网站建设与依法行政网络营销的功能有哪些?
联结
SQL最强大的功能之一就是能在数据检索查询的执行中联结表;
关系表
为什么要使用关系表?
- 使用关系表可以储存数据不重复,从而不浪费时间和空间;
- 如果有数据信息变动,只需更新一个表中的单个记录,相关表中的数据不用改动;
- 由于数据无重复,显然数据是一致的,这使得处理数据更简单。
总之,关系表可以有效低存储和方便的处理,因此,关系数据库的可伸缩性远比非关系数据库要好。
可伸缩性:能够适应不断增加的工作量而不失败。涉及良好的数据库或应用程序称之为可伸缩性好;

这是一个例子,他找出了群号为49289306112的群里面的所有群聊成员;
在使用联结查询的时候,一定要有where语句,如果没有的话就会输出巨多的没用的数据,有了where语句还不行,还要保证where语句的准确性,如果你的where语句不准确的话,不正确的过滤条件将导致MySQL返回不正确的数据;
除了上面的语法,还有一种写法,能够实现一样的功能;

这里与前面的区别就是FROM子句不同,这里,两个表之间的关系是from子句的组成部分,以INNER JOIN指定。在使用这种语法时,联结条件用特定的ON子句而不是WHERE子句给出。传递ON的实际条件与传递给WHERE的相同。
至于这两种语法选择哪一种,ANSI SQL规范首选INNER JOIN语法,此外,尽管使用WHERE子句定义联结的确比较简单,但是使用明确的联结语法能够确保不会忘记联结条件,有时候这样做也能影响性能;
联结多个表
SQL对一条SELECT语句中可以联结的表的数目没有限制。创建联结的基本规则也相同,都是先列出所有表,然后定义表之间的关系;
性能考虑:MySQL在运行时对联结表的处理时非常的耗费资源的,因此不要联结不必要的表,联结的表越多,性能下降越厉害。
在之前的学习中我们学习了子查询,子查询和联结都能达到目的,但是他们两个不是说哪个一定好,这个要看情况而定;
创建高级联结
之前学习的AS可以为列创建别名,但是其实AS也能够给表建立别名;
注意:表别名只在查询执行中使用。与列别名不一样,表别名不返回到客户机。
联结使用的某些要点
- 注意所使用的联结类型,一般我们使用内部联结,但使用外部联结也是有效的。
- 保证使用正确的联结条件,否则会返回不正确的数据。
- 应该总是提取联结条件,否者会得出迪卡尔积。(两个表的所有组合情况,大量数据)
- 在一个联结中可以包含多个表,甚至对于每个联结可以采用不同的联结类型。虽然这样做是合法的,一般也很有用,但是应该在一起测试它们之前,分别测试每个联结。这样可以使得故障排除更为简单。
组合查询
组合查询就是利用UNION操作符将多条select语句组合成一个结果集
在下面两个基本情况里面要用到组合查询:
- 在单个查询中从不同的表返回类似结构的数据;
- 对单个表执行多个查询,按单个查询返回数据;
在写qq聊天室项目时,我用到了组合查询,因为在好友关系表里面A是B的好友,那么B也是A的好友,所以在查询时,我们即要查看自己在A时有多少个B好友,又要查找自己为B时有多少给A好友;

这个UNION就是查询了存款大于2000和年龄小于19的结果;
UNION使用规则:
- UNION必须由两条或者两条以上的select语句组成,语句之间用关键字UNION分隔(因此,如果组合四条select语句,就要使用3个UNION语句)。
- UNION的每个查询必须包含相同的列,表达式或者聚集函数(不过各个列不需要以相同的次序列出)
- 列数据类型必须兼容;类型不必完全相同,但必须时DBMS可以隐含的转换的类型(例如:不同的数值或不同的日期类型)。
小细节:
使用UNION时,它会默认将多条select语句查询到的重复的行去重,所以在使用UNION时,重复的行会被去除,但是我们需要的话,也可以使用UNION ALL来获得所有的匹配行;

当我们想要对组合查询结果进行排序的时候,只能使用一条ORDER BY子句,它必须出现在最后一条select语句之后,对于结果集,不存在用一种方式排序一部分,而又用另一种方式排序宁一部分的情况,因此不允许使用多条ORDER BY语句;
上面的例子中的组合查询使用的均是demo1表,但是UNION可以用于组合查询不同的表;

全文本搜索
并非所有的引擎都支持全文本搜索,两个最常用的引擎为MyISAM和InnoDB,前者支持全文本搜索,而后者不支持。
在之前我们学习了使用LIKE和通配符来搜索文本,还有REGEXP操作符后面加正则表达式来搜索行;虽然这些搜索机制很有用,但是存在几个重要的限制:
- 性能——通配符和正则表达式匹配通常要求MySQl尝试匹配表中所有行(而且这些搜索极少使用表索引)。因此,由于被搜索行数不断增加,这些搜索可能会非常耗时;
- 明确控制——使用通配符和正则表达式匹配,很难(而且并不总是能)明确地控制匹配什么和不匹配什么。例如,指定一个词必须匹配,一个词必须不匹配,而一个词仅在第一个词确实匹配的情况下才可以匹配或者才可以不匹配。
- 智能化的结果——虽然基于通配符和正则表达式的搜索提供了非常灵活的搜索,但是它们都不能提供一种智能化的选择结果的方法。例如,一个特殊值的搜索会返回包含该词的所有行,而不区分包含单个匹配的行和包含多个匹配的行(按照可能是更好的匹配来排列它们)。类似,一个特殊词的搜索将不会找出不包含该词但是包含其他相关词的行。
首先,我们先建一个表:
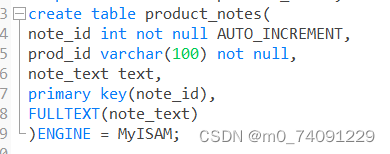
这里FULLTEXT(note_text) 表示将note_text设置为全文本查找的字段;
然后就是插入数据:

然后首先测试like模糊查询

查询结果分析:应为like模糊查询是在整个数据中查看有没有包含'fiction'这个单词的,如果有就过滤出来,而在我插入的数据中,1和5是有的;

然后再是全文本搜索

结果:
再测试全文本搜索-布尔文本搜索

在全文本搜索中常用的布尔运算符

结果:
使用扩展查询

这个会根据包含fiction的两条行中的数据中的其他单词来对其他行进行匹配,相当与找到了正确答案还要找与正确答案类似的答案;
结果:
全文本搜索-显示排名字段,按照匹配度由高到低排序

结果:
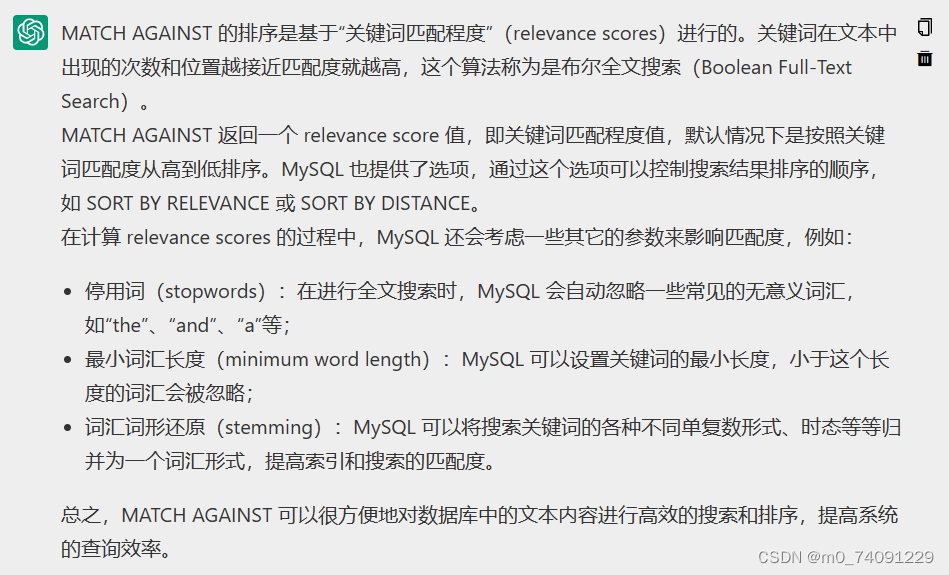
细节:Match( )和Against( )出现的位置对结果的影响较大,当Match( )和Against( )出现在where子句中时,只会返回匹配到的行,但是如果Match( )和Against( )出现在SELECT中的话,就会使得所有的行全部被返回,Match( )和Against( )用来建立一个计算列(别名为rank),此列包含全文本搜索计算出的等级值。等级由MySQL根据行中词的数目,唯一词的数目,整个索引中词的总数以及包含该词的行的数目计算出来,并且这个值还与唯一词所处的位置有关,唯一词靠前的值较高,靠后的值较低。