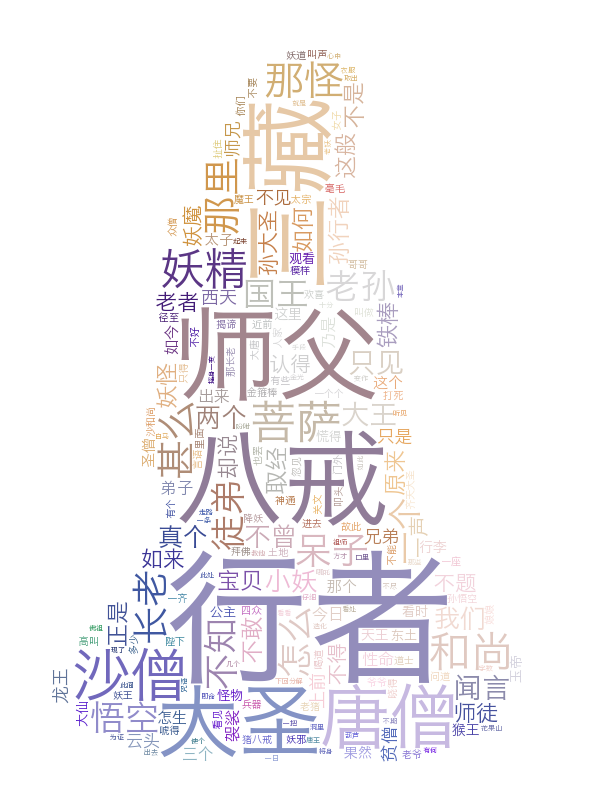做企业网站哪里找微信crm
文本挖掘与可视化:生成个性化词云的Python实践【7个案例】
词云(Word Cloud),又称为文字云或标签云,是一种用于文本数据可视化的技术,通过不同大小、颜色和字体展示文本中单词的出现频率或重要性。在词云中,更频繁出现的单词会显示得更大,反之则更小。
词云的好处和作用:
-
直观展示关键词:词云可以快速展示文本中的主要概念和关键词,使观众能够一眼识别文本的主要内容。
-
强调重要性:通过字体大小的不同,词云可以直观地表达不同单词的重要性,有助于突出显示文本中的核心议题。
-
美观:词云可以设计成各种形状和颜色,具有很高的艺术性和观赏性,可以吸引观众的注意力。
-
信息压缩:词云将大量文本信息压缩成一张图,便于快速浏览和理解,尤其适合于社交媒体和快速消费的阅读环境。
-
数据探索:在数据分析和文本挖掘中,词云可以作为探索性数据分析的工具,帮助发现数据中的模式和趋势。
-
报告和演示:词云常用于报告和演示中,以图形化的方式展示研究结果或分析结论。
-
情感分析:在社交媒体监控和情感分析中,词云可以帮助快速识别公众对某个话题或品牌的普遍态度。
-
教育工具:在教育领域,词云可以作为教学工具,帮助学生理解文本结构和主题。
-
交互性:一些词云工具允许交互,用户可以点击词云中的单词以获取更多信息或执行搜索。
-
多语言支持:词云不仅限于英文,也支持中文、日文、阿拉伯文等其他语言,使其成为一种跨语言的可视化工具。
词云的生成通常涉及文本预处理(如去除停用词、标点符号等),然后根据单词的权重(如词频或TF-IDF分数)来调整字体大小,最后使用图形库(如PIL/Pillow)生成图像。尽管词云非常有用,但也存在局限性,如难以展示复杂的语法结构和语义关系,因此在实际应用中需要根据具体需求谨慎使用。
词云的实现
主要用到对 wordcloud 和 matplotlib 这两个Python库
以下是对 wordcloud 和 matplotlib 这两个Python库的简单介绍:
WordCloud
WordCloud 是一个流行的Python库,用于生成词云。词云是一种通过不同大小的单词来表示文本数据中单词频率的可视化方法。单词出现得越频繁,它们在词云中显示得越大。这个库非常灵活,允许用户自定义词云的许多方面,包括:
- 词汇的排除和包含
- 字体、颜色和形状的选择
- 词云的布局和格式
- 以及更多…
WordCloud 库通常用于数据分析、文本挖掘和可视化,以直观地展示文本数据的关键特征。
Matplotlib
Matplotlib 是Python中一个广泛使用的绘图库,它提供了一个类似于MATLAB的绘图框架,用于创建各种静态、交互式和动画的可视化图表。Matplotlib 支持多种输出格式,并且可以无缝地与各种Python环境集成,包括IPython、Jupyter notebook等。
Matplotlib 的主要特点包括:
- 生成线图、散点图、柱状图等多种类型的图表。
- 丰富的图表定制选项,如标题、图例、坐标轴标签等。
- 支持多种绘图样式和布局。
- 提供了多种工具来操作图形元素,如线条、文本、标签和注解。
- 可以生成高分辨率的栅格图形或矢量图形。
Matplotlib 是数据科学、机器学习、科学计算和商业分析中常用的可视化工具之一。
这两个库结合使用时,可以创建出既美观又信息丰富的词云图像,帮助用户快速把握文本数据的关键信息。
环境版本
编辑器: pycharm
环境版本:
-
python3.7
-
wordcloud 1.9.3
-
matplotlib 3.5.3
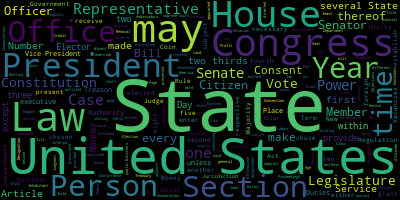
案例01:最简调用
代码:
# -*- coding: utf-8 -*-from wordcloud import WordCloud
import matplotlib.pyplot as plt# 打开文本
text = open('constitution.txt').read()
# 生成对象
wc = WordCloud().generate(text)# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()# 保存到文件
wc.to_file('wordcloud.png')
这段代码是使用Python编写的,它的作用是生成一个词云(WordCloud),词云是一种可视化技术,用于显示文本数据中单词的频率。具体来说,这段代码做了以下几件事情:
-
导入必要的库:
WordCloud用于生成词云。matplotlib.pyplot用于显示词云的图形。
-
打开一个名为
constitution.txt的文本文件,读取其内容,并将其存储在变量text中。 -
使用
WordCloud类生成一个词云对象wc,将文本数据传递给generate方法。 -
使用
matplotlib库显示生成的词云:plt.imshow(wc, interpolation='bilinear')显示词云图像。plt.axis('off')关闭坐标轴。plt.show()显示图形。
-
将生成的词云保存到一个名为
wordcloud.png的文件中。
要运行这段代码,你需要确保有 wordcloud 和 matplotlib 这两个Python库安装在你的系统中,并且有一个名为 constitution.txt 的文本文件存在于代码运行的同一目录下。该文本文件应该包含你想要生成词云的文本数据。运行代码后,你将在当前目录下得到一个名为 wordcloud.png 的词云图片文件。
运行结果如下:
案例02:中文不分词
代码:
# -*- coding: utf-8 -*-
# 中文不分词
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 打开文本:吴承恩的西游记,指定使用utf-8编码读取
with open('../xyj.txt', 'r', encoding='utf-8') as f:text = f.read()
# 生成对象
wc = WordCloud(font_path='../Hiragino.ttf', width=800, height=600, mode='RGBA', background_color=None).generate(text)# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()# 保存到文件
wc.to_file('main_2.png')
运行结果:

案例03:中文分词
为什么中文文本需要分词:
分词(Tokenization)是文本处理中的一个术语,指的是将文本分解成更小的单元,通常是单词或者词语。在中文文本处理中,分词尤为重要,因为中文书写时通常不会像英文那样使用空格来分隔单词。
-
语言结构:中文书写习惯中,单词之间没有明显的分隔符,一个长句子如果不进行分词,很难确定词与词之间的界限。
-
计算和统计:分词后,可以更准确地进行词频统计,这对于文本挖掘、情感分析、机器学习等应用至关重要。
-
信息提取:分词可以帮助识别文本中的关键信息,如人名、地名、机构名等。
-
搜索和检索:搜索引擎和推荐系统通常依赖于分词来提高搜索和推荐的准确性。
-
自然语言理解:分词是自然语言理解(NLP)的第一步,有助于后续的语言模型和机器学习算法更好地处理文本数据。
代码中,使用jieba库进行中文分词:
# 中文分词
text = ' '.join(jieba.cut(text))
这里,jieba.cut(text)会返回一个生成器,其中包含了文本text的分词结果。使用' '.join()将分词结果连接成一个由空格分隔的字符串,以便WordCloud库可以正确地处理和生成词云。
jieba是中文分词领域的一个非常流行的Python库,它支持三种分词模式:
- 精确模式:试图将句子最精确地切分。
- 全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎构建索引。
最后,使用分词后的文本生成词云,可以更准确地反映出文本中各个词语的重要性和频率,从而生成更有意义的词云图像。
代码:
# -*- coding: utf-8 -*-
# 中文,分词
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba# 打开文本
with open('../xyj.txt', 'r', encoding='utf-8') as f:text = f.read()# 中文分词
text = ' '.join(jieba.cut(text))
print(text[:100])# 生成对象
wc = WordCloud(font_path='../Hiragino.ttf', width=800, height=600, mode='RGBA', background_color=None).generate(text)# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()# 保存到文件
wc.to_file('wordcloud.png')
运行结果:

案例04:使用蒙版形状
代码:
# -*- coding: utf-8 -*-from wordcloud import WordCloud
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba# 打开文本
with open('../xyj.txt', 'r', encoding='utf-8') as f:text = f.read()# 中文分词
text = ' '.join(jieba.cut(text))
print(text[:100])# 生成对象
mask = np.array(Image.open("../black_mask.png"))
wc = WordCloud(mask=mask, font_path='../Hiragino.ttf', mode='RGBA', background_color=None).generate(text)# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()# 保存到文件
wc.to_file('main_4.png')
蒙版:

运行结果:

案例05:使用蒙版颜色
代码:
# -*- coding: utf-8 -*-from wordcloud import WordCloud, ImageColorGenerator
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba# 打开文本
with open('../xyj.txt', 'r', encoding='utf-8') as f:text = f.read()# 中文分词
text = ' '.join(jieba.cut(text))
print(text[:100])# 生成对象
mask = np.array(Image.open("../color_mask.png"))
wc = WordCloud(mask=mask, font_path='../Hiragino.ttf', mode='RGBA', background_color=None).generate(text)# 从图片中生成颜色
image_colors = ImageColorGenerator(mask)
wc.recolor(color_func=image_colors)# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()# 保存到文件
wc.to_file('main_5.png')
运行结果:
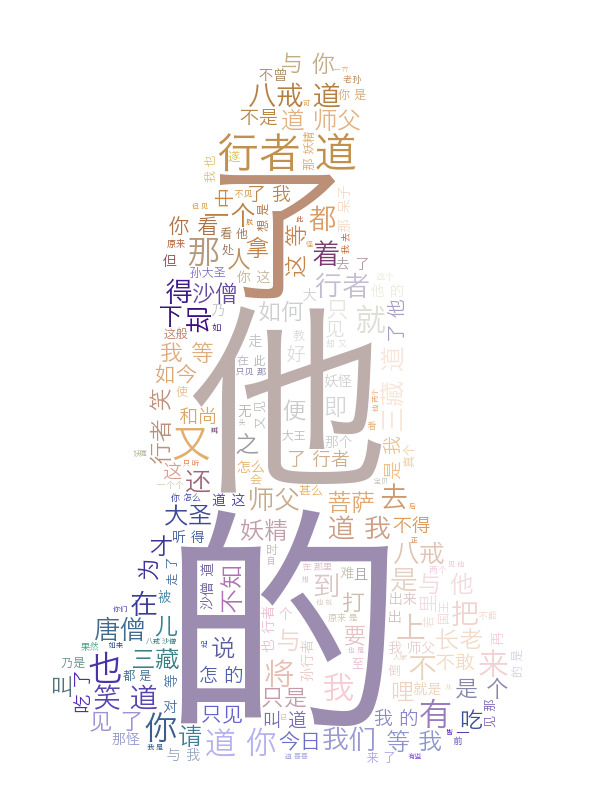
案例06:蒙版-自定义颜色函数
代码:
# -*- coding: utf-8 -*-from wordcloud import WordCloud
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import random
import jieba# 打开文本
with open('../xyj.txt', 'r', encoding='utf-8') as f:text = f.read()# 中文分词
text = ' '.join(jieba.cut(text))
print(text[:100])# 颜色函数
def random_color(word, font_size, position, orientation, font_path, random_state):s = 'hsl(0, %d%%, %d%%)' % (random.randint(60, 80), random.randint(60, 80))print(s)return s# 生成对象
mask = np.array(Image.open("../color_mask.png"))
wc = WordCloud(color_func=random_color, mask=mask, font_path='../Hiragino.ttf', mode='RGBA', background_color=None).generate(text)# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()# 保存到文件
wc.to_file('main_06.png')
效果图:

案例07:蒙版-提取关键词和权重
代码:
# -*- coding: utf-8 -*-from wordcloud import WordCloud, ImageColorGenerator
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba.analyse# 打开文本
with open('../xyj.txt', 'r', encoding='utf-8') as f:text = f.read()# 提取关键词和权重
freq = jieba.analyse.extract_tags(text, topK=200, withWeight=True)
print(freq[:20])
freq = {i[0]: i[1] for i in freq}# 生成对象
mask = np.array(Image.open("../color_mask.png"))
wc = WordCloud(mask=mask, font_path='../Hiragino.ttf', mode='RGBA', background_color=None).generate_from_frequencies(freq)# 从图片中生成颜色
image_colors = ImageColorGenerator(mask)
wc.recolor(color_func=image_colors)# 显示词云
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()# 保存到文件
wc.to_file('main_07.png')
效果图: