唐山市建设局网站投稿平台
分享112个HTML电子商务模板,总有一款适合您
112个HTML电子商务模板下载链接:https://pan.baidu.com/s/13wf9C9NtaJz67ZqwQyo74w?pwd=zt4a
提取码:zt4a
Python采集代码下载链接:采集代码.zip - 蓝奏云

有机蔬菜水果食品商城网站模板
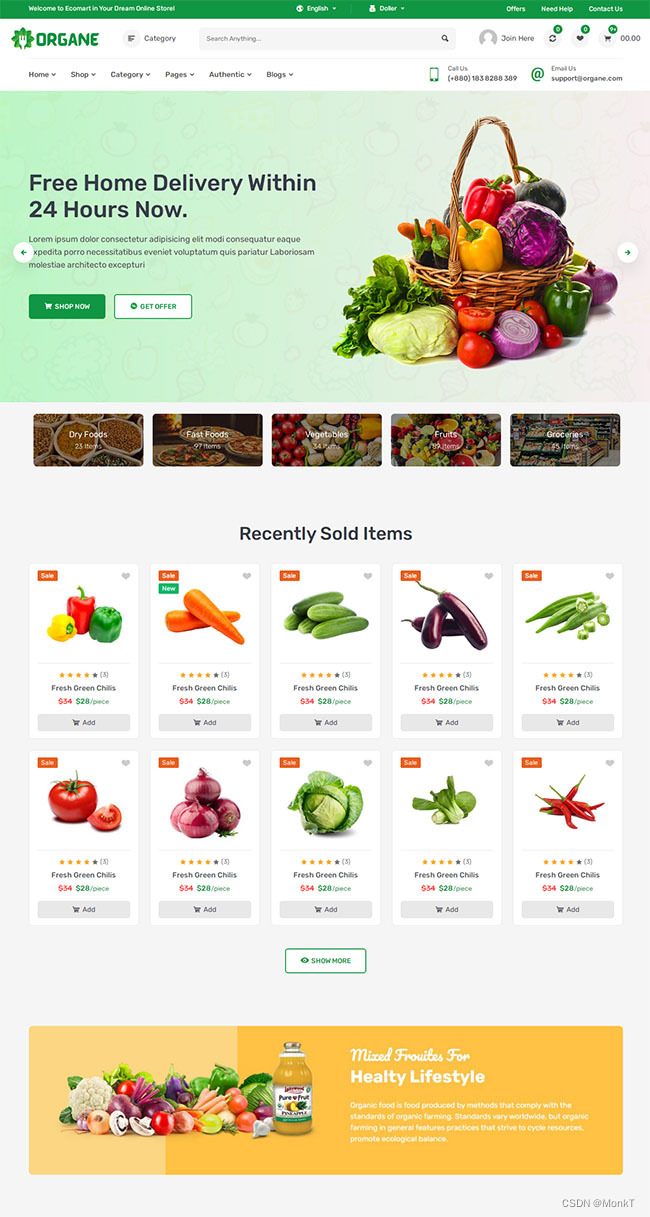
有机蔬菜水果食品商城网站模板是一款使用bootstrap5框架构建的有机食品电商网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
医疗保健用品电商网站模板
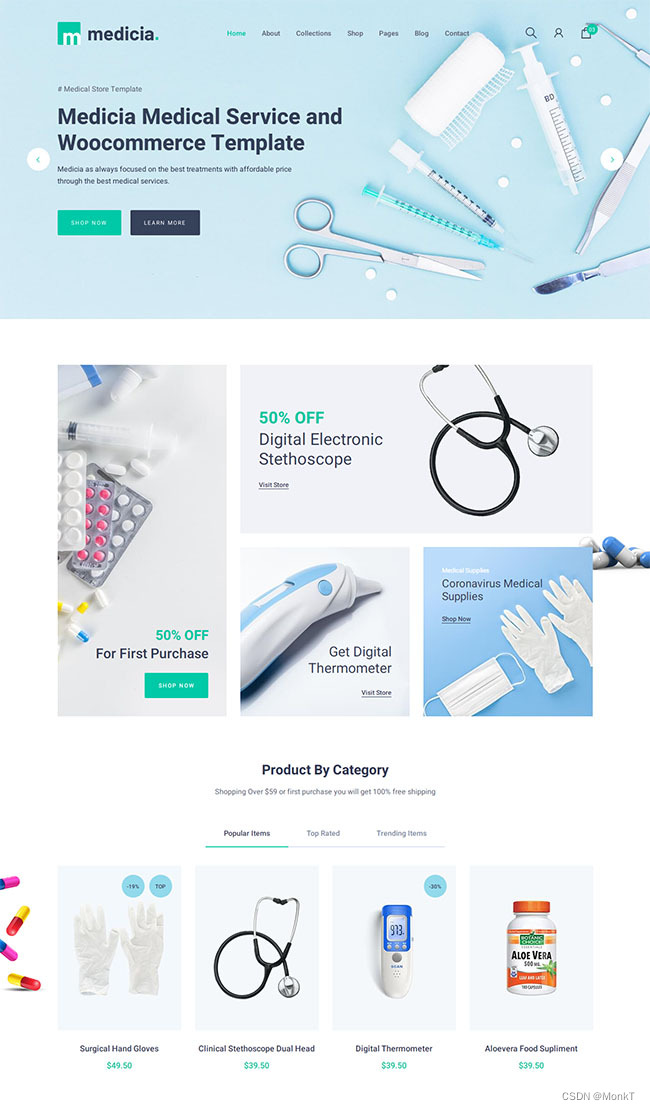
医疗保健用品电商网站模板是一款多功能的基于Bootstrap4构建医疗诊所服务和医疗用品电商网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
有机食品线上超市网站模板
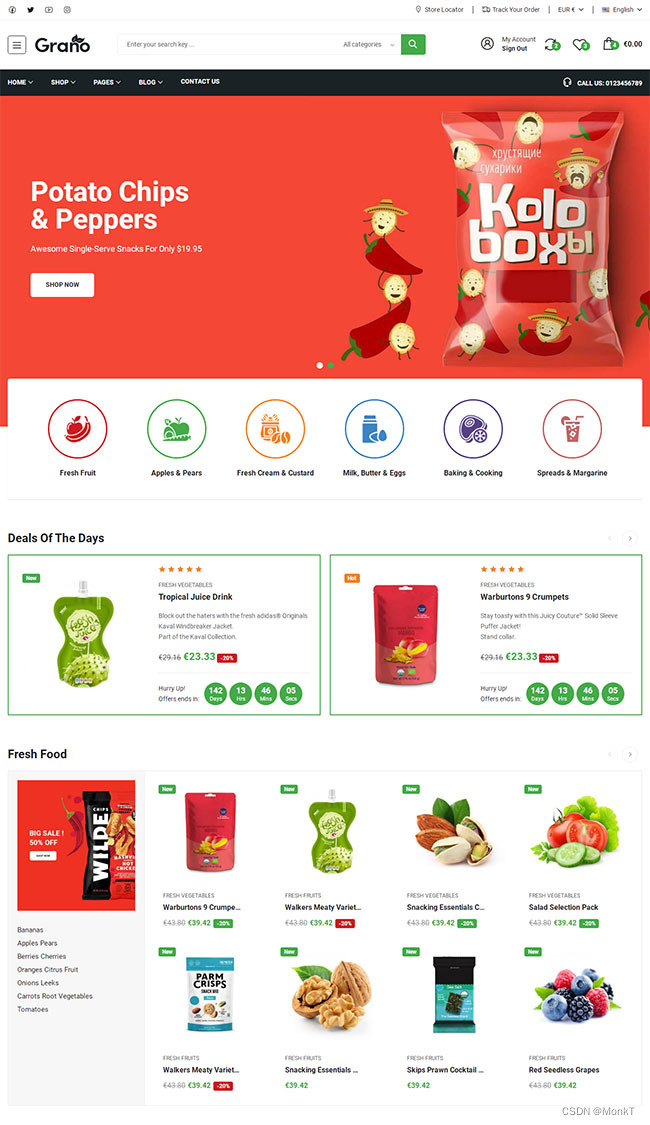
有机食品线上超市网站模板是一款多功能的网上超市电子商务网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
宠物护理店铺响应式网站模板
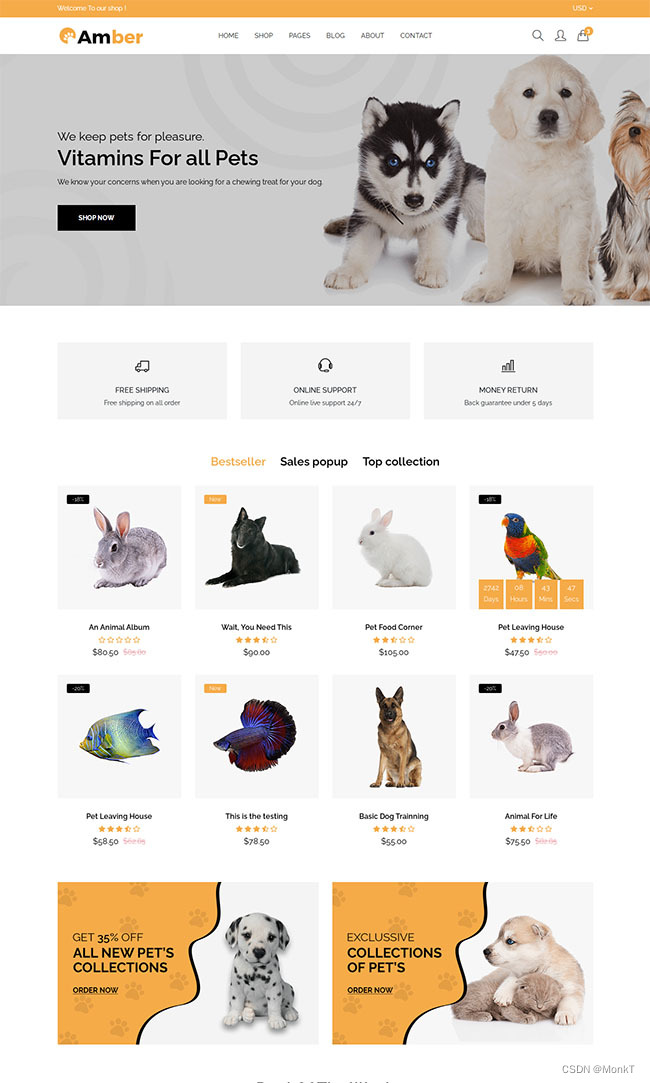
宠物护理店铺响应式网站模板是一款基于Bootstrap构建的在线宠物护理用品商店网站模板下载。提示:本模板调用到谷歌字体库,可能会出现页面打开比较缓慢。
import os
import shutil
import time
from time import sleep
from docx import Document
from docx.opc.oxml import qn
from docx.shared import Inches, RGBColor
from framework.base.BaseFrame import BaseFrame
from sprider.business.DownLoad import DownLoad
from sprider.business.SeleniumTools import SeleniumTools
from sprider.business.SpriderTools import SpriderTools
from selenium import webdriver
from selenium.webdriver.common.by import By
from sprider.model.SpriderEntity import SpriderEntity
from sprider.access.SpriderAccess import SpriderAccesstitle_name = "电子商务"class ChinaZJsSelenium:base_url = "https://sc.chinaz.com/" # 采集的网址save_path = "D:\\Freedom\\Sprider\\ChinaZ\\"sprider_count =112 #正在采集第10页的第7个资源,共38页资源sprider_start_count=111word_content_list = []folder_name = ""page_end_number=0max_pager=24#每页的数量haved_sprider_count =0 # 已经采集的数量page_count = 1 # 每个栏目开始业务content="text/html; charset=gb2312"filter_down_file=[]word_image_count=5 #word插入图片数量 同时也是明细采集图片和描述的数量sprider_detail_index = 0# 明细方法采集的数量 累加sprider_top_level="HTML"医疗设备商店网上销售模板
响应式电子商务商店HTML5模板
蔬菜水果生鲜超市电商网站模板
主题模板在线销售网站模板
游泳用品商店HTML5网站模板
儿童玩具商店Bootstrap模板
电子产品商店HTML5网站模板
食品加工美食电商网站模板
时尚服装商店网站HTML5模板
理发用品店铺电商网站模板
多功能服装销售电商网站模板
家装家具销售电商网站模板
生活家具电子商务网站模板
品牌家具超市电商HTML5模板
钓鱼配件商店HTML5模板
时尚进口服装HTML5模板
网上宠物用品销售网站模板
电子商务图文博客网站模板
时尚女装销售商城网站模板
综合生活类购物网站模板
男性护肤产品HTML5网站模板
蔬菜水果超市电商网站模板
婴儿用品商店HTML5模板
汽车配件销售商店网站模板
时尚家居商城HTML5模板
时装店铺电商公司网站模板
绿色零食店铺电子商务模板
珠宝首饰电商平台网站模板
宽屏大气电商网站HTML5模板
国外服装商城官网网站模板
绿色有机食品商店HTML模板
大气简洁水果商店HTML模板
网上生鲜超市HTML网站模板
品牌茶叶在线销售网站模板
生活好物集合店铺网站模板
养生茶销售展示网站模板
化妆品电商网站响应式模板
智能手表购买电商网站模板
品牌服装电商HTML网页模板
def sprider(self,title_name):"""采集医疗保健 https://sc.chinaz.com/moban/YiLiaoBaoJian.html电子产品 https://sc.chinaz.com/moban/DianZiChanPin.html电子商务 https://sc.chinaz.com/moban/DianZiShangWu.html:return:"""if title_name == "医疗保健":self.first_column_name = "moban"self.folder_name = "HTML医疗保健模板"self.second_column_name = "YiLiaoBaoJian"elif title_name == "电子产品":self.first_column_name = "moban"self.folder_name = "HTML电子产品模板"self.second_column_name = "DianZiChanPin"elif title_name == "电子商务":self.first_column_name = "moban"self.folder_name = "HTML电子商务模板"self.second_column_name = "DianZiShangWu"BaseFrame().right("本次采集参数:sprider_count=" + str(self.sprider_count) + "")BaseFrame().right("本次采集参数:title_name="+title_name+"")BaseFrame().right("本次采集参数:second_column_name=" + self.second_column_name + "")# self.folder_name = "JS表单验证"self.sprider_category = title_name # 一级目录self.folder_namesecond_folder_name = str(self.sprider_count) + "个" + self.folder_name #二级目录self.sprider_type =second_folder_nameself.merchant=int(self.sprider_start_count) //int(self.max_pager)+1 #起始页码用于效率采集#原始路径+一级目录+二级目录self.file_path = self.save_path + os.sep + self.sprider_top_level + os.sep + self.folder_name + os.sep + second_folder_nameself.save_path = self.save_path+ os.sep + self.sprider_top_level + os.sep+self.folder_name +os.sep + second_folder_name+ os.sep + self.folder_nameBaseFrame().debug("开始采集ChinaZJL"+self.folder_name+"...")sprider_url = (self.base_url + "/{1}/{0}.html".format(self.second_column_name,self.first_column_name))down_path="D:\\Freedom\\Sprider\\ChinaZ\\"+self.sprider_top_level +"\\"+self.folder_name +"\\"+second_folder_name+"\\Temp\\"if os.path.exists(down_path) is True:shutil.rmtree(down_path)if os.path.exists(down_path) is False:os.makedirs(down_path)if os.path.exists(self.save_path ) is True:shutil.rmtree(self.save_path )if os.path.exists(self.save_path ) is False:os.makedirs(self.save_path )chrome_options = webdriver.ChromeOptions()diy_prefs ={'profile.default_content_settings.popups': 0,'download.default_directory':'{0}'.format(down_path)}# 添加路径到selenium配置中chrome_options.add_experimental_option('prefs', diy_prefs)chrome_options.add_argument('--headless') #隐藏浏览器# 实例化chrome浏览器时,关联忽略证书错误driver = webdriver.Chrome(options=chrome_options)driver.set_window_size(1280, 800) # 分辨率 1280*800#BaseFrame().debug("开始采集"+sprider_url)driver.get(sprider_url)# content = driver.page_sourceelement_list = driver.find_elements(By.CLASS_NAME, "masonry-brick") # 列表页面 核心内容 box col3 ws_block masonry-brick#element_list = div_elem.find_elements(By.CLASS_NAME, 'item')#print(element_list.get_attribute('innerHTML'))laster_pager_div = driver.find_element(By.CLASS_NAME, "fenye")laster_pager_a = laster_pager_div.find_elements(By.TAG_NAME, 'a')laster_pager_url = laster_pager_a[len(laster_pager_a) - 2]page_end_number = int(laster_pager_url.text)self.page_count=self.merchantwhile self.page_count <= int(page_end_number): # 翻完停止try:if self.page_count == 1:self.sprider_detail(driver,element_list,self.page_count,page_end_number,down_path)passelse:if self.haved_sprider_count == self.sprider_count:BaseFrame().debug("采集到达数量采集停止...")BaseFrame().debug("开始写文章...")self.builder_word(self.folder_name, self.word_content_list)BaseFrame().debug("文件编写完毕,请到对应的磁盘查看word文件和下载文件!")break#(self.base_url + "/sort/{0}/{1}/".format(url_index, self.page_count))#http://soft.onlinedown.net/sort/177/2/#https://sc.chinaz.com//jianli/xiaochengchu_2.htmlnext_url = self.base_url + "/{2}/{0}_{1}.html".format(self.second_column_name, self.page_count,self.first_column_name)driver.get(next_url)element_list = driver.find_elements(By.CLASS_NAME, "masonry-brick") # 列表页面 核心内容self.sprider_detail( driver, element_list, self.page_count, page_end_number, down_path)pass#print(self.page_count)self.page_count = self.page_count + 1 # 页码增加1except Exception as e:print("sprider()执行过程出现错误:" + str(e))sleep(1)有机食品零售商城HTML5模板
网上花店电商网站HTML5模板
服装配饰电子商店网站模板
水果蔬菜采购网站模板
手机数码产品电商网站模板
服装穿戴商城网站模板
情趣内衣电商网站模板
蔬菜销售电子商务网站模板
综合生活类电商服务网站模板
有机食品购物商城网站模板
二手旧手机销售网站模板
时尚潮流服装网站模板
电子数码产品商城网站模板
卖水果网上商店网站模板
图片广告设计交易网站模板
无人机数码商店网站模板
家具店铺商城HTML5模板
shop购物网站模板
太阳镜网上商城页面模板
综合类购物商城网站模板
大气生活用品电商网站模板
有机蔬菜店铺HTML5模板
综合购物电子商务网站模板
时尚服装品牌网站模板
咖啡店铺电商网站模板
素材设计交易平台HTML5模板
冲击钻电钻商城网站模板
时尚女装B2B网站模板
自行车网上商城HTML5模板
多用途购物商城网站模板
折扣网上商店网站模板
海外购物商城HTML模板
电子产品优惠促销模板
服装店铺电商HTML5模板
时尚服装配饰电商网站模板
网上礼品商店HTML5模板
无人机购买商店HTML5模板
视频书籍购买网站模板
多用途网络购物平台模板
橙色大气网上商店网站模板
水果外卖超市网站模板
服装电子商务公司网站模板
网上书籍销售HTML5模板
女性化妆品电商网站模板
奢侈品珠宝店HTML模板
时尚男装T恤电商网站模板
蔬菜水果批发商网站模板
医疗物资器械商城模板
沙发家具销售网站模板
水果蔬菜销售HTML5模板
商品折扣促销网站模板
棕色风格钻戒交易网站模板
衣服搭配电商网站模板
数码电子产品销售电商模板
import osdef void_file(dirPath):dirs = os.listdir(dirPath) # 查找该层文件夹下所有的文件及文件夹,返回列表for file in dirs:file_full_name = dirPath + '/' + filefile_ext = os.path.splitext(file_full_name)[-1]if file_ext is None or file_ext=="":continueif "rar" == str(file_ext.split(".")[1]):os.remove(file_full_name)if "zip" == str(file_ext.split(".")[1]):os.remove(file_full_name)if "gz" == str(file_ext.split(".")[1]):os.remove(file_full_name)if "tgz" == str(file_ext.split(".")[1]):os.remove(file_full_name)# 查找指定文件夹下所有相同名称的文件
def search_file(dirPath, fileName):dirs = os.listdir(dirPath) # 查找该层文件夹下所有的文件及文件夹,返回列表for currentFile in dirs: # 遍历列表absPath = dirPath + '/' + currentFileif os.path.isdir(absPath): # 如果是目录则递归,继续查找该目录下的文件search_file(absPath, fileName)elif currentFile == fileName:print(absPath) # 文件存在,则打印该文件的绝对路径os.remove(absPath)网上产品销售商店HTML5模板
户外穿戴摄影商城模板
男士服装配饰商城网站模板
网上猪肉销售网站模板
电子商务销售商店网站模板
服装网上商店网站模板下载
时尚运动鞋购物网站模板
北欧风格家具商城网站模板
水果商店响应式网站模板
生活电器商城企业网站模板
绿色蔬菜网上超市网站模板
酒店旅游团预订网站模板
儿童商店HTML5网站模板
手机数码电子商店模板
手表电子产品商城模板

最后送大家一首诗:
山高路远坑深,
大军纵横驰奔,
谁敢横刀立马?
惟有点赞加关注大军。