网站图片自动下载广州seo排名外包
一般来说都是针对数据量特别大,内存有限制的。
第一类:topk问题
比如,在海量数据中找前50大的数据怎么办?
方法一:使用小顶堆,用小顶堆维护这50个元素,当有新元素到来时,直接与堆顶进行比较(小顶堆堆顶最小),如果比堆顶大,替换堆顶,调整堆结构。
堆中含k个元素,堆内部调整时间复杂度logk,一共n个数据,每来一个都要进行一次堆调整,总的时间复杂度O(nlogk),总的空间复杂度O(k)。
方法二:使用快排,快排的思想是找标准值,标准值左边都是比它小的,右边都是比它大的,返回中间标准值的位置,找前k大的,就在标准值的右边进行查找,步骤一样(先确定标准值,将小于标准值的放入左侧,大于标准值放入右侧)
开始数据量为n,进行一次二分数据量变为n/2,后续只需要在这n/2中进行查找,进行两次变为n/4以此类推...最终时间复杂度n+n/2+n/4+...+1=2n-1,总的时间复杂度O(n)。
方法二同样适用无序元素中找第k大的数,时间复杂度要求O(n)
第二类:海量数据的两个文件找相同
比如,两个文件中存放1000万电话号码,找这两个文件中相同的电话号码?
位图法,对于电话号一共11位,从10000000000~19999999999,大约10G空间,采用位图法该电话号存在对应为1,不存在对应0,将存储空间压缩到10G/8=1.25G。
第三类:海量数据排序
比如有10GB的订单数据。希望按照订单的金额(金额是整数)进行排序,但是内存只有几百MB,无法一次性加载到内存。
方法一:采用分桶排序。加入金额是0-10万,分成100个桶,每个桶的范围是1千。比如桶0是从0~1000,桶1是从1001~2000...数据按照区域进行划分。存在100个文件中,文件内部进行排序,可以使用快排,依次从桶0、桶1...中取元素,得到的就是有序的10GB数据。时间复杂度O(nlogn/100),计算方法为:100个文件,每个文件进行快排,每个文件数据n/100,100*(NlogN),其中N为n/100,最终结果为O(nlogn/100)。
存在的问题是如果数据在某个范围特别多,比如某个桶有1GB的数据,这种情况怎么办?
对这个桶中元素再进行分桶,各桶有序再合并。
方法二:将数据等分到100个文件中,每个文件相当于100MB的数据,每个文件内部快排。同时维护一个小顶堆。每次取堆顶,可以先放入缓存,最后放入文件中。
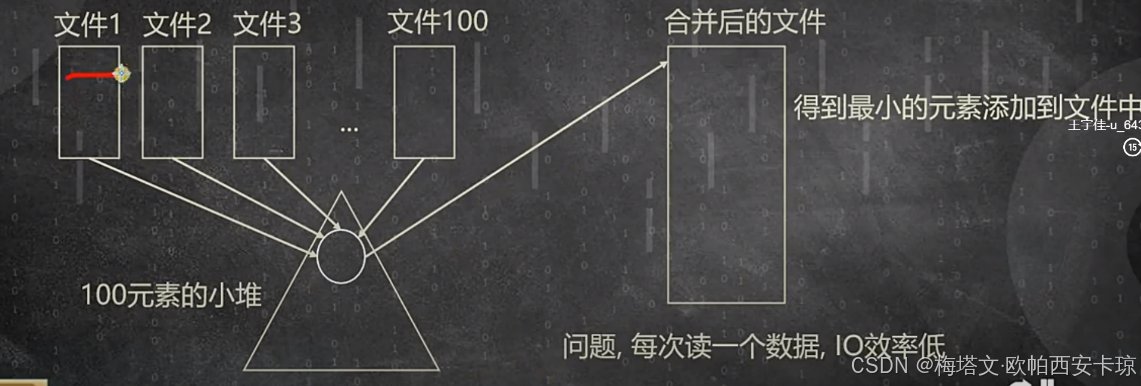
方法三:文件之间两两合并,相当于合并有序列表。
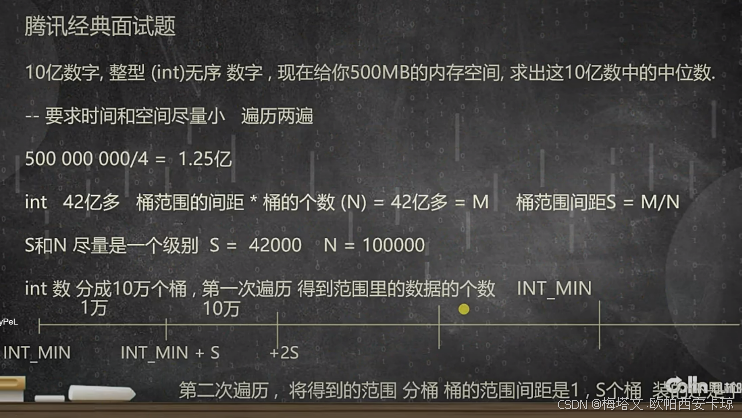
既然找10亿元素中的中位数,就是找第5亿个、第5亿+1个,每个桶有相应的存储元素个数,大致确定5亿、5亿+1元素具体位于哪个桶,再对该桶进行分桶,桶的间距为1,再进行查找即可。