崇文企业网站建设公司微信营销的案例
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——NLP实战(自然语言推断——注意力机制实现)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
在上一节使用了注意力机制来实现自然语言推断模型,后面会给出更好的实现方式,也就是利用微调BERT来进行实现,而自然语言推断模型是针对序列级的模型,在这里先分别针对序列级和词元级的问题,讲解如何应用微调BERT。
针对序列级和词元级应用微调BERT
- 引入
- 序列级任务
- 单文本分类
- 文本对分类或回归
- 词元级任务
- 文本标注
- 问答
- 小结
引入
在之前,我们分别为自然语言处理的应用设计了几个模型,包括基于RNN、CNN、注意力和多层感知机。这些模型在有空间或时间限制的情况下是有帮助的,但是,为每个自然语言处理任务精心设计一个特定的模型实际上是不可行的。在之前,已经讲解过了BERT的预训练模型,该模型可以对广泛的自然语言处理任务进行最少的架构更改。一方面,在提出时,BERT改进了各种自然语言处理任务的技术水平。另一方面,原始BERT模型的两个版本分别带有1.1亿和3.4亿个参数。因此,当有足够计算资源时,我们可以考虑为下游自然语言处理应用微调BERT。
下面,我们将自然语言处理应用的子集概括为序列级和词元级。在序列层次上,介绍了在单文本分类任务和文本对分类(或回归)任务中,如何将文本输入的BERT表示转换为输出标签。在词元级别,我们将简要介绍新应用,如文本标注和问答,并说明BERT如何表示它们的输入并转换为输出标签。在微调期间,不同应用之间的BERT所需的“最小架构更改”是额外的全连接层。在下游应用的监督学习期间,额外层的参数是从零开始学习的,而预训练BERT模型中的所有参数都是微调的。
序列级任务
单文本分类
单文本分类将单个文本序列作为输入,并输出其分类结果,之前的情感分析就是单文本分类问题。
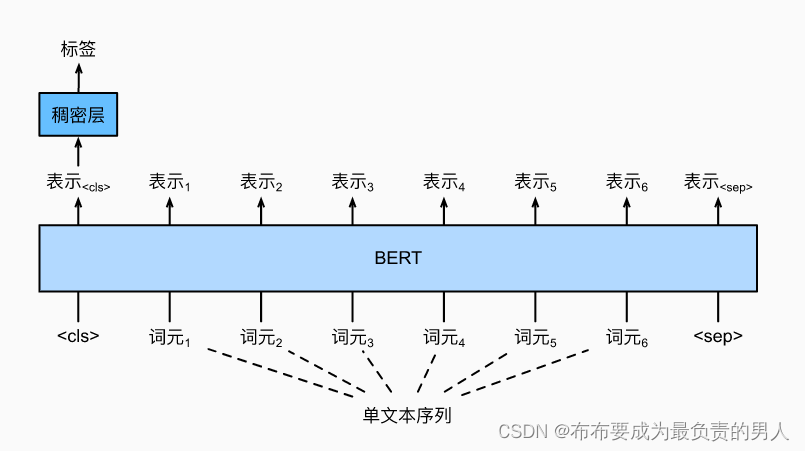
BERT的输入序列明确表示了是单个文本还是文本对,其中特殊分类标记“<cls>”用于序列分类,而特殊分类标记“<sep>”标记单个文本的结束或分隔成对文本。如上图所示,在单文本分类应用中,特殊分类标记“<cls>”的BERT表示对整个输入文本序列的信息进行编码。作为输入单个文本的表示,它将被送入到由全连接(稠密)层组成的小多层感知机中,以输出所有离散标签值的分布。
文本对分类或回归
上一节中的自然语言推断就是文本对分类问题,除此之外还有语义文本相似度问题,以一对文本作为输入但输出连续值,数据集中句子对的相似度得分时0(无语义重叠)到5(语义等价)的分数区间。我们的目标就是预测这些分数。
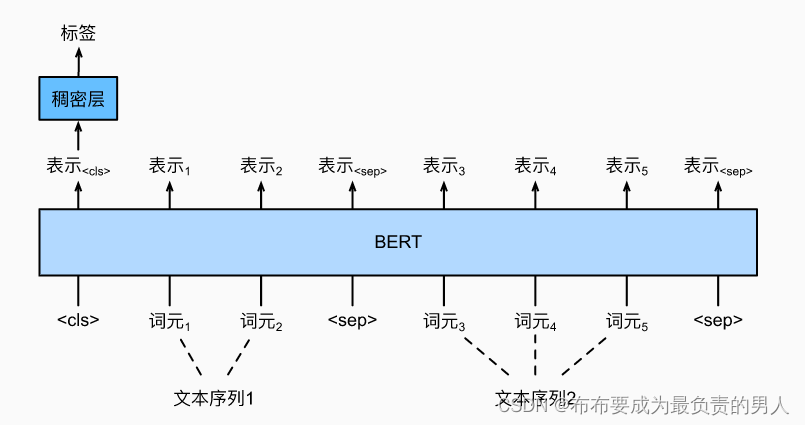
与单文本分类相比,文本对分类的微调BERT在输入表示上有所不同。对于文本对回归任务(如语义文本相似性),可以应用细微的更改,例如输出连续的标签值和使用均方损失(回归问题中很常见)。
词元级任务
文本标注
文本标注中每个词元都被分配了一个标签。在文本标注任务中,词性标注为每个单词分配词性标记(例如,形容词和限定词)。

与单文本分类相比,文本标注的输入文本的每个词元的BERT表示被送到相同的额外全连接层中,以输出词元的标签,例如词性标签。
问答
作为另一个词元级应用,问答反映阅读理解能力。例如,斯坦福问答数据集SQuAD v1.1的目标是在给定问题和段落的情况下预测段落中文本片段的开始和结束。
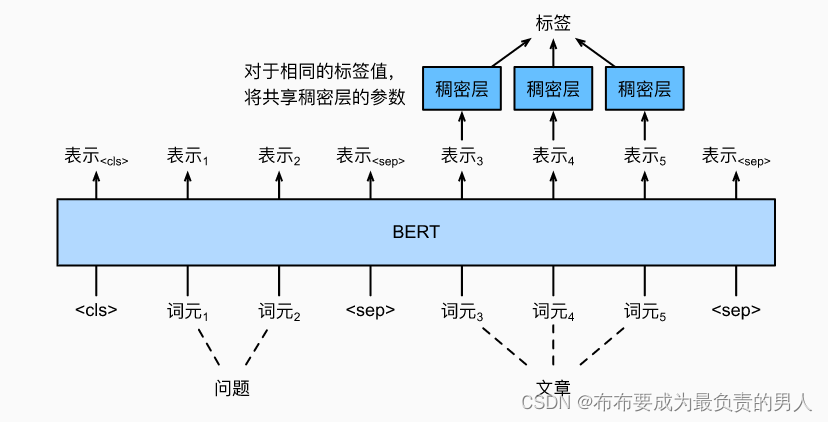
为了微调BERT进行问答,在BERT的输入中,将问题和文章分别作为第一个和第二个文本序列。
为了预测文本片段开始的位置,相同的额外的全连接层将把来自位置的任何词元的BERT表示转换成标量分数si。文章中所有词元的分数还通过softmax转换成概率分布,从而为文章中的每个词元位置i分配作为文本片段开始的概率pi。预测文本片段的结束与上面相同,只是其额外的全连接层中的参数与用于预测开始位置的参数无关。
当预测结束时,位置i的词元由相同的全连接层变换成标量分数ei。
对于问答,监督学习的训练目标就像最大化真实值的开始和结束位置的对数似然一样简单。当预测片段时,我们可以计算从位置i到位置j的有效片段的分数si+ei,并输出分数最高的跨度。
小结
1、对于序列级和词元级自然语言处理应用,BERT只需要最小的架构改变(额外的全连接层),如单个文本分类(例如,情感分析和测试语言可接受性)、文本对分类或回归(例如,自然语言推断和语义文本相似性)、文本标记(例如,词性标记)和问答。
2、在下游应用的监督学习期间,额外层的参数是从零开始学习的,而预训练BERT模型中的所有参数都是微调的。