怎么做五个页面网站竞价托管推广哪家好
文章目录
- LaWGPT:基于中文法律知识的大语言模型
- 数据构建
- 模型及训练步骤
- 两个阶段
- 二次训练流程
- 指令精调步骤
- 计算资源
- 项目结构
- 模型部署及推理
- LawGPT_zh:中文法律大模型(獬豸)
- 数据构建
- 知识问答
- 模型推理
- 训练步骤
LaWGPT:基于中文法律知识的大语言模型
LaWGPT是2023年5月13日发布的一系列基于中文法律知识的开源大语言模型。
该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力。
github地址:https://github.com/pengxiao-song/LaWGPT/tree/main
数据构建
本项目基于中文裁判文书网公开法律文书数据、司法考试数据等数据集展开,详情参考中文法律数据源汇总(Awesome Chinese Legal Resources)。
- 初级数据生成:根据 Stanford_alpaca 和 self-instruct 方式生成对话问答数据
- 知识引导的数据生成:通过 Knowledge-based Self-Instruct 方式基于中文法律结构化知识生成数据。
- 引入 ChatGPT 清洗数据,辅助构造高质量数据集。
模型及训练步骤
2023/04/12,内部测试模型:
LaWGPT-7B-alpha:在 Chinese-LLaMA-7B 的基础上直接构造 30w 法律问答数据集指令精调;
2023/05/13,公开发布两个模型:
Legal-Base-7B:法律基座模型,使用 50w 中文裁判文书数据并基于 Chinese-LLaMA-7B 模型二次预训练后得到的模型,Legal-Base-7b模型(无需合并)下载地址:
https://huggingface.co/yusp998/legal_base-7b
https://hf-mirror.com/yusp998/legal_base-7b
LaWGPT-7B-beta1.0:法律对话模型,构造 30w 高质量法律问答数据集基于 Legal-Base-7B 指令精调后的模型
2023/05/30:公开发布一个模型
LaWGPT-7B-beta1.1:法律对话模型,构造 35w 高质量法律问答数据集,基于 Chinese-alpaca-plus-7B 指令精调后的模型。
两个阶段
LawGPT 系列模型的训练过程分为两个阶段:
第一阶段:扩充法律领域词表,在大规模法律文书及法典数据上预训练 Chinese-LLaMA
第二阶段:构造法律领域对话问答数据集,在预训练模型基础上指令精调
二次训练流程
参考 resources/example_instruction_train.json 构造二次训练数据集
运行 scripts/train_clm.sh
指令精调步骤
参考 resources/example_instruction_tune.json 构造指令微调数据集
运行 scripts/finetune.sh
计算资源
8 张 Tesla V100-SXM2-32GB :二次训练阶段耗时约 24h / epoch,微调阶段耗时约 12h / epoch
由于 LLaMA 和 Chinese-LLaMA 没有开源模型权重。根据相应开源许可,本项目只能发布 LoRA 权重,无法发布完整的模型权重。
项目结构
LaWGPT
├── assets # 静态资源
├── resources # 项目资源
├── models # 基座模型及 lora 权重
│ ├── base_models
│ └── lora_weights
├── outputs # 指令微调的输出权重
├── data # 实验数据
├── scripts # 脚本目录
│ ├── finetune.sh # 指令微调脚本
│ └── webui.sh # 启动服务脚本
├── templates # prompt 模板
├── tools # 工具包
├── utils
├── train_clm.py # 二次训练
├── finetune.py # 指令微调
├── webui.py # 启动服务
├── README.md
└── requirements.txt
模型部署及推理
-
准备代码,创建环境
# 下载代码 git clone git@github.com:pengxiao-song/LaWGPT.git cd LaWGPT# 创建环境 conda create -n lawgpt python=3.10 -y conda activate lawgpt pip install -r requirements.txt
启动 web ui(可选,易于调节参数)
- 首先,执行服务启动脚本:
bash scripts/webui.sh - 其次,访问 http://127.0.0.1:7860 :
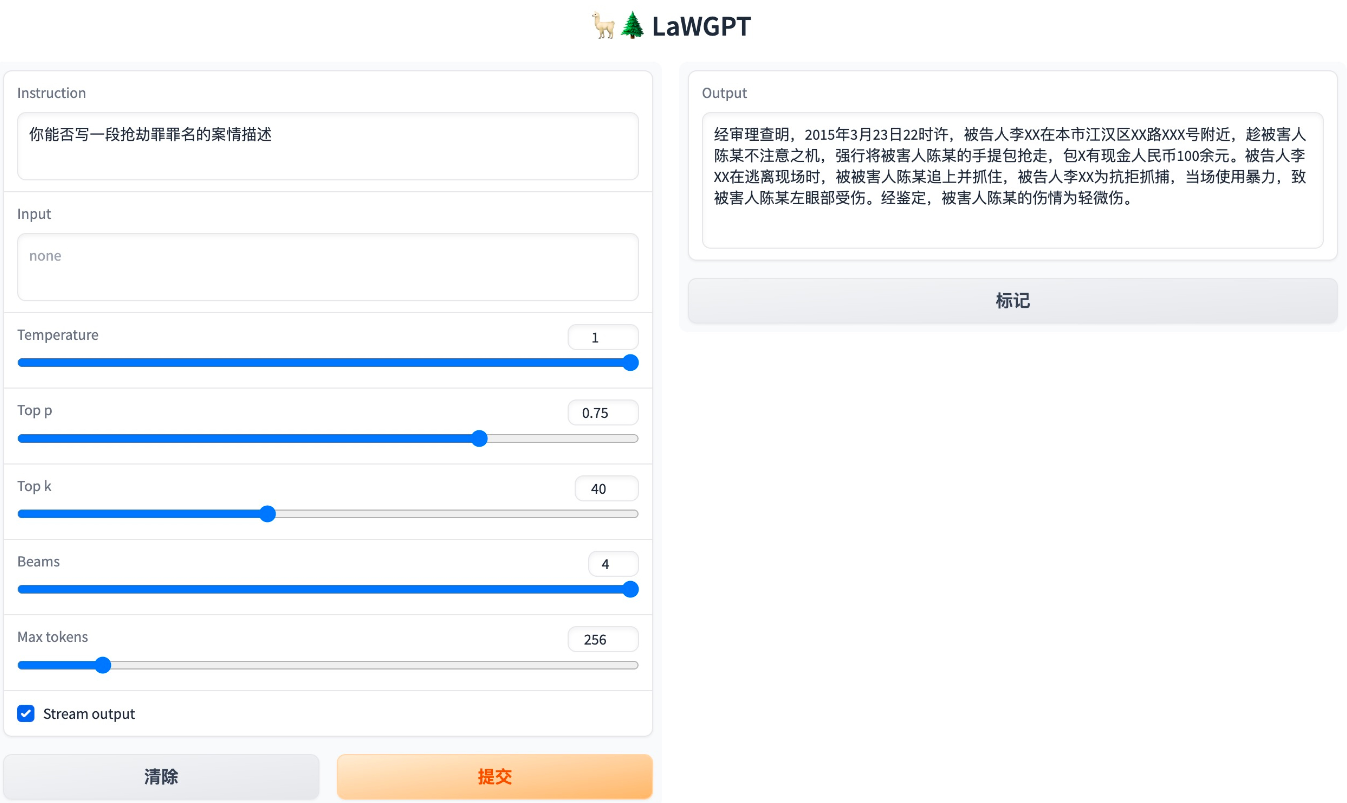
命令行推理(可选,支持批量测试)
首先,参考 resources/example_infer_data.json 文件内容构造测试样本集;
其次,执行推理脚本:bash scripts/infer.sh。其中 --infer_data_path 参数为测试样本集路径,如果为空或者路径出错,则以交互模式运行。
注意,以上步骤的默认模型为 LaWGPT-7B-alpha ,如果您想使用 LaWGPT-7B-beta1.0 模型,则通过以下三个步骤获取:
1. 获取 Chinese-LLaMA-7B 原版模型权重
首先,需要获得 Chinese-LLaMA-7B 的原版模型权重。以下是一些可供参考的获取方式:
- 手动合并:根据 Chinese-LLaMA 官方文档 提供的合并步骤,手动合并模型权重
- 检索下载:在 Hugging Face 官网:模型检索
将模型权重文件夹移动至 models/base_models 目录下,如 models/base_models/chinese-llama-7b-merged
2. 获取 legal-lora-7b 模型权重
下载 legal-lora-7b 模型权重,
将模型权重文件夹移动至 models/lora_weights 目录下,如 models/lora_weights/legal-lora-7b
3. 运行合并脚本
最后,合并原版 Chinese-LLaMA-7B 模型权重和二次训练到的 legal-lora-7b 权重:
sh scripts/merge.sh
LawGPT_zh:中文法律大模型(獬豸)
LawGPT_zh模型由上海交通大学科研团队通过ChatGLM-6B LoRA 16-bit 指令微调得到中文法律大模型。数据集包括现有的法律问答数据集和基于法条和真实案例指导的self-Instruct构建的高质量法律文本问答数据集,提高了通用语言大模型在法律领域的表现,提高了模型回答的可靠性和专业程度。
github地址:
数据构建
数据主要分为两个部分:
- 律师和用户之间的情景对话
- 对特定法律知识的问答
| 数据类型 | 描述 | 数量 | 占比(%) |
|---|---|---|---|
| 情景对话 | 真实的律师用户问答 | 200k | 100 |
| 知识问答 | 法律知识问题的解释性回答 | coming soon | 0 |
| 总计 | - | 200k | 100 |
情景对话数据
真实的中文律师用户问答数据,来自CrimeKgAssitant 收集的200k条情景对话数据,该数据集来自刘焕勇老师的开源项目。
question:朋友欠钱不还咋办
answers: ['欠款金额是多少 ', '多少钱呢', '律师费诉讼费都非常少都很合理,一定要起诉。', '大概金额多少?', '需要看标的额和案情复杂程度,建议细致面谈']
*******************************************************
question:昨天把人家车刮了,要赔多少
answers: ['您好,建议协商处理,如果对方告了你们,就只能积极应诉了。', '您好,建议尽量协商处理,协商不成可起诉']
*******************************************************
question:最近丈夫经常家暴,我受不了了
answers: ['报警要求追究刑事责任。', '您好,建议起诉离婚并请求补偿。', '你好!可以起诉离婚,并主张精神损害赔偿。']
*******************************************************
question:毕业生拿了户口就跑路可以吗
answers: 您好,对于此类问题,您可以咨询公安部门
*******************************************************
question:孩子离家出走,怎么找回来
answers: ['孩子父母没有结婚,孩子母亲把孩子带走了?这样的话可以起诉要求抚养权的。毕竟母亲也是孩子的合法监护人,报警警察一般不受理。']
*******************************************************
利用ChatGPT清洗CrimeKgAssitant数据集得到52k单轮问答数据
下载(提取码:MYTT)
利用ChatGPT根据CrimeKgAssitant的问答重新生成,使得生成的回答比原回答更详细,语言组织更规范。
带有法律依据的情景问答92k
下载(提取码:MYTT)
根据中华人民共和国法律手册上最核心的9k法律条文,利用ChatGPT联想生成具体的情景问答,从而使得生成的数据集有具体的法律依据。数据格式如下
"question": "在某家公司中,一名员工对女同事实施了性骚扰行为,女同事向公司进行举报,但公司却没有采取必要的措施来制止这种行为。\n\n公司未采取必要措施预防和制止性骚扰,导致女同事的权益受到侵害,该公司是否需要承担责任?"
"answer": "根据《社会法-妇女权益保障法》第八十条规定,“学校、用人单位违反本法规定,未采取必要措施预防和制止性骚扰,造成妇女权益受到侵害或者社会影响恶劣的,由上级机关或者主管部门责令改正;拒不改正或者情节严重的,依法对直接负责的主管人员和其他直接责任人员给予处分。”因此,该公司因为未采取必要措施预防和制止性骚扰行为,应该承担责任,并依法接受相关的处分。女同事可以向上级机关或主管部门进行申诉,要求该公司被责令改正,并对相关负责人员给予处分。"
"reference": ["社会法-妇女权益保障法2022-10-30: \"第七十九条 违反本法第二十二条第二款规定,未履行报告义务的,依法对直接负责的主管人员和其他直接责任人员给予处分。\",\n","社会法-妇女权益保障法2022-10-30: \"第八十条 违反本法规定,对妇女实施性骚扰的,由公安机关给予批评教育或者出具告诫书,并由所在单位依法给予处分。\",\n","社会法-妇女权益保障法2022-10-30: \"学校、用人单位违反本法规定,未采取必要措施预防和制止性骚扰,造成妇女权益受到侵害或者社会影响恶劣的,由上级机关或者主管部门责令改正;拒不改正或者情节严重的,依法对直接负责的主管人员和其他直接责任人员给予处分。\",\n","社会法-妇女权益保障法2022-10-30: \"第八十一条 违反本法第二十六条规定,未履行报告等义务的,依法给予警告、责令停业整顿或者吊销营业执照、吊销相关许可证,并处一万元以上五万元以下罚款。\",\n"]
知识问答
收集法律领域的教科书,经典案例等数据,自建一个法律专业知识数据库。
知识问答数据集针对Self-Instruct的可靠性和安全性漏洞,使用了基于特定知识的Reliable-Self-Instruction:通过提供具体的法律知识文本,先让ChatGPT生成与该段法律知识内容与逻辑关系相关的若干问题,再通过“文本段-问题”对的方式让ChatGPT回答问题,从而使ChatGPT能够生成含有法律信息的回答,保证回答的准确性。
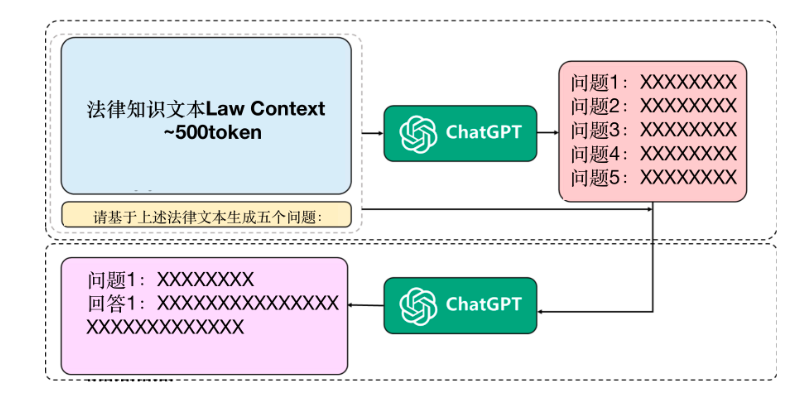
其中,计划法律知识数据包含民法商法、行政法、经济法、社会法、刑法等各个细分法律的条例,分析和题库。
模型推理
-
配置项目依赖环境
cd src pip install -r requirements.txt #其中peft需要本地安装 cd peft pip install -e . -
下载(提取码:fj9d)ChatGLM-6B模型参数(ChatGLM权重参数有变化,以及函数进行了修改,请下载全部文件),将其放入
./model目录下。 -
下载(提取码:ymor)检索模型参数,将其放入
./retriver目录下。 -
下载text2vec-base-chinese模型参数,将其放入
./text2vec-base-chinese目录下。 -
运行交互文件(要求单卡显存 >= 15G),输入new chat可以清空上下文信息
#demo.py为直接生成 CUDA_VISIBLE_DEVICES=$cuda_id python ./demo.py#demo_r.py加入了检索功能 CUDA_VISIBLE_DEVICES=$cuda_id python ./demo_r.py -
命令行交互界面实例
Human: 信用卡欠账不还后果很严重吗? ------------------------------------------------ Answer: 信用卡欠款如果不及时偿还,会对自己产生严重的影响。下面是一些可能的后果: 1.利息和罚款:如果未在规定时间内还款,则会开始收取滞纳金和利息,费用可能会非常高; 2.信用记录受损:逾期付款会影响个人的信用报告,使个人在未来申请贷款、购房和其他业务时面临困难; 3.银行起诉:若未能在指定时间内还清全额账单,可能会被银行起诉至法院要求归还债务并支付相应的诉讼费用; 4.法律风险:逾期付款可能会导致合同违约,构成违约则需要承担违约责任(包括赔偿损失); 5.失去使用信用卡的权利:如果发现自己的信用记录中存在多次逾期或其他不良记录,将会失去使用某些信用卡或贷款的机会。 因此,为了避免以上情况的发生,应合理规划好开支,按时按量偿还信用卡欠款。
训练步骤
- 下载训练数据集
- 配置好train_lora.py参数
- 运行train_lora.py函数(使用模型并行算法,请勿同时使用数据并行)
本项目训练代码采用模型并行算法,可以在最少4张3090显卡上完成对ChatGLM LoRA 16-bit的指令微调。训练命令如下
cd src
CUDA_VISIBLE_DEIVCES=$cuda_id python train.py \--title $YOUR_EXP_NAME \--train_path $YOUR_TRAINING_DATA_PATH \--save_dir $YOUR_LORA_CHECKPOINT_SAVE_PATH