,相当于每条数据的最大长度')
parser.add_argument('--step', default=200, type=int, required=False, help='滑动窗口的滑动步幅')
args = parser.parse_args()
- 参数包
- 本项目utils.py中初始化参数函数
- chinese pre-trained model Tokenizer包
- 系统包
- pickle包,用于将 python 对象序列化(serialization)为字节流,或者将字节流反序列化为 Python 对象
- 进度条包
- 创建一个用于解析命令行参数的 ArgumentParser 对象
- 处理中文文本的变成token的预训练模型的模型文件存放位置
- 运行日志文件存放位置
- 数据集存放位置
- 对训练数据集进行tokenize之后的数据存放位置
- 滑动窗口的大小,相当于每条数据的最大长度
- 滑动窗口的滑动步幅
3 初始化日志对象
logger = set_logger(args.log_path)
def set_logger(log_path):logger = logging.getLogger(__name__)logger.setLevel(logging.INFO)formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')file_handler = logging.FileHandler(filename=log_path)file_handler.setFormatter(formatter)file_handler.setLevel(logging.INFO)logger.addHandler(file_handler)console = logging.StreamHandler()console.setLevel(logging.DEBUG)console.setFormatter(formatter)logger.addHandler(console)return logger
- 选择日志路径,调用日志函数
- 创建 logger 对象
- 设置日志级别为’logging.INFO’
- 创建格式化器 formatter
- 创建文件处理器file_handler并指定了日志文件的路径为log_path
- 设置处理器的日志级别为 logging.INFO
- 添加文件处理器 file_handler 到创建的 logger 对象中
- 创建控制台处理器 console,用 logging.StreamHandler() 创建一个将日志输出到控制台的处理器
- 设置其日志级别为 logging.DEBUG
- 将格式化器 formatter 应用到这个控制台处理器上
- 控制台处理器 console 添加到 logger 对象中
- 返回了这个配置好的 logger 对象
4 初始化
logger = set_logger(args.log_path)
tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model") # pip install jieba
eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符
sep_id = tokenizer.sep_token_id
train_list = []
logger.info("start tokenizing data")
- 初始化日志
- 创建CPMTokenizer 对象,用于分词和处理中文文本
- tokenizer 将特殊标记 转换为其对应的 ID
- 获取分词器中分隔符的 ID
- 最后处理的数据
- 打印
5 处理数据
for file in tqdm(os.listdir(args.data_path)):file = os.path.join(args.data_path, file)with open(file, "r", encoding="utf8") as reader:lines = reader.readlines()for i in range(len(lines)):if lines[i].isspace() != True and lines[i] != '\n':token_ids = tokenizer.encode(lines[i].strip(), add_special_tokens=False) + [eod_id]if i % 1000 == 0:print('cur_step', i, lines[i].strip())else:continuewin_size = args.win_sizestep = args.stepstart_index = 0end_index = win_sizedata = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += stepwhile end_index + 50 < len(token_ids): # 剩下的数据长度,大于或等于50,才加入训练数据集data = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += step# 序列化训练数据
with open(args.save_path, "wb") as f:pickle.dump(train_list, f)
os.listdir(args.data_path):得到该路径下所有文件的文件名字符串并返回一个字符串数组,for file in tqdm的for循环会打印读取进度的进度条- 获得当前文件的完整路径
- 按照
file路径、utf-8编码格式、只读模式打开文件 - 按行来读取文件,line在这里是一个list,list每个数据都对于文件的一行数据
- 按照行数遍历读取文件数据
- 判断当前行是否为空行,或者这行只有换行
- 使用tokenizer进行encode,加入结束索引
- 每1000行进行一次打印操作
- 每1000行进行一次打印操作
- 空行不处理
- 空行不处理
- 滑动窗口长度
- 滑动次数
- 第一个文件的第i行的第一条数据的开始索引
- 第一个文件的第i行的第一条数据的结束索引
- 第一个文件的第i行的第一条数据
- 添加第一条数据到总数据中
- while循环取数据,最后一条数据不足50时就不要了,逐个取数据直到换行,注意这里一行数据可能是一段哦,不一定有逗号或者句号就会换行
- 第一个文件的第i行的第k条数据
- 添加第k条数据到总数据中
- 按照滑动次数更新开始索引
- 按照滑动次数更新结束索引
- 最后所有的数据都保存在了train_list中
- 保存为pickle文件
6 运行过程

结束后,生成.pkl文件,这个文件作为训练数据进行训练

从零构建属于自己的GPT系列1:文本数据预处理
从零构建属于自己的GPT系列2:语言模型训练