建网站前期设计用那软件武汉软件测试培训机构排名
1.dolphinscheduler的安装部署
dolphinscheduler服务的安装部署都是非常简单的,因为就服务本身而言依赖的服务并不多。
- mysql / postgresql。由于需要进行元数据及业务数据的持久化存储所以需要依赖于数据库服务,数据库服务支持mysql、postgresql等, 需要先安装好数据库服务。
- zookeeper。同时dolphinscheduler的服务注册、发现、分布式协调调度默认采用的是Zookeeper服务继续宁实现的,所以在安装服务之前需要先安装好zokeeper服务。
详细的安装部署文档可以参考我另外一篇博客:dolphinscheduler分布式集群部署指南(小白版)
今天我们不说不提安装部署, 我们今天来分析一下整个dolphinscheduler服务一键安装启动的流程实现, 为什么简单配置之后就可以把服务一键安装到服务器集群上, 然后通过一个start-all.sh脚本以及stop-all.sh脚本就可以控制集群服务的启停。
2.dolphinscheduler框架的核心原理

- API 服务:提供外部访问接口,用户通过它进行工作流管理、任务编排、调度和查询等操作。
- Master 服务:负责任务调度、分配和监控工作流的执行,协调整个系统的任务执行。
- Worker 服务:具体任务的执行者(真正的牛马),支持多种任务执行,并将任务执行结果反馈给 Master 服务。
- Alert 服务:监控系统的健康状态,并在出现异常时发出通知警报,确保系统运行的稳定性和及时处理故障。
3.dolphinscheduler的一键安装启动实现
3.1.dolphinscheduler部署包目录结构
我们从官网下载或者自己本地编译打包之后的发布包基本结构如下图:
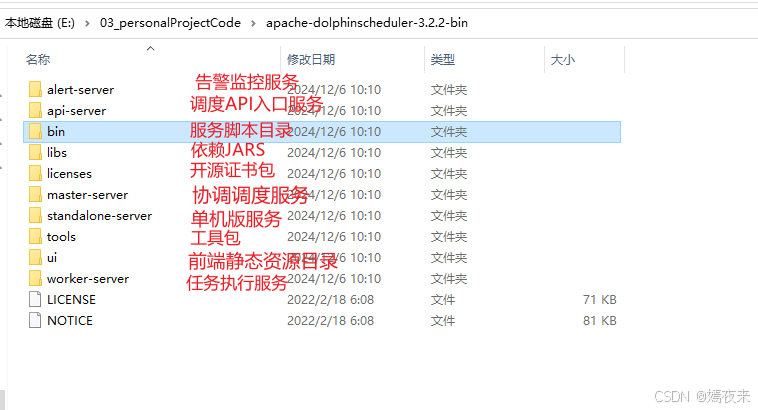
在3.2.2版本之前,项目一直都是提供一键安装脚本的, 但是在3.2.2版本之后,好像就没有这个install.sh脚本, 不知道是不是社区有意取消的, 有兴趣的童鞋可以去社区群里面咨询一下,我个人觉得有没有倒不是特别重要,当然有更好。
3.2.2之前的版本,如下图:
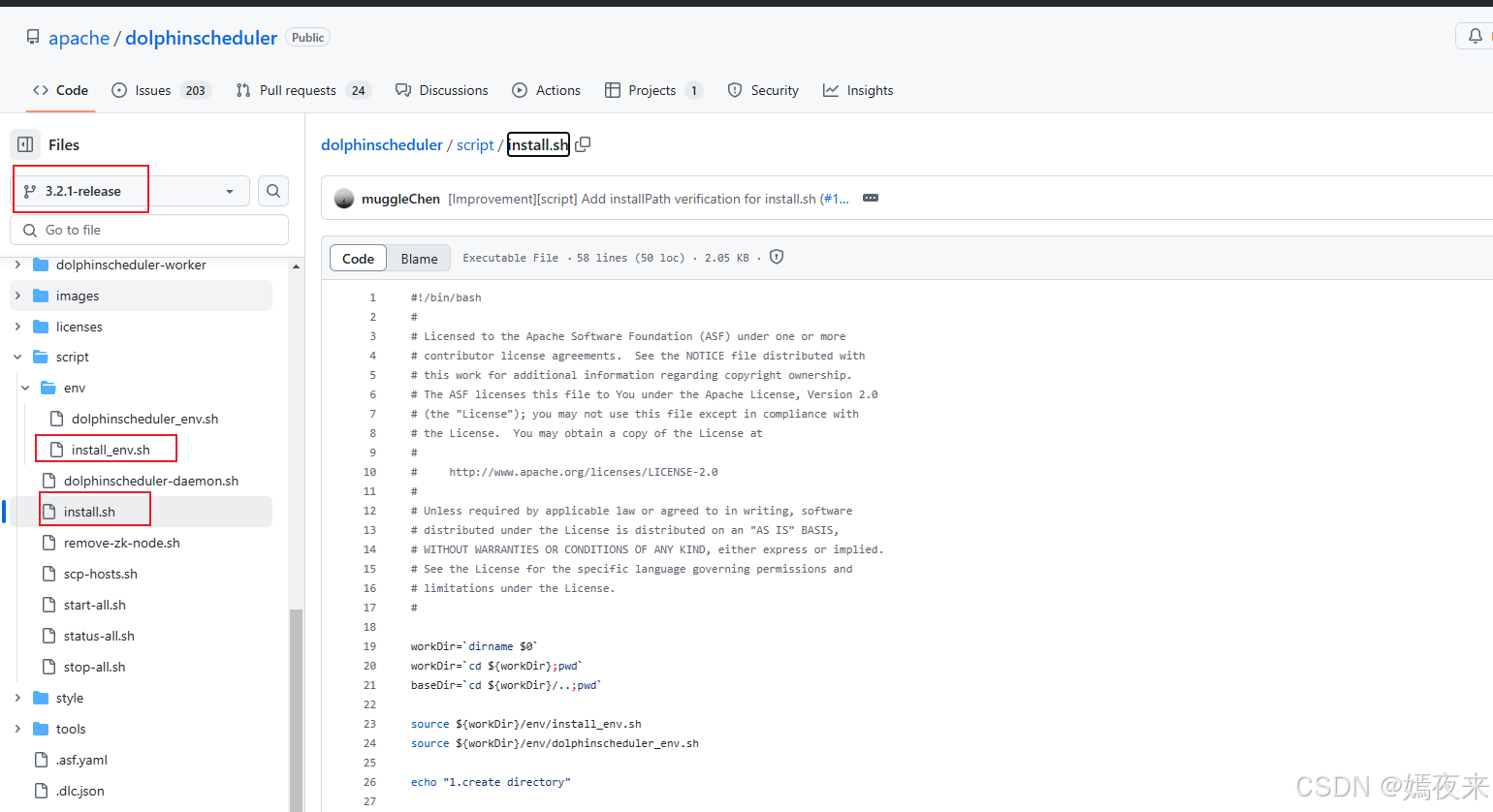
3.2.2版本,如下图:
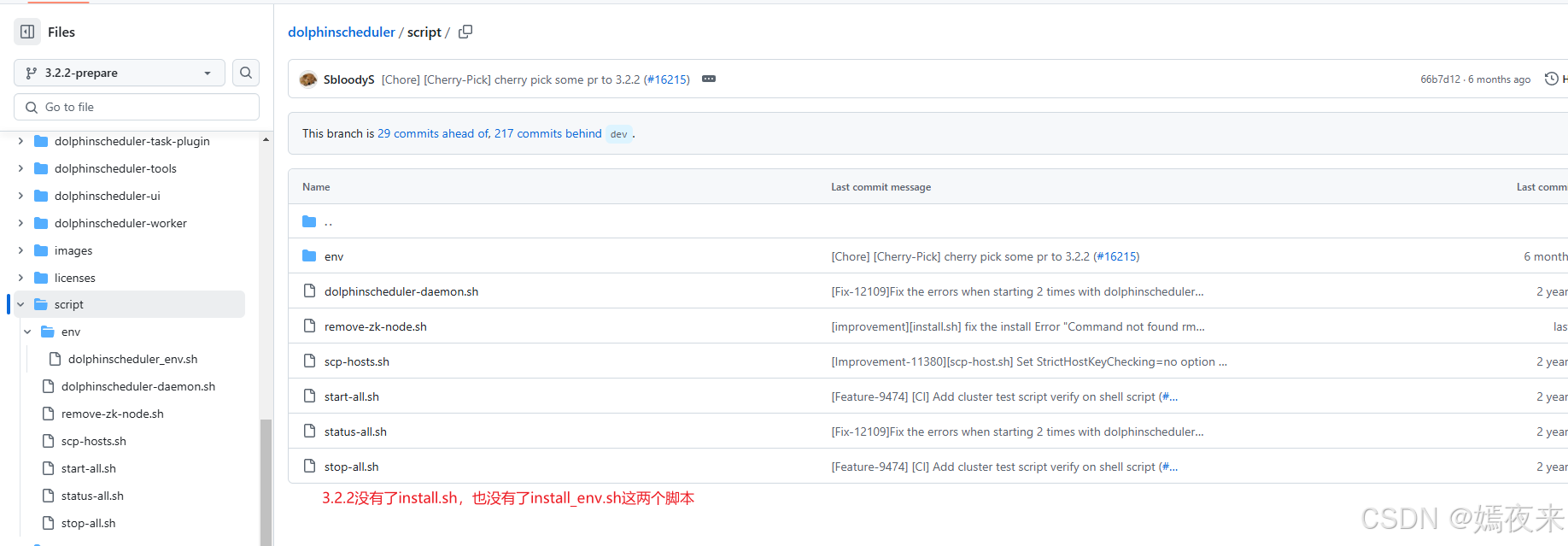
3.2.一键安装启动脚本install.sh
dolphinscheduler的一键安装就是通过这个install.sh脚本进行实现的。我把脚本里面注释都删除了,代码都增加了注释,具体的脚本内容如下:
# 获取当前工作目录的绝对路径并赋值给变量 workDir
workDir=`cd ${workDir};pwd`# 获取工作目录的父目录的绝对路径并赋值给变量 baseDir
baseDir=`cd ${workDir}/..;pwd`# 加载环境变量文件(安装环境设置)
# 这个文件中配置了我们需要将api-server/master-server/worker-server/alert-server
# 都要在哪些机器上面安装dolphinscheduler以及各个机器上需要启动的角色服务、部署的默认用户、
# 安装的默认基础目录、zookeper的根节点等配置)
source ${workDir}/env/install_env.sh# 加载 dolphinscheduler 的环境变量文件
source ${workDir}/env/dolphinscheduler_env.sh# 打印日志,说明开始创建目录
echo "1.create directory"# 检查安装路径是否与当前路径相同(设置的安装路径和执行脚本所在的父目录不能是同一个目录)
if [ ${baseDir} = $installPath ]; then# 如果安装路径与当前路径相同,打印错误信息并退出echo "Fatal: The installPath can not be same as the current path: ${installPath}"exit 1
elif [ ! -d $installPath ];then# 如果安装路径不存在,创建该目录并设置权限sudo mkdir -p $installPathsudo chown -R $deployUser:$deployUser $installPath
elif [[ -z "${installPath// }" || "${installPath// }" == "/" || ( $(command -v realpath) && $(realpath -s "${installPath}") == "/" ) ]]; then# 如果 installPath 为空、为根路径("/")或是根路径的相关路径,打印错误信息并退出echo "Parameter installPath can not be empty, use in root path or related path of root path, currently use ${installPath}"exit 1
fi# 打印日志,表示开始复制资源
echo "2.scp resources"# 执行 scp-hosts.sh 脚本,将资源拷贝到各个需要部署的服务器
# 一键分布式安装的核心代码就在这个scp-hosts.sh脚本中进行实现,后面详细说明
bash ${workDir}/scp-hosts.sh# 检查 scp 是否成功,如果失败则退出
if [ $? -eq 0 ];thenecho 'scp copy completed'
elseecho 'scp copy failed to exit'exit 1
fi# 打印日志,表示开始停止服务
echo "3.stop server"# 执行 stop-all.sh 脚本,停止所有相关的服务
bash ${workDir}/stop-all.sh# 打印日志,表示开始删除 ZooKeeper 节点
echo "4.delete zk node"# 执行 remove-zk-node.sh 脚本,删除指定的 ZooKeeper 节点
bash ${workDir}/remove-zk-node.sh $zkRoot# 打印日志,表示开始启动服务
echo "5.startup"# 执行 start-all.sh 脚本,启动所有相关的服务
bash ${workDir}/start-all.sh
3.3.一键安装核心脚本scp-hosts.sh
在这个脚本中主要就是读取安装配置文件中的主机集群列表,然后将bin、master-server、 worker-server、 alert-server、 api-server、 ui、 tools这几个目录拷贝到集群的各个主机的对应的安装目录下,拷贝完成就安装完毕了。
#!/bin/bash# 获取当前脚本所在的目录路径
workDir=`dirname $0`# 获取该目录的绝对路径并赋值给 workDir
workDir=`cd ${workDir};pwd`# 加载安装环境配置文件,设置安装时所需的环境变量
source ${workDir}/env/install_env.sh# 将以逗号分隔的 workers 字符串转换为数组
workersGroup=(${workers//,/ })# 遍历 workersGroup 数组,处理每个 worker
for workerGroup in ${workersGroup[@]}
do# 输出当前的 workerGroupecho $workerGroup;# 使用 awk 提取 worker 和 group 的值worker=`echo $workerGroup|awk -F':' '{print $1}'`group=`echo $workerGroup|awk -F':' '{print $2}'`# 将 worker 和 group 添加到对应的数组中workerNames+=($worker)groupNames+=(${group:-default}) # 如果没有指定 group,默认值为 'default'
done# 将以逗号分隔的 ips 字符串转换为数组
hostsArr=(${ips//,/ })# 遍历 hostsArr 数组,处理每个主机
# 开始往主机集群上拷贝安装资源文件
for host in ${hostsArr[@]}
do# 如果远程主机的 $installPath 目录不存在,则创建该目录,并设置目录的权限if ! ssh -o StrictHostKeyChecking=no -p $sshPort $host test -e $installPath; thenssh -o StrictHostKeyChecking=no -p $sshPort $host "sudo mkdir -p $installPath; sudo chown -R $deployUser:$deployUser $installPath"fi# 输出正在将目录拷贝到目标主机的日志echo "scp dirs to $host/$installPath starting"# 遍历 workerNames 数组,找到当前主机对应的 worker 索引for i in ${!workerNames[@]}; doif [[ ${workerNames[$i]} == $host ]]; thenworkerIndex=$ibreakfidone# 如果找到了对应的 worker 索引,则修改 application.yaml 配置文件中的 worker group# 这行代码现在基本没啥用了,配置参数已移除。[[ -n ${workerIndex} ]] && sed -i "s/- default/- ${groupNames[$workerIndex]}/" $workDir/../worker-server/conf/application.yaml# 拷贝dolphinscheduler的各个目录到目标主机的安装路径# 一键分布式安装的核心就在这里for dsDir in bin master-server worker-server alert-server api-server ui toolsdo# 输出正在拷贝某个目录的日志echo "start to scp $dsDir to $host/$installPath"# 使用 quiet 模式减少 scp 输出scp -q -P $sshPort -r $workDir/../$dsDir $host:$installPathdone# 恢复 application.yaml 中的 worker group 配置为默认值[[ -n ${workerIndex} ]] && sed -i "s/- ${groupNames[$workerIndex]}/- default/" $workDir/../worker-server/conf/application.yaml# 输出拷贝操作完成的日志echo "scp dirs to $host/$installPath complete"
done
3.3.一键集群启动脚本start-all.sh
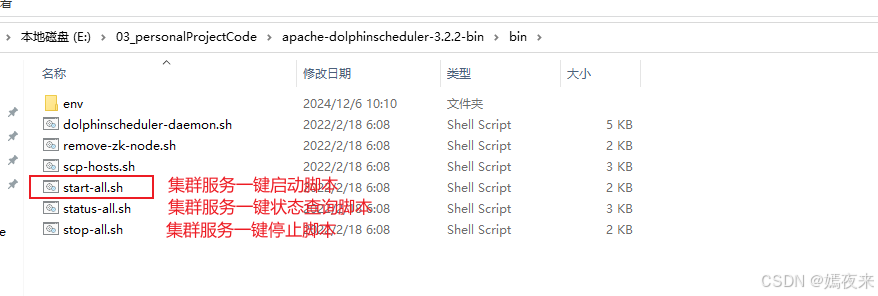
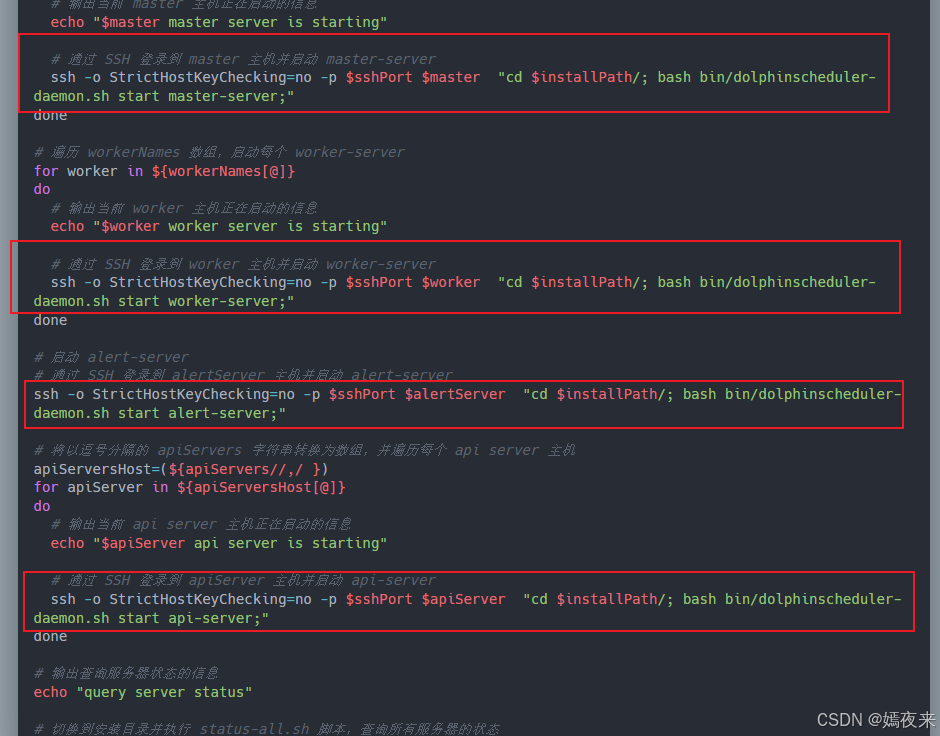
集群一键启动所有(api-server、master-server、worker-server及alert-server)服务节点的入口脚本start-all.sh源码如下:
#!/bin/bash# 获取当前脚本的目录路径,并赋值给 workDir
workDir=`dirname $0`# 转换为绝对路径,确保后续引用的路径是准确的
workDir=`cd ${workDir};pwd`# 加载环境配置文件,设置安装时所需的环境变量
# 主要读取各个服务角色分别都在集群的那些节点上进行了部署
source ${workDir}/env/install_env.sh# 将以逗号分隔的 workers 字符串转换为数组,并遍历每个 worker group
# 读取所有的worker服务的启动节点列表
workersGroup=(${workers//,/ })
for workerGroup in ${workersGroup[@]}
do# 输出当前的 worker group 信息echo $workerGroup;# 使用 awk 提取 worker 名称,并将其添加到 workerNames 数组中worker=`echo $workerGroup|awk -F':' '{print $1}'`workerNames+=($worker)
done# 将以逗号分隔的 masters 字符串转换为数组,并遍历每个 master 主机
# 读取所有的master服务的启动节点列表
mastersHost=(${masters//,/ })
for master in ${mastersHost[@]}
do# 输出当前 master 主机正在启动的信息echo "$master master server is starting"# 通过 SSH 登录到 master 主机并启动 master-server# 实际上还是调用了安装目录下的bin目录下的dolphinscheduler-daemon.sh脚本来完成单个api-server/master-server/worker-server/alert-server服务的启动、停止及运行状态查询ssh -o StrictHostKeyChecking=no -p $sshPort $master "cd $installPath/; bash bin/dolphinscheduler-daemon.sh start master-server;"
done# 遍历 workerNames 数组,启动每个 worker-server
for worker in ${workerNames[@]}
do# 输出当前 worker 主机正在启动的信息echo "$worker worker server is starting"# 通过 SSH 登录到 worker 主机并启动 worker-serverssh -o StrictHostKeyChecking=no -p $sshPort $worker "cd $installPath/; bash bin/dolphinscheduler-daemon.sh start worker-server;"
done# 启动 alert-server
# 通过 SSH 登录到 alertServer 主机并启动 alert-server
ssh -o StrictHostKeyChecking=no -p $sshPort $alertServer "cd $installPath/; bash bin/dolphinscheduler-daemon.sh start alert-server;"# 将以逗号分隔的 apiServers 字符串转换为数组,并遍历每个 api server 主机
apiServersHost=(${apiServers//,/ })
for apiServer in ${apiServersHost[@]}
do# 输出当前 api server 主机正在启动的信息echo "$apiServer api server is starting"# 通过 SSH 登录到 apiServer 主机并启动 api-serverssh -o StrictHostKeyChecking=no -p $sshPort $apiServer "cd $installPath/; bash bin/dolphinscheduler-daemon.sh start api-server;"
done# 输出查询服务器状态的信息
echo "query server status"# 切换到安装目录并执行 status-all.sh 脚本,查询所有服务器的状态
cd $installPath/; bash bin/status-all.sh
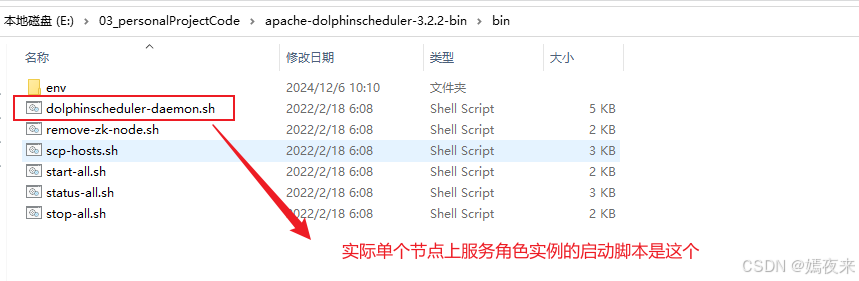
通过start-all.sh脚本我们知道了实际上各个服务角色的启动还是调用了安装目录下的bin目录下的dolphinscheduler-daemon.sh脚本来完成单个api-server/master-server/worker-server/alert-server服务的启动、停止及运行状态查询
就是安装目录的bin目录下的这个脚本
我们一起看看这个脚本,还是一样, 我删除了所有的多余注释:
#!/bin/bash# 定义脚本的用法说明(帮助信息),包括脚本接收的参数形式。
usage="Usage: dolphinscheduler-daemon.sh (start|stop|status) <api-server|master-server|worker-server|alert-server|standalone-server> "# 判断脚本参数个数是否小于等于 1,如果是则输出帮助信息并退出。
if [ $# -le 1 ]; thenecho $usageexit 1
fi# 获取第一个参数作为操作类型(start/stop/status),然后将剩下的参数通过 shift 操作传递给后续变量。
startStop=$1
shift
command=$1
shift# 输出当前操作的信息。
echo "Begin $startStop $command......"# 获取当前脚本所在目录,并赋值给 BIN_DIR
BIN_DIR=`dirname $0`
# 转换为绝对路径,确保后续路径正确
BIN_DIR=`cd "$BIN_DIR"; pwd`
# 获取 DolphinScheduler 安装路径(上级目录)
DOLPHINSCHEDULER_HOME=`cd "$BIN_DIR/.."; pwd`
# 设置 bin 环境变量配置文件的路径
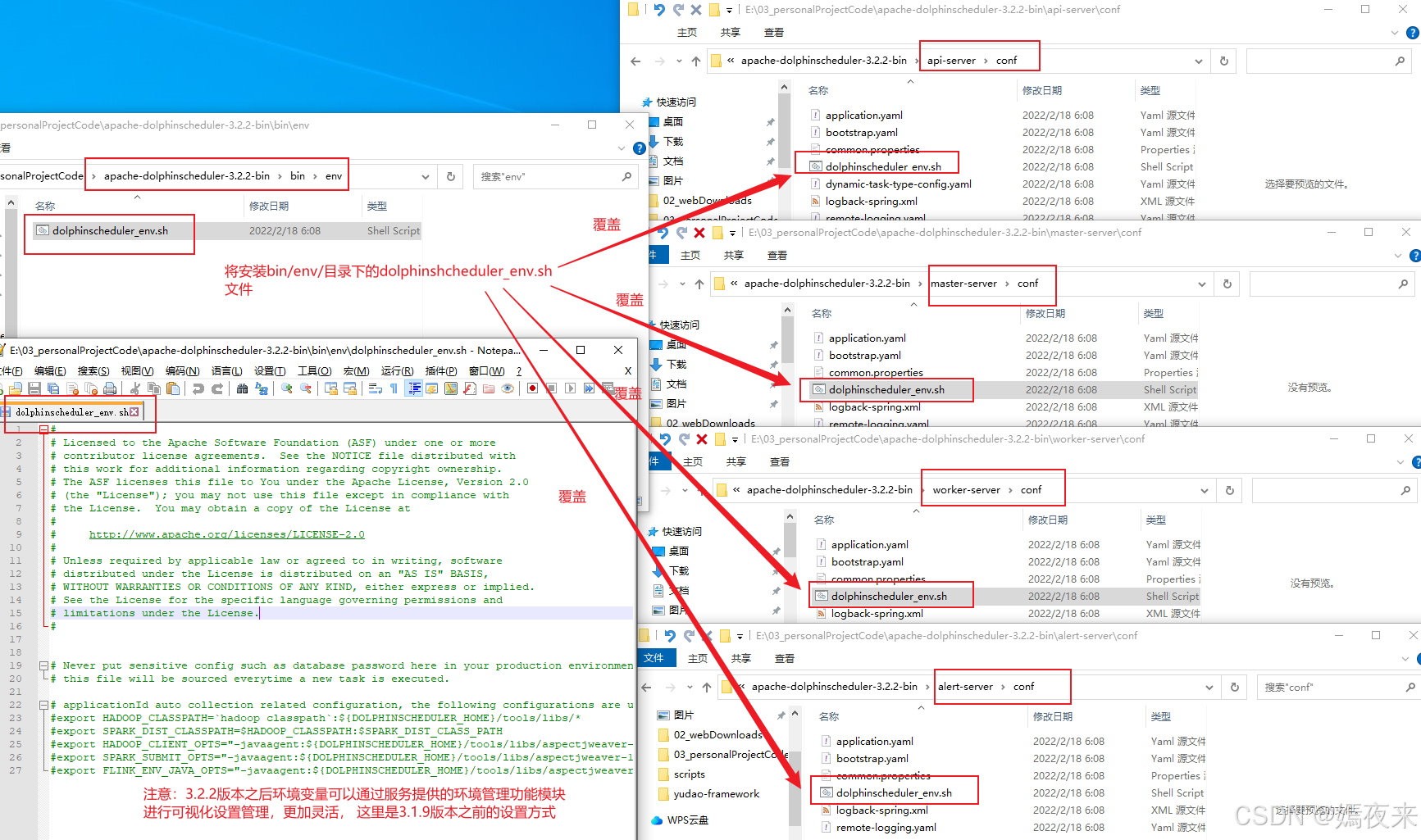
BIN_ENV_FILE="${DOLPHINSCHEDULER_HOME}/bin/env/dolphinscheduler_env.sh"# 定义一个函数,负责将脚本中的环境变量配置文件复制到对应服务的配置文件夹
function overwrite_server_env() {local server=$1# 服务的环境变量配置文件路径local server_env_file="${DOLPHINSCHEDULER_HOME}/${server}/conf/dolphinscheduler_env.sh"# 判断是否存在 bin 环境配置文件,如果存在则覆盖目标服务的配置文件if [ -f "${BIN_ENV_FILE}" ]; thenecho "Overwrite ${server}/conf/dolphinscheduler_env.sh using bin/env/dolphinscheduler_env.sh."cp "${BIN_ENV_FILE}" "${server_env_file}"else# 如果 bin 环境配置文件不存在,则输出提示信息,告知使用默认配置echo "Start server ${server} using env config path ${server_env_file}, because file ${BIN_ENV_FILE} not exists."fi
}# 获取当前主机名,并赋值给 HOSTNAME
export HOSTNAME=`hostname`# 定义服务日志存储路径,并根据操作的服务(如 api-server、worker-server 等)设置日志目录
export DOLPHINSCHEDULER_LOG_DIR=$DOLPHINSCHEDULER_HOME/$command/logs# 设置服务停止的最大等待时间(秒)
export STOP_TIMEOUT=5# 如果日志目录不存在,则创建该目录
if [ ! -d "$DOLPHINSCHEDULER_LOG_DIR" ]; thenmkdir $DOLPHINSCHEDULER_LOG_DIR
fi# 获取服务的 PID 文件路径
pid=$DOLPHINSCHEDULER_HOME/$command/pid# 切换到相应服务的目录下
cd $DOLPHINSCHEDULER_HOME/$command# 根据服务名称设置日志文件路径
if [ "$command" = "api-server" ]; thenlog=$DOLPHINSCHEDULER_HOME/api-server/logs/$command-$HOSTNAME.out
elif [ "$command" = "master-server" ]; thenlog=$DOLPHINSCHEDULER_HOME/master-server/logs/$command-$HOSTNAME.out
elif [ "$command" = "worker-server" ]; thenlog=$DOLPHINSCHEDULER_HOME/worker-server/logs/$command-$HOSTNAME.out
elif [ "$command" = "alert-server" ]; thenlog=$DOLPHINSCHEDULER_HOME/alert-server/logs/$command-$HOSTNAME.out
elif [ "$command" = "standalone-server" ]; thenlog=$DOLPHINSCHEDULER_HOME/standalone-server/logs/$command-$HOSTNAME.out
else# 如果没有找到对应的服务,则输出错误信息并退出echo "Error: No command named '$command' was found."exit 1
fi# 初始化服务运行状态为 "STOP"
state=""# 定义一个函数,用于获取当前服务的运行状态
function get_server_running_status() {state="STOP"# 如果存在 PID 文件,则获取 PID,并判断对应进程是否正在运行if [ -f $pid ]; thenTARGET_PID=`cat $pid`# 如果目标进程是 bash 进程,则认为服务正在运行if [[ $(ps -p "$TARGET_PID" -o comm=) =~ "bash" ]]; thenstate="RUNNING"fifi
}# 根据传入的操作类型执行对应的操作(start、stop、status)
case $startStop in(start)# 获取服务的当前运行状态get_server_running_status# 如果服务已经在运行,则输出提示并退出if [[ $state == "RUNNING" ]]; thenecho "$command running as process $TARGET_PID. Stop it first."exit 1fi# 输出启动服务的信息echo starting $command, logging to $DOLPHINSCHEDULER_LOG_DIR# 覆盖服务的环境变量配置overwrite_server_env "${command}"# 启动服务的脚本,并将输出重定向到日志文件nohup /bin/bash "$DOLPHINSCHEDULER_HOME/$command/bin/start.sh" > $log 2>&1 &# 将新启动的进程 PID 保存到 PID 文件echo $! > $pid;;(stop)# 如果 PID 文件存在,则停止服务if [ -f $pid ]; thenTARGET_PID=`cat $pid`# 判断进程是否存在,如果存在则停止该服务if kill -0 $TARGET_PID > /dev/null 2>&1; thenecho stopping $command# 杀掉服务的进程pkill -P $TARGET_PIDsleep $STOP_TIMEOUT# 如果服务在超时时间内没有停止,则强制杀死进程if kill -0 $TARGET_PID > /dev/null 2>&1; thenecho "$command did not stop gracefully after $STOP_TIMEOUT seconds: killing with kill -9"pkill -P -9 $TARGET_PIDfielse# 如果 PID 文件中没有找到对应的进程,则输出提示信息echo no $command to stopfi# 删除 PID 文件rm -f $pidelseecho no $command to stopfi;;(status)# 获取服务的运行状态get_server_running_status# 根据状态输出不同颜色的提示信息if [[ $state == "STOP" ]]; thenstate="[ \033[1;31m $state \033[0m ]" # 红色表示停止elsestate="[ \033[1;32m $state \033[0m ]" # 绿色表示运行fi# 输出服务的状态echo -e "$command $state";;(*)# 如果操作类型不匹配,则输出帮助信息并退出echo $usageexit 1;;esac# 输出操作完成的信息
echo "End $startStop $command."
总结一下这个脚本的主要作用:
-
1.将我们在执行安装操作之前设置的
bin/env/dolphinscheduler_env.sh环境变量配置信息同步到各个服务节点的conf/dolphinscheduler_env.sh进行覆盖
-
2.给目标主机的目标启动服务角色目录下创建日志保存目录logs

-
3.给目标主机的目标启动服务角色目录下创建进程ID保存文本文件pid,用于服务停止时可以找到pid快速停止服务

-
4.当前是启动服务,会调用$installPath/服务角色目录/bin/start.sh脚本进行服务启动。
启动api-server,就会调用api-server/bin/start.sh
启动master-server,就会调用master-server/bin/start.sh
启动worker-server,就会调用worker-server/bin/start.sh
启动alert-server,就会调用alert-server/bin/start.sh
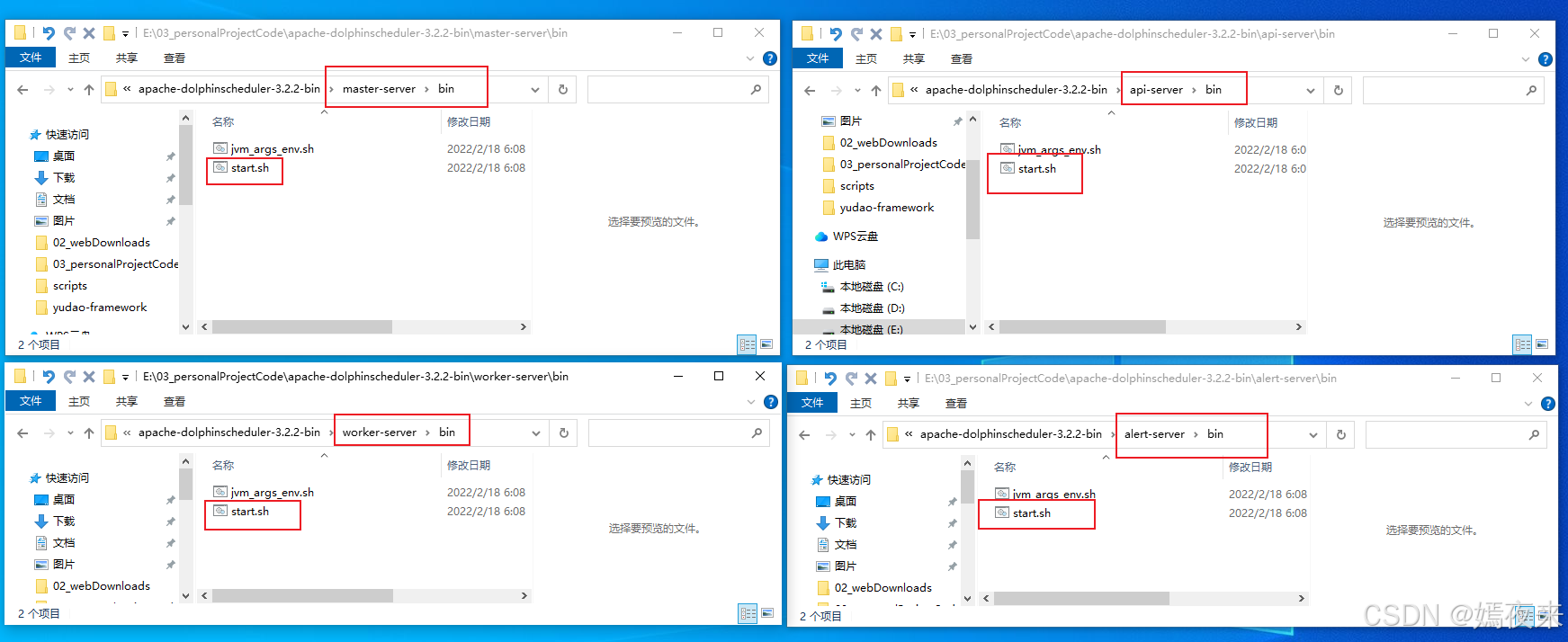
下面再看看各个角色服务的启动脚本,我们就以api-server服务的start.sh启动脚本为例来进行说明,因为我们的角色服务项目基本都是Springboot项目,所以在这个脚本里肯定会以java -jar xxxx.jar或java -jar -cp jar类路径 启动入口类的方式启动我们的角色实例项目,下面我们一起验证一下:
3.4.api-server服务的启动脚本
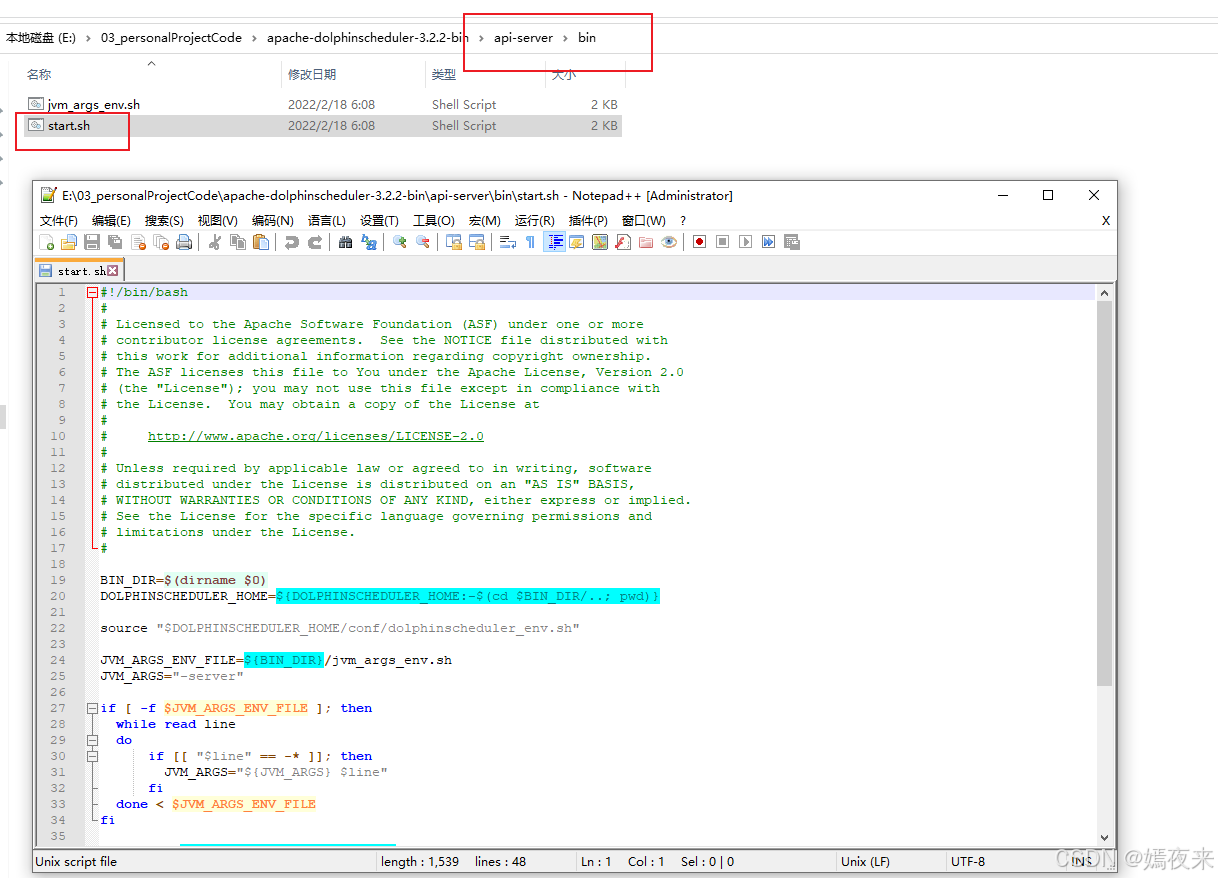
我们去掉多余的注释信息, 看看这个启动脚本start.sh
#!/bin/bash# 获取脚本所在的目录,并将其赋值给 BIN_DIR
BIN_DIR=$(dirname $0)# 如果环境变量 DOLPHINSCHEDULER_HOME 已设置,则使用该值;否则,自动推算 DOLPHINSCHEDULER_HOME 为脚本所在目录的上一级路径
DOLPHINSCHEDULER_HOME=${DOLPHINSCHEDULER_HOME:-$(cd $BIN_DIR/..; pwd)}# 加载配置文件,包含环境变量和其他配置
source "$DOLPHINSCHEDULER_HOME/conf/dolphinscheduler_env.sh"# 定义 JVM 参数的环境变量配置文件路径
JVM_ARGS_ENV_FILE=${BIN_DIR}/jvm_args_env.sh# 默认的 JVM 参数
JVM_ARGS="-server"# 如果 JVM 参数文件存在,逐行读取该文件并解析其中的参数
if [ -f $JVM_ARGS_ENV_FILE ]; thenwhile read linedo# 如果该行以 '-' 开头,则认为是 JVM 参数并添加到 JVM_ARGS 中if [[ "$line" == -* ]]; thenJVM_ARGS="${JVM_ARGS} $line"fidone < $JVM_ARGS_ENV_FILE
fi# 如果 JAVA_OPTS 环境变量未设置,则使用默认的 JVM_ARGS
JAVA_OPTS=${JAVA_OPTS:-"${JVM_ARGS}"}# 如果 DOCKER 环境变量设置为 "true",则添加特定的 JVM 参数
if [[ "$DOCKER" == "true" ]]; thenJAVA_OPTS="${JAVA_OPTS} -XX:-UseContainerSupport"
fi# 输出 JAVA_HOME 和 JAVA_OPTS 变量的值,用于调试或验证
echo "JAVA_HOME=${JAVA_HOME}"
echo "JAVA_OPTS=${JAVA_OPTS}"# 使用配置好的 JAVA_HOME 和 JAVA_OPTS 启动 api-server应用,分别指定类路径和启动类
$JAVA_HOME/bin/java $JAVA_OPTS -cp "$DOLPHINSCHEDULER_HOME/conf":"$DOLPHINSCHEDULER_HOME/libs/*" org.apache.dolphinscheduler.api.ApiApplicationServer
通过以上脚本最终生成的api-server的启动命令示例如下:
/usr/local/jdk1.8.0_202/bin/java \
-server -Duser.timezone=GMT+8 -Xms2g -Xmx2g -Xmn512m \
-XX:+PrintGCDetails -Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dump.hprof \
-cp /opt/bigdata/dolphinscheduler/ds/api-server/conf:/opt/bigdata/dolphinscheduler/ds/api-server/libs/* \
org.apache.dolphinscheduler.api.ApiApplicationServer
这个启动脚本做了一下几件事情:
- 1.生效当前角色服务目录的conf目录下dolphinscheduler_env.sh文件中的系统环境变量配置信息
- 2.将start.sh同目录下的jvm_args_env.sh中定义的JVM启动参数项读取出来 组装到$JAVA_OPTS变量中,
- 3.组装好api-server服务的启动命令并执行启动。
按照这个逻辑我们应该就可以推理出其他的角色服务的启动流程基本都是相同的, 存在的不同的主要就是在于:
- 1.JVM启动参数的设置可能会不同
- 2.服务启动的java入口主类肯定会根据对应的服务角色启动对应的主类
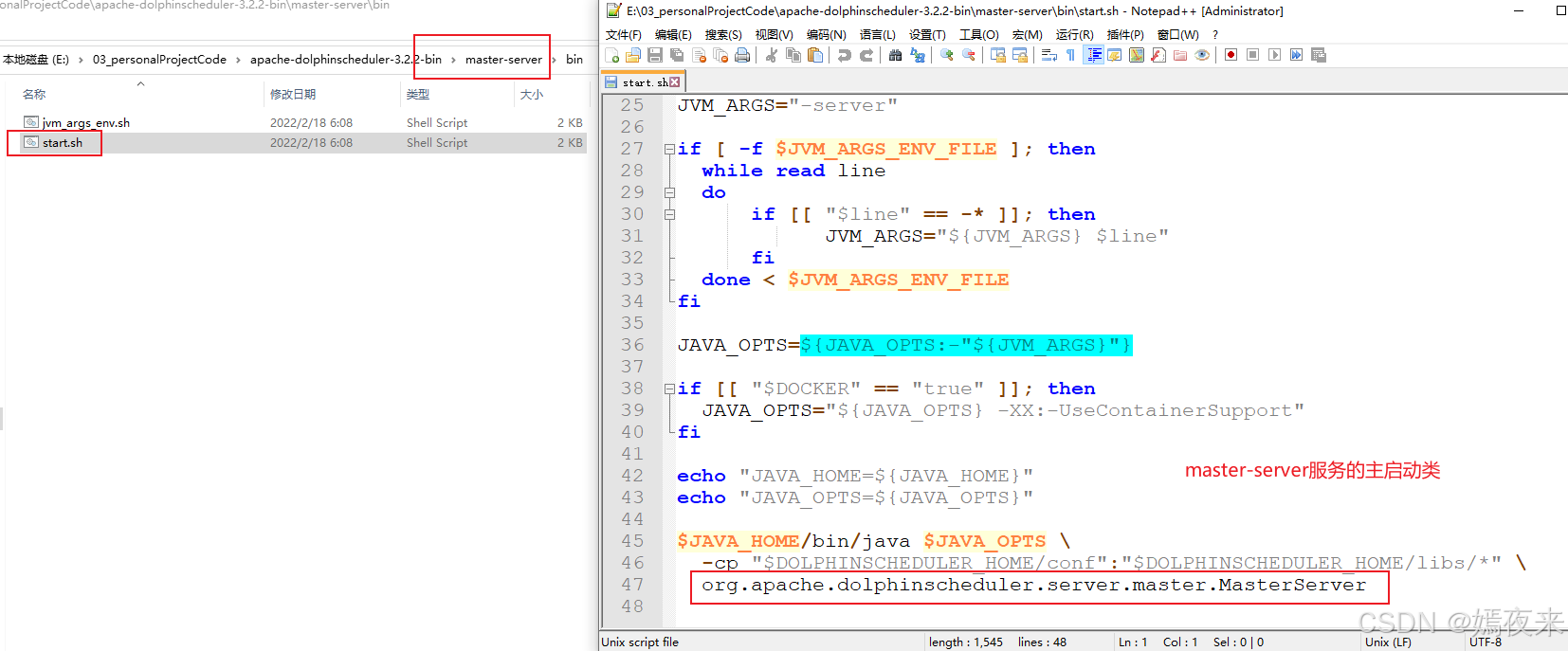
3.4.master-server服务的启动脚本
验证一下master-server启动脚本中的主入口类
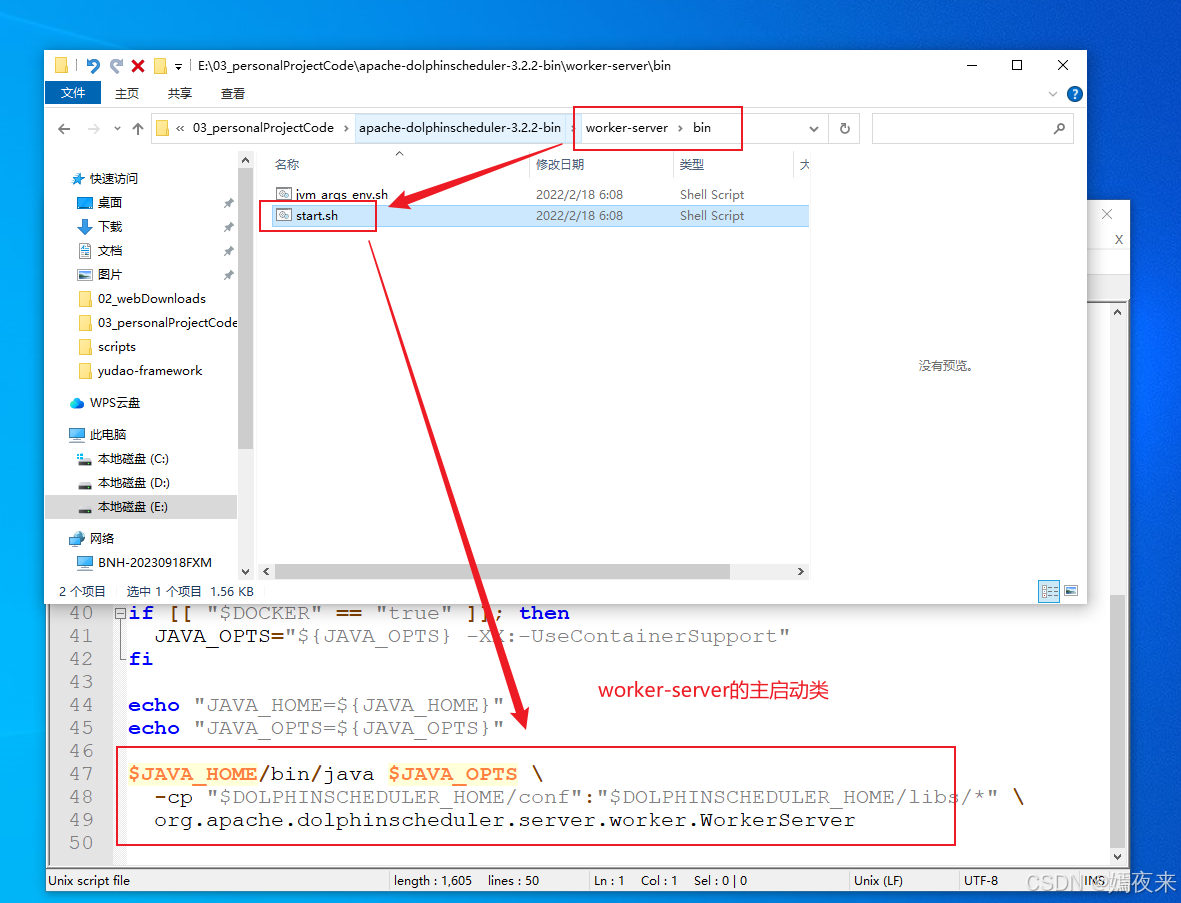
3.5.worker-server服务的启动脚本
验证一下worker-server启动脚本中的主入口类
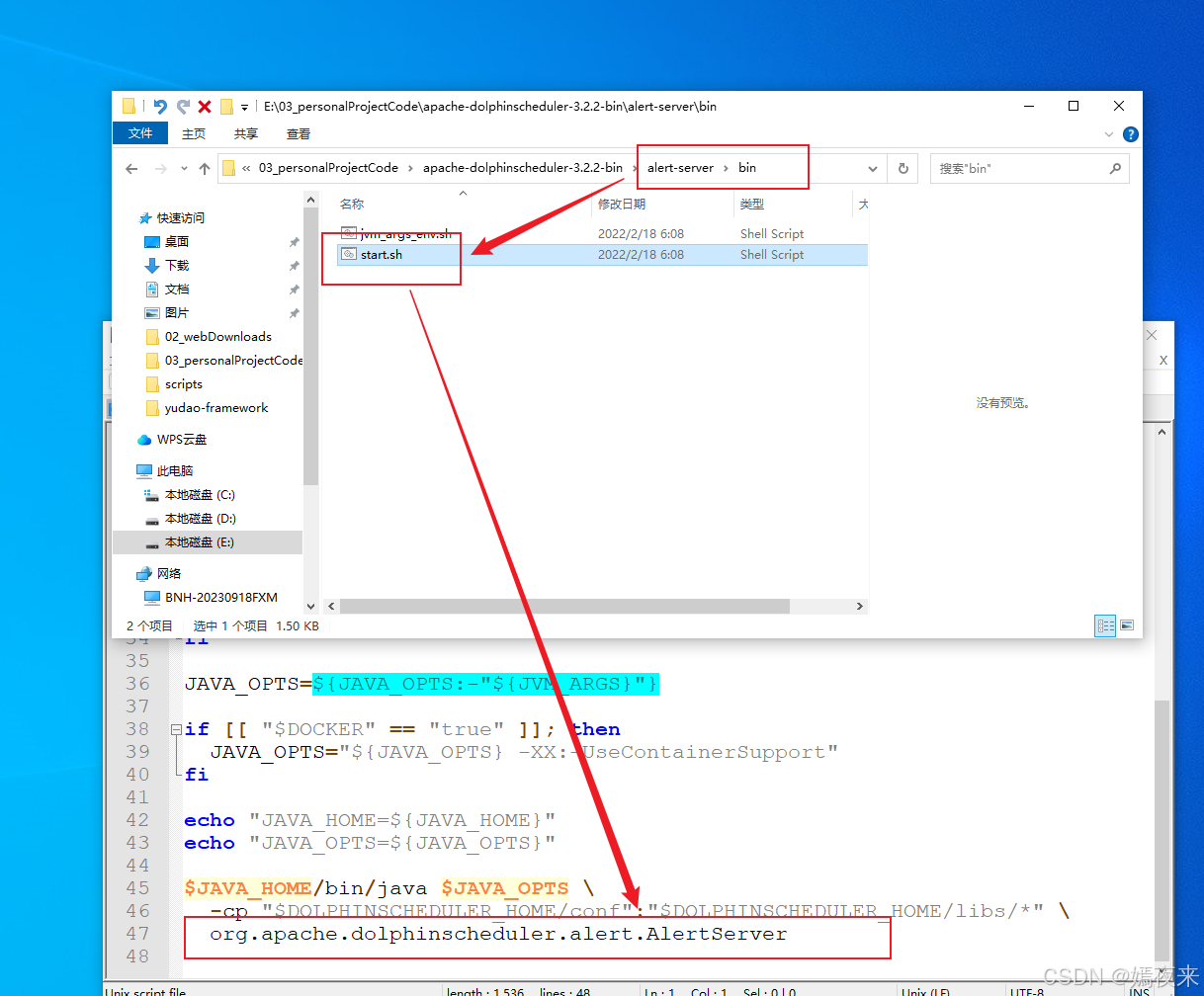
3.6.alert-server服务的启动脚本
验证一下alert-server启动脚本中的主入口类
4.总结
通过以上分析我们基本梳理清楚了整个dolphinscheduler项目的一键安装启动逻辑, 我们现在在通过一张图正好理一下整个实现流程。
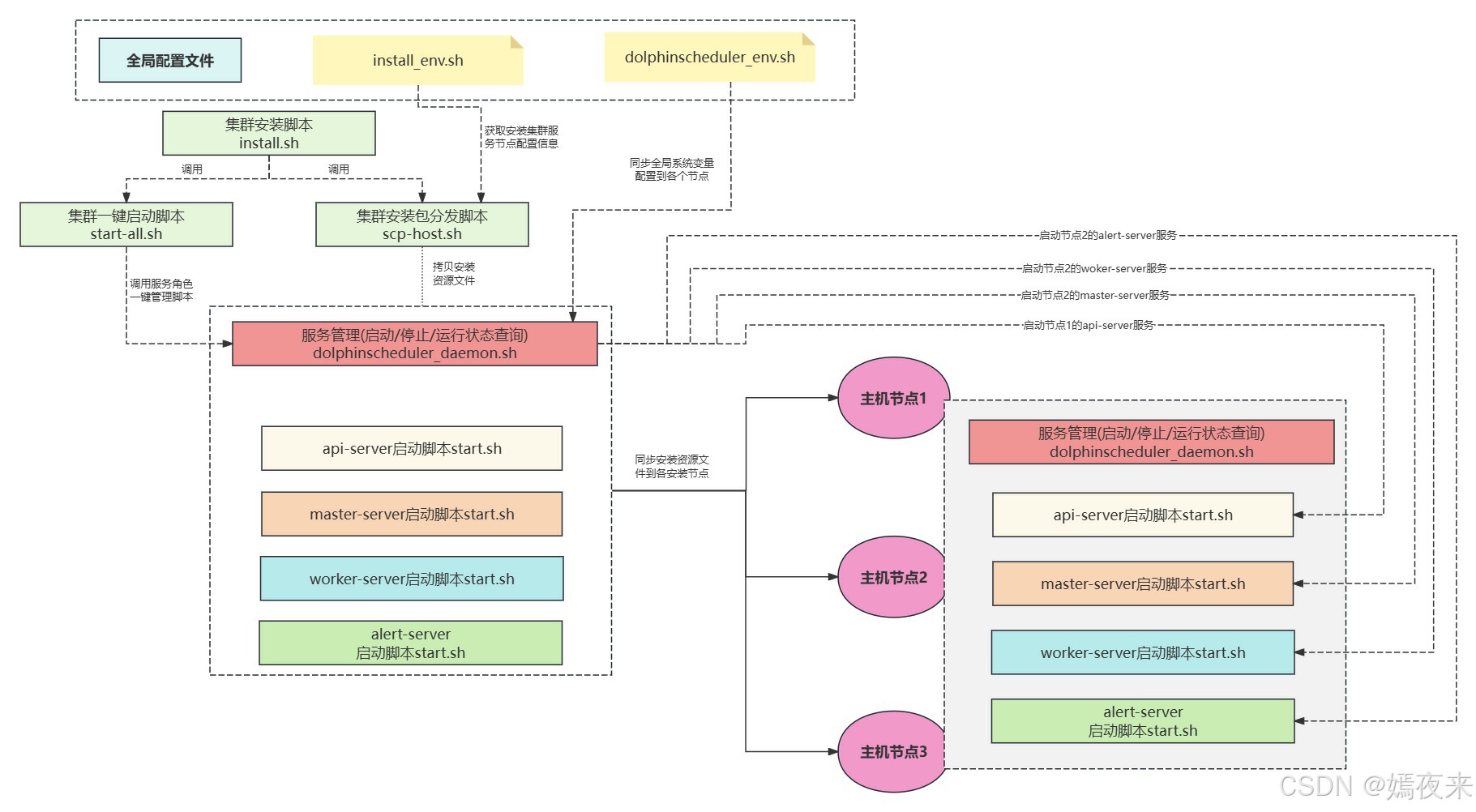 关于一键停止集群服务及一件查询集群各个角色服务实例运行状态的实现也都在stop-all.sh/status-all.sh及dolphinscheduler-daemon.sh这三个脚本中, 有兴趣自行研究。
关于一键停止集群服务及一件查询集群各个角色服务实例运行状态的实现也都在stop-all.sh/status-all.sh及dolphinscheduler-daemon.sh这三个脚本中, 有兴趣自行研究。
写这篇文章的核心目的不仅在于给大家分享如何优秀的开源项目的一键安装部署的实现过程,更想要
的是能启发大家的思路,能够将我们从这中间学习到的好的方法和思想运用到我们实际的项目,有些东西理解启动其实挺容易的, 运用,举一反三对大多数人来说还是很难的,希望大家看完都能有所收获,如果觉得文章写的还不错,喜欢的童鞋们请点赞收藏,送你一朵小红花哈~~~~~~