屯留网站建设太原搜索引擎优化
最近这一两周看到不少互联网公司都已经开始秋招提前批了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
《大模型面试宝典》(2024版) 正式发布!
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们
技术交流

在人工智能领域,垂直领域的挑战不断催生新的技术解决方案。RAG是一种结合检索和生成的深度学习模型,它通过检索大量相关文档,然后基于这些文档生成回答,从而提高回答的准确性和相关性。
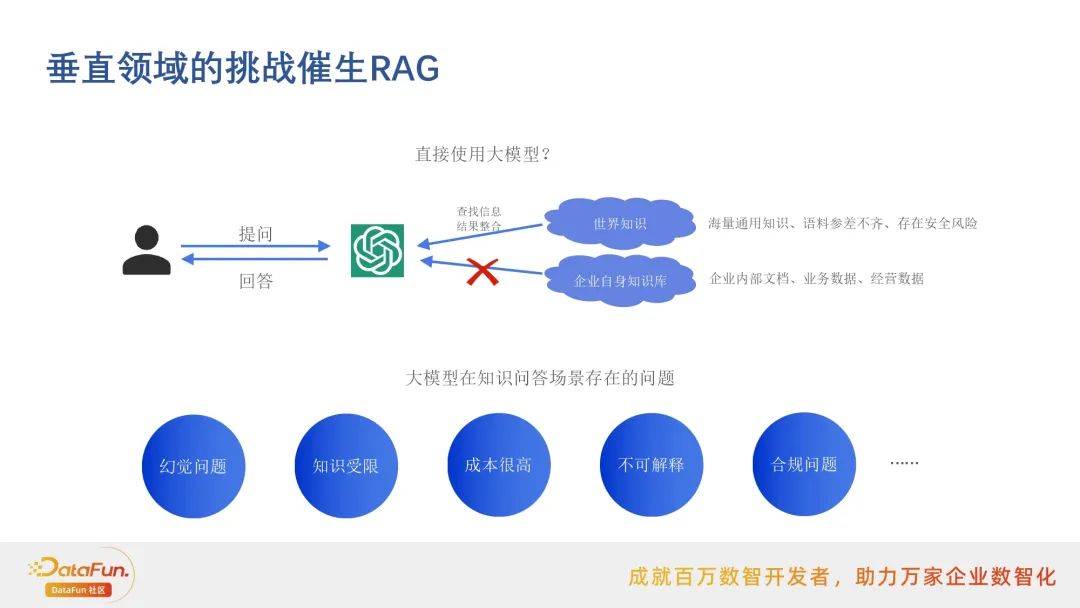
然而,直接使用大型预训练模型来应对这些挑战并非没有问题。
-
模型通常依赖于海量的通用知识库和语料,这些资源的质量参差不齐,且可能存在安全风险。
-
在知识问答场景中,大模型可能会遇到幻觉问题,即生成看似合理但实际错误的答案。
-
模型的知识受限,难以完全覆盖特定领域的专业知识,同时其生成过程的不可解释性也引发了合规问题。
为了解决这些问题,许多企业开始转向利用自身的知识库。企业内部的文档、业务数据和经营数据是宝贵的资源,它们提供了更准确、更安全的知识来源。通过将这些内部数据与RAG模型相结合,企业可以生成更符合自身需求和标准的高质量回答。
RAG 技术方案
Retrieval-Augmented Generation(RAG)是一种先进的人工智能技术,它通过将检索结果与大型语言模型(LLM)结合,引导模型生成更加精准和可靠的答案。RAG的核心在于其能够实时更新知识库,而无需对模型进行重新训练,这大大提升了知识获取的时效性和灵活性。

RAG的三大优势
-
实时更新知识库:RAG能够动态地从最新的数据源中获取信息,确保知识库的持续更新,而无需进行耗时的模型重训练。
-
可追溯的答案来源:与传统的黑盒模型不同,RAG生成的答案可以追溯到其知识库中的原始来源,提高了答案的可解释性和可追踪性。
-
减少幻觉问题:由于RAG生成的答案基于结构化和验证过的知识库,因此相较于完全依赖模型内部知识的情况,它更不容易产生幻觉问题。
RAG关键点解析

高准确度场景
在某些关键场景中,如医疗咨询或法律服务,对答案的准确度要求极高,几乎需要达到“100%准确”。为此,RAG技术需要做到:
-
准确解析不同格式文档:无论是PDF、Word还是其他格式,RAG都应能够准确解析文档内容。
-
准确召回问题相关结果:RAG应能迅速从知识库中检索并召回与问题紧密相关的信息。
-
低幻觉率的大模型总结:生成的答案应基于可靠的数据源,减少错误信息的产生。
实时答案生成
在快节奏的查询环境中,用户期望在1到3秒内获得答案。这要求RAG技术具备:
-
高性能召回问题相关结果:快速从大量数据中检索出最相关的信息。
-
高性能大模型推理生成:模型需要在极短的时间内完成对信息的推理和生成过程。
训练与推理成本
RAG技术的一个主要成本是GPU资源的消耗,特别是在训练和推理阶段。为了降低成本,需要:
-
低成本训练方法:探索更经济的训练策略,以减少对GPU资源的依赖。
-
大模型推理加速:优化模型结构和算法,提高推理速度,降低成本。
隐私与安全性
在处理用户数据时,RAG技术必须严格遵守隐私和安全性的要求:
-
过滤敏感话题:确保模型在生成内容时能够识别并过滤掉敏感话题。
-
遵守相关法律法规:在不同地区运营时,需遵循当地的数据保护法规。
-
可控的大模型生成:通过设置合理的约束条件,控制模型生成的内容,避免违规风险。
RAG效果优化
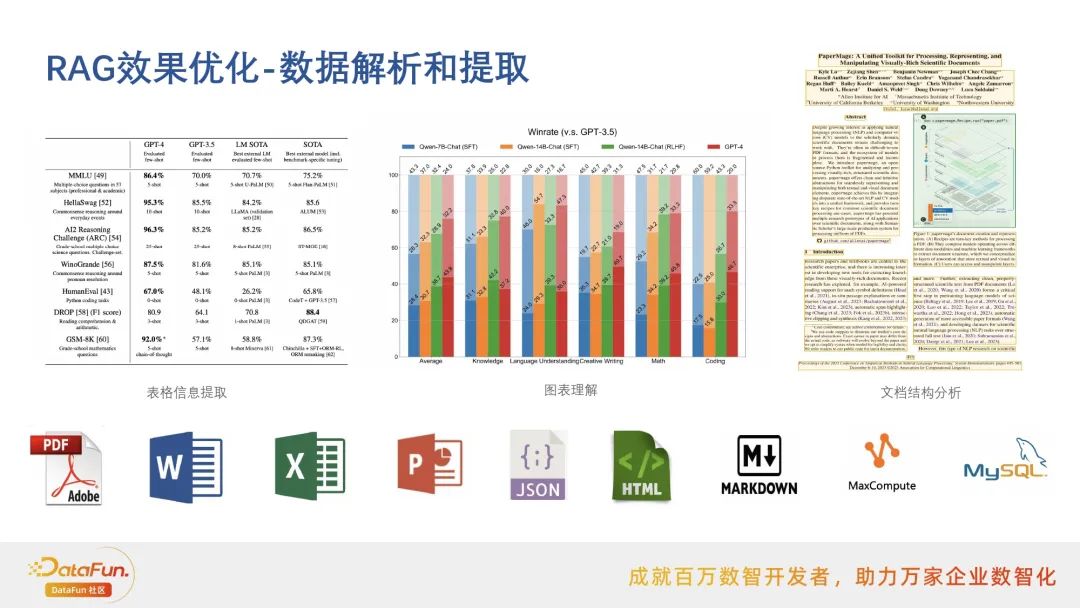
数据解析和提取
-
表格信息提取:能够识别和解析文档中的表格数据,将其转换为结构化信息,便于模型理解和利用。
-
图表理解:对图表中的图形、趋势和数据点进行分析,提取关键信息,帮助模型理解图表所传达的内容。
-
文档结构分析:识别文档中的结构元素,如标题、段落、列表等,为文本切片和信息检索提供基础。
文本切片
文本切片是将文档分割成更小的、易于处理和检索的部分。以下是几种不同的切片方法:
-
层次切片:根据文档的层次结构进行切片,例如将一级标题和其下的段落作为一个切片单元。
-
多粒度切片:结合不同粒度的信息,如将一级标题、二级标题和相关段落组合在一起,以提供更丰富的上下文。
-
细切片:进一步细化切片,可能包括单个句子或短语,以捕获更具体的信息。

多语言向量化模型方法

Query理解

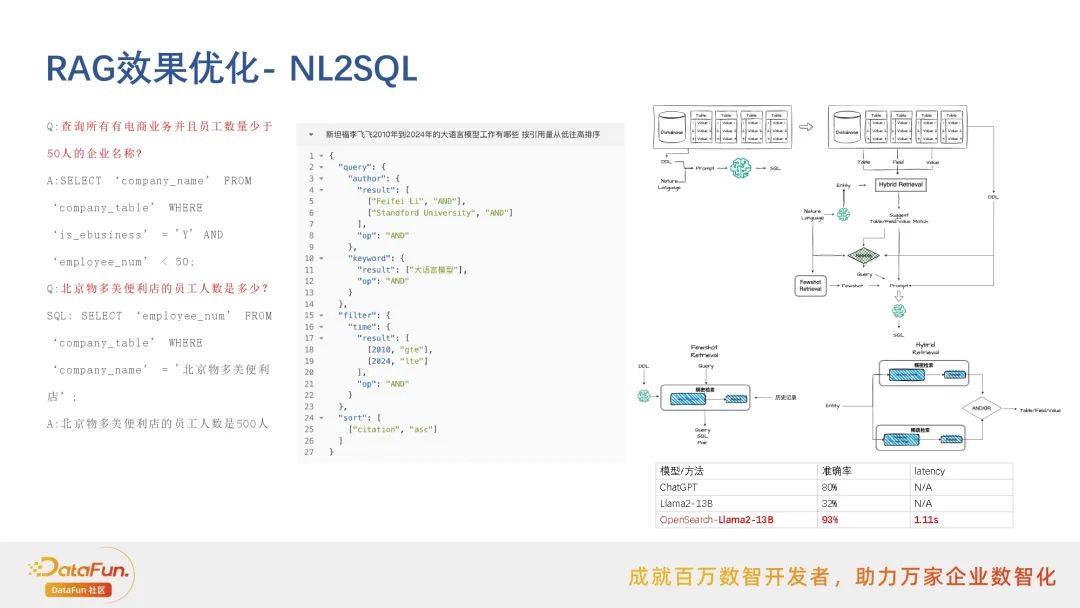
NL2SQL
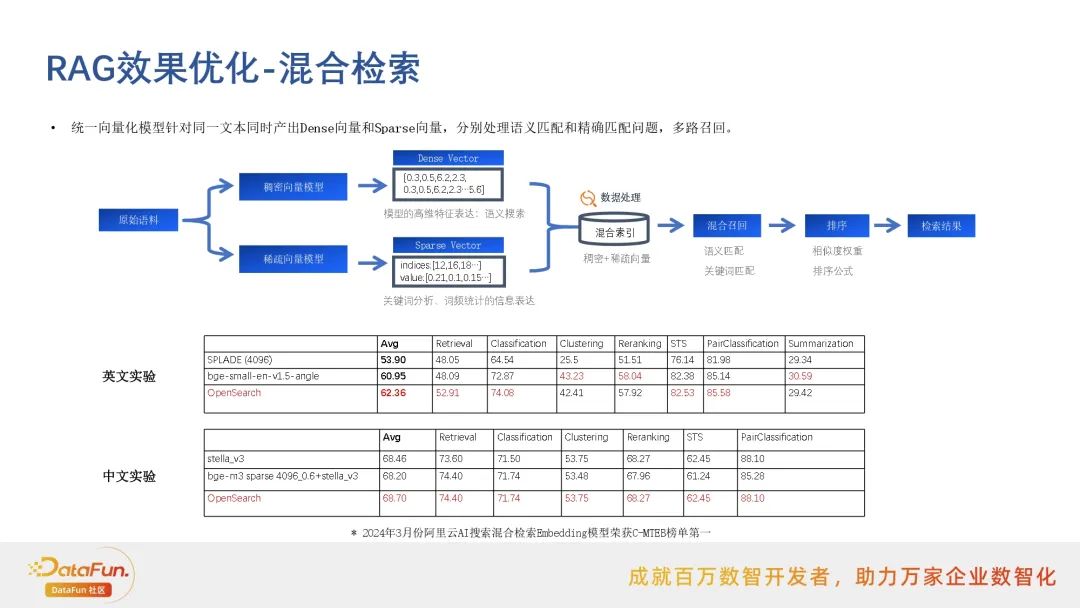
混合检索
Rerank

大模型微调和评测

RAG性能优化- VectorStore CPU图算法
在RAG中,VectorStore扮演着关键角色,它用于存储和检索向量化的数据。HNSW是一种用于高效近似最近邻搜索的图算法。它构建了一个分层的图结构,每一层都具有不同的搜索精度和效率。

RAG性能优化- 大模型推理加速

RAG成本优化-方法选择

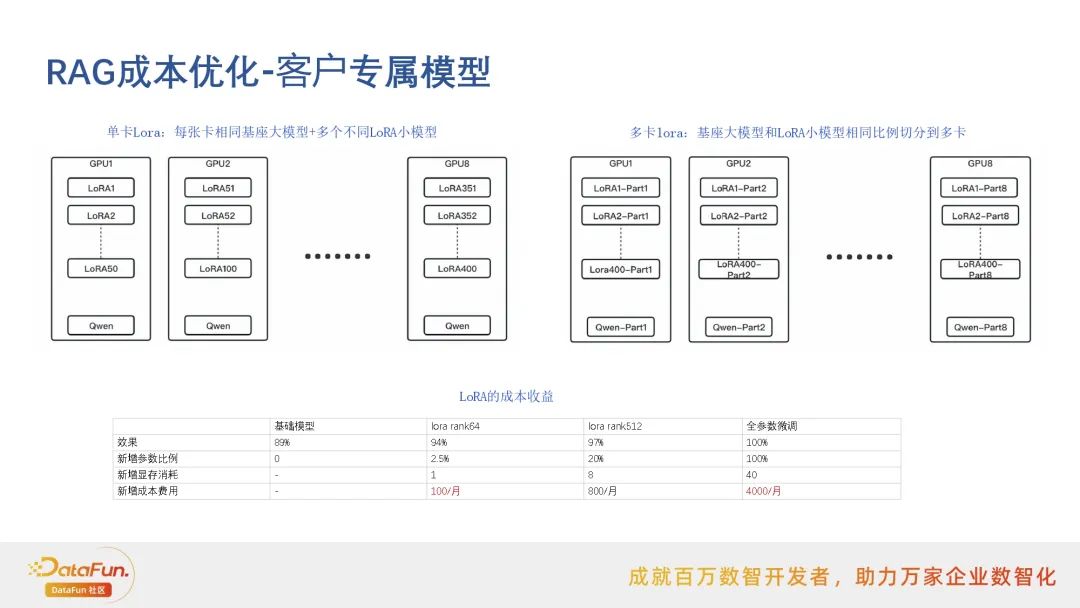
RAG成本优化-客户专属模型
RAG典型场景


多模态RAG
