无锡网站建设无锡速联科技优化方案英语
puppeteer简介:
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议
控制 Chromium 或 Chrome。Puppeteer 默认以 headless 模式运行,
但是可以通过修改配置文件运行“有头”模式。能作什么?:
生成页面 PDF。
抓取 SPA(单页应用)并生成预渲染内容(即“SSR”(服务器端渲染))。
自动提交表单,进行 UI 测试,键盘输入等。
创建一个时时更新的自动化测试环境。 使用最新的 JavaScript 和浏览器功能直接在最新版本的Chrome中执行测试。
捕获网站的 timeline trace,用来帮助分析性能问题。
测试浏览器扩展。
这是中文puppeteer文档
实战:
一 安装:
安装nodejs, 再输入npm install puppeteer 安装这个库。注意puppeteer库有两个版本,一个是包含了chormedriver的puppeteer,另一个是不包含chormedriver的轻量级的puppeteer-core库。
再通过npm init 初始化一下。
二 代码
1、需求:我是打算通过关键字输入去爬取百度图片。
2、关键点:①通过合适的selector去获取到相应的元素 ②这个图片是分组的,需要分多个组,每个组的图片数目还不一样 ③需要定时的滑动页面去刷新数据
3、大致代码逻辑
①通过config 中的Dogconfig.js去获取存储的路径
②通过screenshot.js去实现爬取的主要图片的链接
③通过utils中的srcToimg去实现通过链接将图片存储在本地的目录中
Dogconfig.js
const path =require('path');module.exports={Dogscreenshot: path.resolve(__dirname,'../Dogscreenshot')
}
screenshot.js
const puppeteer = require('puppeteer');
const {screenshot} =require('./config/default');
const { Dogscreenshot } = require('./config/Dogconfig');
const srcToimg =require('./utils/srcToimg')function sleep (ms) {return new Promise(resolve => setTimeout(resolve, ms))} //sleep函数async function autoScroll(page) { //滚动界面return page.evaluate(() => {return new Promise((resolve, reject) => {let totalHeight = 0;let distance = 10;let timer = setInterval(() => {let scrollHeight = document.body.scrollHeight;window.scrollBy(0, distance);totalHeight += distance;if (totalHeight >= scrollHeight) {clearInterval(timer);resolve();}}, 5000);})});}(async()=>{const brower =await puppeteer.launch({headless:false, defaultViewport: null,args: ['--start-fullscreen'] });const page =await brower.newPage();await page.goto('https://image.baidu.com');await page.setDefaultNavigationTimeout(0); //无限制时间,防止执行太快,什么元素都没有加载出来await page.setDefaultNavigationTimeout(0); // await page.setViewport({// width:1060,// height:2080,// });console.log('reset setViewport');await page.focus('#kw'); //This method fetches an element with selector and focuses it.await page.keyboard.sendCharacter("狗"); //Dispatches a keypress and input event. This does not send a keydown or keyup event.await page.click('.s_btn_wr'); //uses Page.mouse to click in the center of the elementconsole.log('go to search list');page.on('load',async()=>{console.log('page loading done ,start fetch......');for(let group=1;group<5;group++){for(let i =22;i<45;i++){try { await page.waitForSelector('#imgid >div:nth-child('+group+') > ul > li:nth-child('+i+') > div.imgbox > div.imgbox-border > a > img'); } catch (e) {console.log('element probably not exists , the system had aleady choose next element body');i=i+1;};try{console.log('#imgid >div:nth-child('+group+') > ul > li:nth-child('+i+') > div.imgbox > div.imgbox-border > a > img')let imageUrl = await page.$$eval('#imgid >div:nth-child('+group+')> ul > li:nth-child('+i+') > div.imgbox > div.imgbox-border > a > img',(links)=>{return links.map(x=>{if(x.src){return x.src;}else{return ' ';} });});await page.waitForSelector('#imgid > div:nth-child('+group+') > ul > li:nth-child('+i+') > a');let imageTitle =await page.$$eval('#imgid > div:nth-child('+group+') > ul > li:nth-child('+i+') > a',(links=>{ return links.map(x=>{if(x.innerHTML){let xstr=x.innerHTML.replace(/[`:_.~!@#$%^&*() \+ =<>?"{}|, \/ ;' \\ [ \] ·~!@#¥%……&*()—— \+ ={}|《》?:“”【】、;‘’,。、]/g,''); //去除字符串的标点符号return xstr;}}); }));//console.log('这是'+i+'的: '+imageTitle[0]);let data=[];data.push(Dogscreenshot);data.push(imageTitle[0])if(imageUrl[0]){srcToimg(imageUrl[0],data);} //await autoScroll(page);//console.log(`get ${images.length} images,start download....`);}catch(e){console.log(e)await page.evaluate('window.scrollTo(0,100)') ; //滑动一下页面break;}; }}}); //Listen to page events.// await page.screenshot({// path:`${screenshot}/${Date.now()}.png`// }); //截图并保存在相应路径下//await sleep(50000);//await brower.close();
})();srcToimg.js
const http=require('http');
const https=require('https');
const path =require('path');
const fs =require('fs');
const {promisify} =require('util');
const writeFile =promisify(fs.writeFile);module.exports=async(src,data)=>{if(/^(http|https)/.test(src)){await urlToimg(src,data);}else{await base64Toimg(src,data);}
};//url=>image
const urlToimg=promisify((url,data,callback)=>{ //promise 用同步的方式写异步的代码,避免陷入回调地狱const mod=/^https/.test(url)?https:http;const ext =path.extname(url);const file=path.join(data[0],`${data[1]}${'.jpeg'}`)mod.get(url,res=>{res.pipe(fs.createWriteStream(file)).on('finish',()=>{ //pipe是node中的流概念callback();console.log(file);})})
});//base64=>img 如果图片返回的地址是以base64的形式返回的话。const base64Toimg =async function(base64Str,data){//date:image/jepg ;base64,/asdasa...const matches =base64Str.match(/^data:(.+?);base64,(.+)$/); //正则表达式的匹配try{const ext= matches[1].split('/')[1].replace('jepg','jpg');const file =path.jojn(data[0],`${data[1]}.${ext}`);await writeFile(file,matches[2],'base64');console.log(file);}catch(x){console.log('非法base64字符串!');}}
通过以上代码能实现要求。
值得注意的是:
nodejs不能直接调用window,会显示window not define的错误, 因为Web中使用JavaScript,BOM是核心,而BOM的核心对象是window。
所以我们要用到page.evalutate方法(这是官方文档的解释):
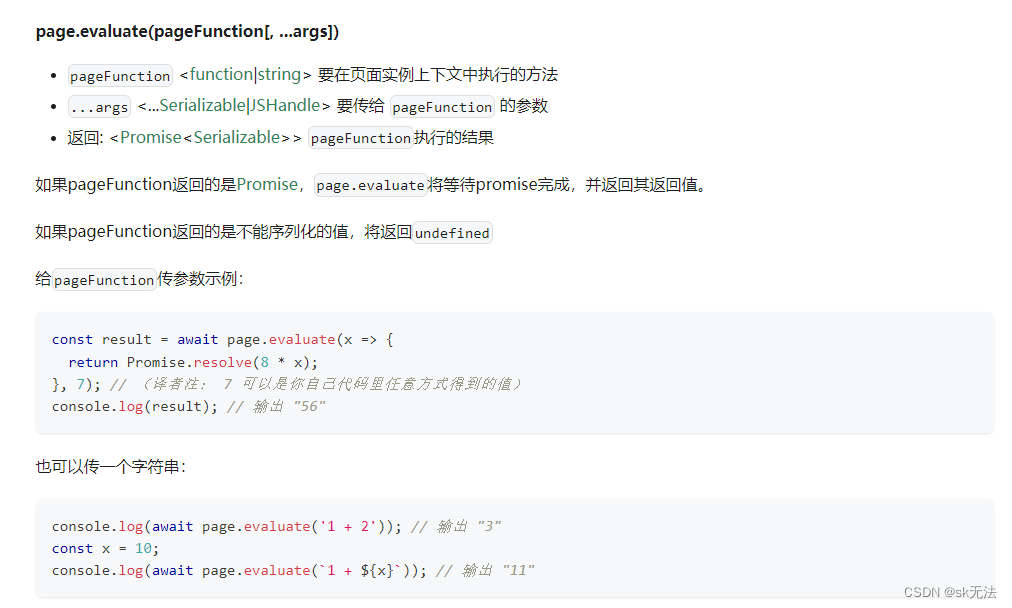
查阅其他博客知:
page.evaluate 意为在浏览器环境执行脚本,可传入第二个参数作为句柄,而 page.$eval 则针对选中的一个 DOM 元素执行操作。
基础扩展补充:
html是一门超文本标记语言;dom
document对象表明整个html文档,可用来访问页面中的全部元素;函数
body表明document的主体子对象,除浏览器头部,页面中可以看到的内容都属于body中的内容;post
window表明浏览器中打开的窗口,表明运行环境。this
BOM:浏览器对象模型(Browser Object Model )
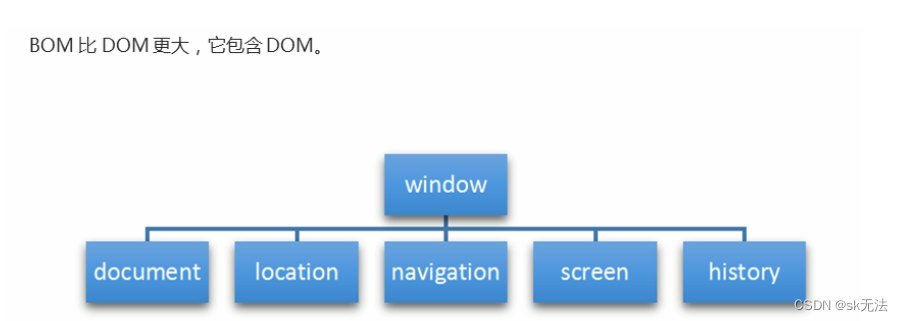 window:
window:
1、它是js访问浏览器窗口的一个接口
2、它是一个全局对象,定义在全局作用域中的变量,函数都会变成window对象的属性和方法。
这是js的BOM操作参考博客