做网站到底怎么赚钱人民日报今天新闻
文章目录
- 安装py2neo
- 创建节点-连线关系图
- 导入csv文件
- 删除重复节点并连接边
安装py2neo
安装python中的neo4j操作库:pip install py2neo
安装py2neo后我们可以使用其中的函数对neo4j进行操作。
图数据库Neo4j中最重要的就是结点和边(关系),结点之间靠边联系在一起,每个结点也有属于自己的属性。
也就是说我们在用pyhton操作Neo4j的时候只需要创造出节点(Node )和节点之间的关系:边(Relationship ),如果节点存在附加属性,可以再给结点附上一些属性。
注意: 在我们用python的时候我们必须启动Neo4j。如图所示,点击connect进行连接。
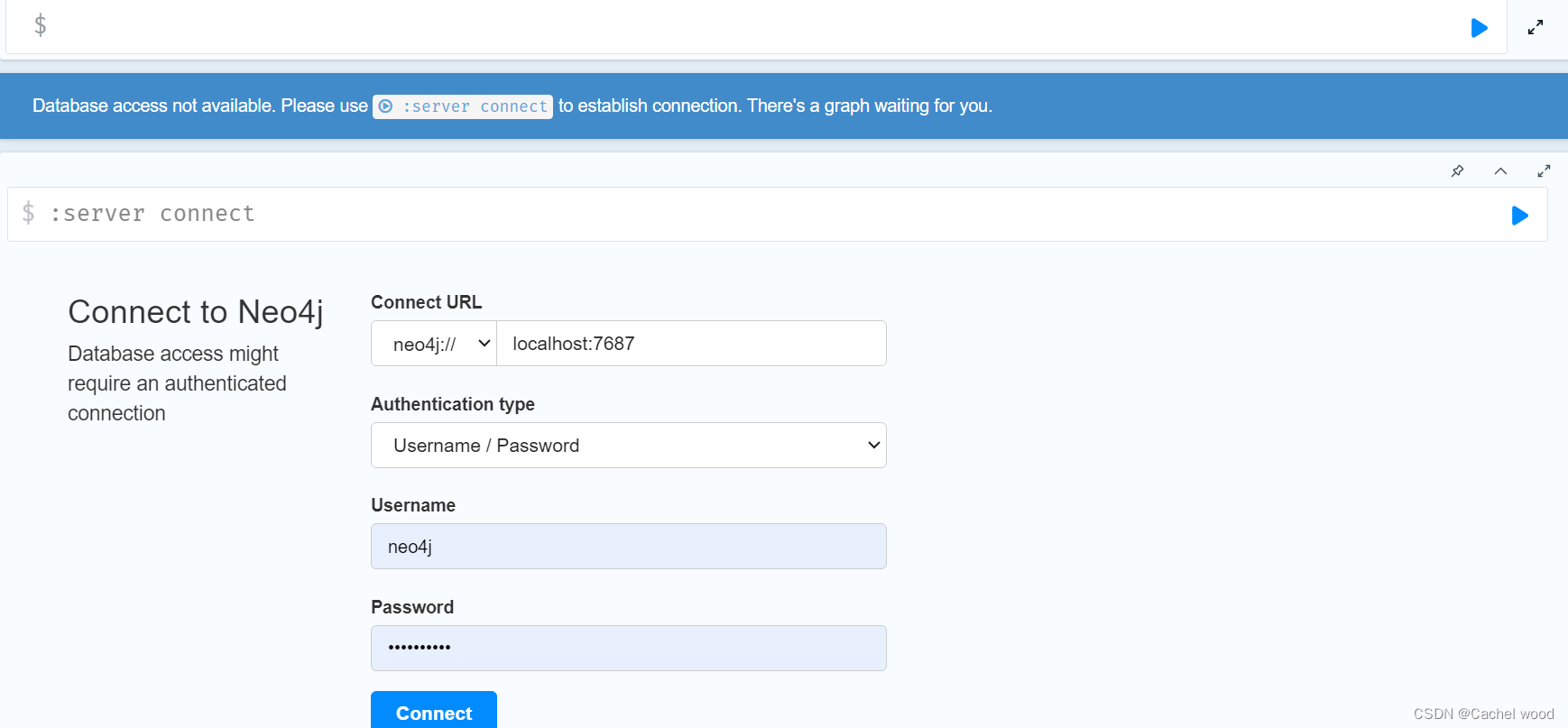
创建节点-连线关系图
下面我们就创建三个结点,每个结点有两个属性,两结点之间有一个关系。
from py2neo import Graph, Node, Relationship
# 连接neo4j数据库,输入地址、用户名、密码
graph = Graph("http://localhost:7474", name="neo4j", password='123456SWXR')
graph.delete_all() #清除neo4j中原有的结点等所有信息# 创建结点
node1 = Node('person', name = 'chenjianbo') #该结点语义类型是person 结点名字是chenjianbo 也是它的属性
node2 = Node('major',name = 'software') #该结点语义类型是major 结点名字是software 也是它的属性
node3 = Node('person',name = 'bobo') #该结点语义类型是person 结点名字是bobo 也是它的属性#给结点node1 添加一个属性 age
node1['age'] = 18
#给结点node2 添加一个属性 college
node2['college'] = 'software college'
#给结点node3 添加一个属性 sex
node3['sex'] = '男'#把结点实例化 在Neo4j中显示出来
graph.create(node1)
graph.create(node2)
graph.create(node3)
# 创建关系
maojor = Relationship(node1, '专业', node2)
friends = Relationship(node1, '朋友', node3)
maojor1 = Relationship(node3, '专业', node2)
#把关系实例化 在Neo4j中显示出来
graph.create(maojor)
graph.create(maojor1)
graph.create(friends)
导入csv文件
该网站有大量汇总的知识图谱数据集,可供学习使用。
http://openkg.cn/dataset
周杰伦歌曲知识数据集csv,应用三元组的形式将歌曲、歌手和所属专辑联系在一起。
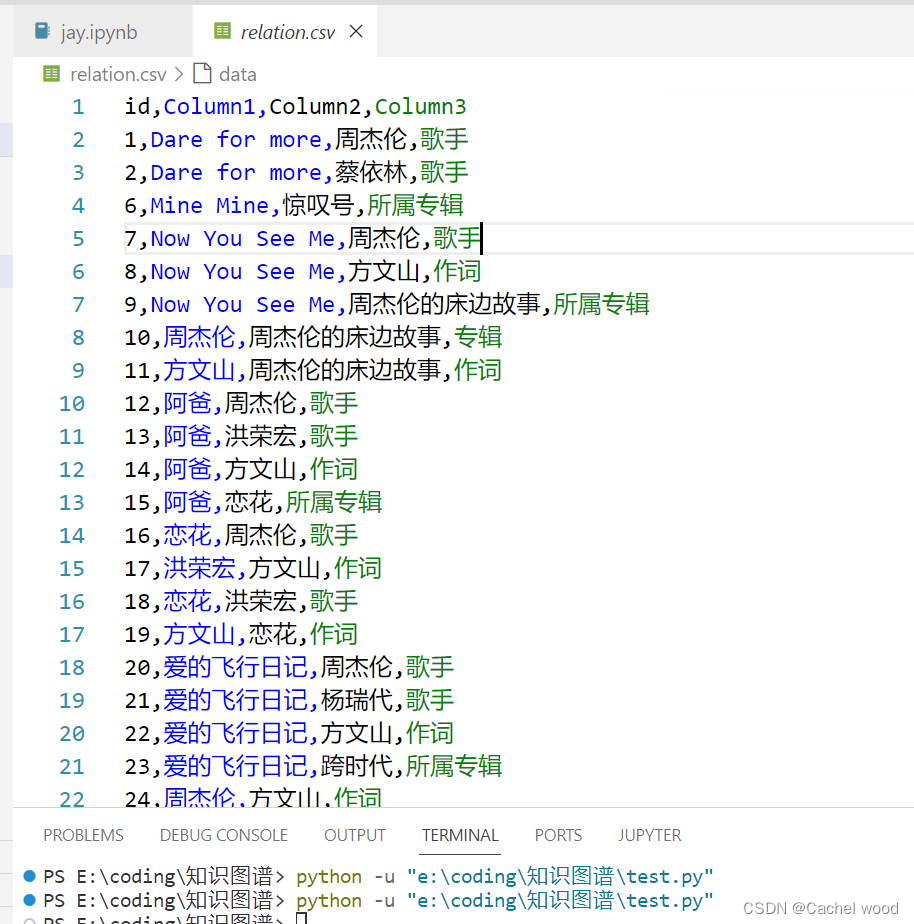
dataframe格式读入数据
import pandas as pddf = pd.read_csv('relation.csv',index_col=0)df
Column1 Column2 Column3
id
1 Dare for more 周杰伦 歌手
2 Dare for more 蔡依林 歌手
6 Mine Mine 惊叹号 所属专辑
7 Now You See Me 周杰伦 歌手
8 Now You See Me 方文山 作词
... ... ... ...
624 最后的战役 周杰伦 歌手
625 最后的战役 方文山 作词
626 最后的战役 八度空间 所属专辑
627 最长的电影 周杰伦 歌手
628 最长的电影 我很忙 所属专辑
- 使用
py2neo向neo4j添加节点和边
graph.delete_all() #清除neo4j中原有的结点等所有信息for index,row in df.iterrows():node1 = Node('person',name=row[0])node2 = Node('person',name=row[1])graph.create(node1)graph.create(node2)each = Relationship(node1, row[2], node2)graph.create(each)
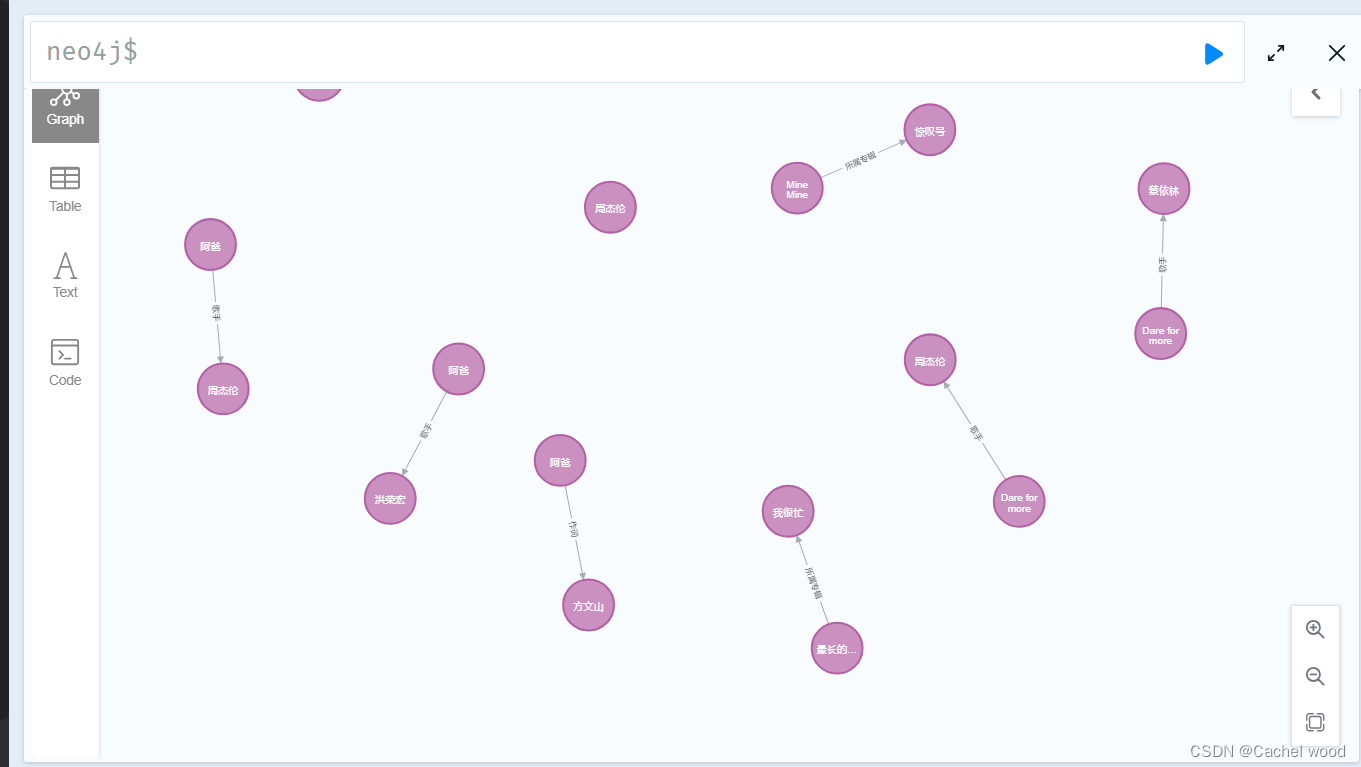
这样生成的知识图谱只是简单的节点-边的关系,存在大量冗余的实体entity。
可以通过neo4j的删除方法将重复节点进行删除,之后将边重新连接。
删除重复节点并连接边
查询重复节点,如果有重复节点就不create。这样节点和边全部联系在一起,形成完整的没有冗余的知识图谱。
目前的缺点是节点Node的命名都是以person命名,所以节点暂时没有区分。
graph.delete_all() #清除neo4j中原有的结点等所有信息
from py2neo import NodeMatcher
entity = []for index,row in df.iterrows():if row[0] not in entity:entity.append(row[0])node1 = Node('person',name=row[0])graph.create(node1)else:node_matcher = NodeMatcher(graph) node1 = list(node_matcher.match('person').where(name=row[0]))[0]print(node1)if row[1] not in entity:entity.append(row[1]) node2 = Node('person',name=row[1])graph.create(node2)else:node_matcher = NodeMatcher(graph) node2 = list(node_matcher.match('person').where(name=row[1]))[0]print(node2)each = Relationship(node1, row[2], node2)graph.create(each)
