如何做网站嵌入腾讯地图做外贸网站哪家公司好
引言
什么是降维? 降维是用于降低数据集维度的过程,采用许多特征并将它们表示为更少的特征。 例如,降维可用于将二十个特征的数据集减少到仅有几个特征。 降维通常用于无监督学习任务
降维是一个用于降低数据集维度的过程,采用许多特征并将它们表示为更少的特征。 例如,降维可用于将二十个特征的数据集减少到仅有几个特征。 降维常用于 无监督学习 从许多功能中自动创建类的任务。 为了更好地理解 为什么以及如何使用降维,我们将了解与高维数据相关的问题以及最流行的降维方法。
更多维度导致过度拟合
维度是指数据集中的特征/列的数量。
人们通常认为,在机器学习中,特征越多越好,因为它可以创建更准确的模型。然而,更多的功能并不一定意味着更好的模型。
数据集的特征对于模型的有用程度可能有很大差异,其中许多特征并不重要。 此外,数据集包含的特征越多,需要的样本就越多,以确保数据中能够很好地表示特征的不同组合。 因此,样本数量与特征数量成比例增加。 更多的样本和更多的特征意味着模型需要更加复杂,并且随着模型变得更加复杂,它们对过度拟合变得更加敏感。 该模型对训练数据中的模式学习得很好,但无法推广到样本数据之外。
降低数据集的维数有几个好处。 如前所述,更简单的模型不太容易过度拟合,因为模型必须对特征之间的相互关系做出更少的假设。 此外,维度越少意味着训练算法所需的计算能力就越少。 类似地,维度较小的数据集需要较少的存储空间。 降低数据集的维数还可以让您使用不适合具有许多特征的数据集的算法。
常见的降维方法
降维可以通过特征选择或特征工程来实现。 特征选择是工程师识别数据集最相关特征的地方,而 特征工程 是通过组合或改造其他特征来创建新特征的过程。
特征选择和工程可以通过编程或手动完成。 当手动选择和设计特征时,通常会通过可视化数据来发现特征和类之间的相关性。 以这种方式进行降维可能非常耗时,因此一些最常见的降维方法涉及使用 Scikit-learn for Python 等库中提供的算法。 这些常见的降维算法包括:主成分分析(PCA)、奇异值分解(SVD)和线性判别分析(LDA)。
用于无监督学习任务降维的算法通常是 PCA 和 SVD,而用于监督学习降维的算法通常是 LDA 和 PCA。在监督学习模型的情况下,新生成的特征仅被输入到机器学习分类器中。请注意,此处描述的用途只是一般用例,而不是这些技术可能使用的唯一条件。上述降维算法只是统计方法,它们在机器学习模型之外使用。
主成分分析

主成分分析(PCA) 是一种统计方法,分析数据集的特征/特征并总结最有影响力的特征。 数据集的特征组合在一起形成表示,该表示保留了数据的大部分特征,但分布在较少的维度上。 您可以将其视为将数据从较高维度的表示形式“压缩”为只有几个维度的表示形式。
作为 PCA 可能有用的情况的一个例子,请考虑描述葡萄酒的各种方式。 虽然可以使用许多高度具体的特征(例如二氧化碳水平、通气水平等)来描述葡萄酒,但在尝试识别特定类型的葡萄酒时,这些具体特征可能相对无用。 相反,根据味道、颜色和年龄等更一般的特征来识别类型会更加谨慎。 PCA可用于组合更具体的特征并创建更通用、有用且不太可能导致过度拟合的特征。
PCA 的执行方式是确定输入特征之间的平均值如何变化,并确定特征之间是否存在任何关系。 为了做到这一点,创建一个协变矩阵,建立一个由关于数据集特征的可能对的协方差组成的矩阵。 这用于确定变量之间的相关性,负协方差表示逆相关,正相关表示正相关。
数据集的主要(最有影响力)组成部分是通过创建初始变量的线性组合来创建的,这是在线性代数概念的帮助下完成的 特征值和特征向量。 创建组合是为了使主成分彼此不相关。 初始变量中包含的大部分信息被压缩到前几个主成分中,这意味着已经创建了新特征(主成分),其中包含较小维空间中的原始数据集的信息。
奇异值分解

奇异值分解(SVD) is 用于简化矩阵中的值,将矩阵简化为其组成部分,并使该矩阵的计算变得更容易。 SVD 可用于实值矩阵和复数矩阵,但出于本说明的目的,我们将研究如何分解实值矩阵。
假设我们有一个由实值数据组成的矩阵,我们的目标是减少矩阵内的列/特征的数量,类似于 PCA 的目标。 与 PCA 一样,SVD 会压缩矩阵的维数,同时尽可能保留矩阵的可变性。 如果我们想对矩阵 A 进行操作,我们可以将矩阵 A 表示为另外三个矩阵,称为 U、D 和 V。矩阵 A 由原始 x * y 元素组成,而矩阵 U 由元素 X * X 组成(它是正交矩阵)。 矩阵 V 是包含 y * y 元素的不同正交矩阵。 矩阵 D 包含元素 x * y,它是一个对角矩阵。
为了分解矩阵 A 的值,我们需要将原始奇异矩阵值转换为新矩阵中找到的对角线值。 使用正交矩阵时,即使乘以其他数字,它们的属性也不会改变。 因此,我们可以利用这个性质来近似矩阵A。 当我们将正交矩阵与矩阵 V 的转置相乘时,结果是与原始 A 等效的矩阵。
当矩阵 a 分解为矩阵 U、D 和 V 时,它们包含矩阵 A 中找到的数据。但是,矩阵的最左边的列将包含大部分数据。 我们可以只取前几列,并得到矩阵 A 的表示形式,该矩阵的维度要少得多,并且 A 中包含大部分数据。
线性判别分析
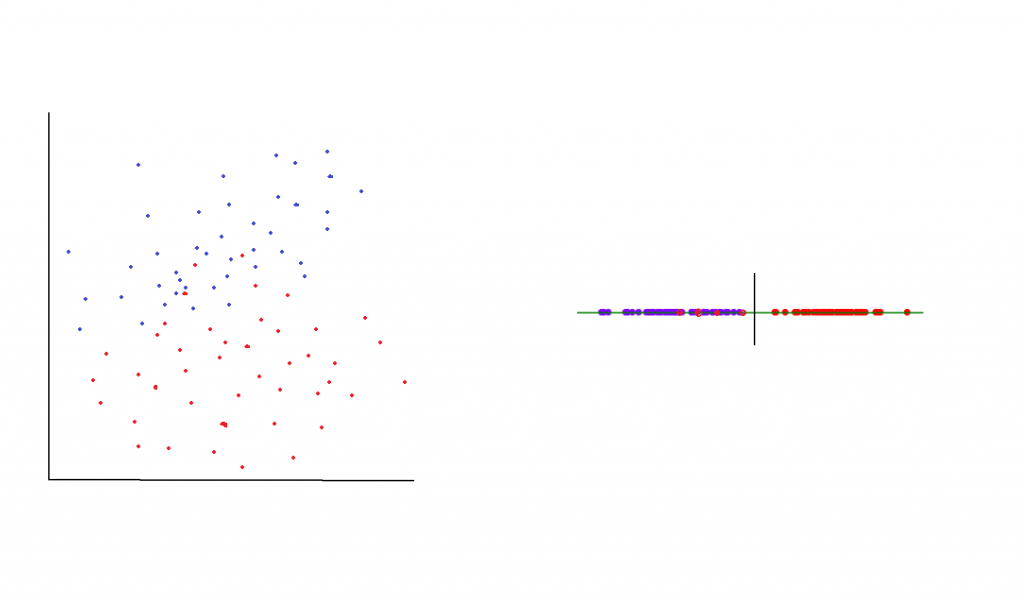
左:LDA 之前的矩阵,右:LDA 之后的轴,现在可分离
线性判别分析(LDA) 是一个从多维图中获取数据的过程 将其重新投影到线性图上。 您可以通过考虑一个充满属于两个不同类的数据点的二维图来想象这一点。 假设这些点分散在各处,因此无法绘制出能够整齐地分隔两个不同类的线。 为了处理这种情况,可以将二维图中找到的点简化为一维图(一条线)。 这条线将分布所有数据点,并且有望将其分为两部分,以实现数据的最佳分离。
执行 LDA 时有两个主要目标。 第一个目标是最小化类别的方差,而第二个目标是最大化两个类别的均值之间的距离。 这些目标是通过创建将存在于二维图中的新轴来实现的。 新创建的轴用于根据前面描述的目标分隔两个类。 创建轴后,在 2D 图中找到的点将沿轴放置。
将原始点沿新轴移动到新位置需要三个步骤。 第一步,使用各个类之间的距离均值(类间方差)来计算类的可分离性。 在第二步中,通过确定相关类别的样本与平均值之间的距离来计算不同类别内的方差。 在最后一步中,创建最大化类之间方差的低维空间。
当目标类的均值彼此相距较远时,LDA 技术可获得最佳结果。 如果分布的均值重叠,LDA 无法使用线性轴有效地分离类别。