摄影网址网站优化哪家好
Meta AI 在本周二发布了最新一代开源大模型 Llama 2。对比于今年 2 月发布的 Llama 1,训练所用的 token 翻了一倍,已经达到了 2 万亿,对于使用大模型最重要的上下文长度限制,Llama 2 也翻了一倍。
在本文,我们将紧跟趋势介绍如何在本地CPU推理上运行量化版本的开源Llama 2。

量化快速入门
我们首先简单介绍一下量化的概念:
量化是一种减少用于表示数字或值的比特数的技术。由于量化减少了模型大小,因此它有利于在cpu或嵌入式系统等资源受限的设备上部署模型。
一种常用的方法是将模型权重从原始的16位浮点值量化为精度较低的8位整数值。

llm已经展示了出色的能力,但是它需要大量的CPU和内存,所以我们可以使用量化来压缩这些模型,以减少内存占用并加速计算推理,并且保持模型性能。我们将通过将权重存储在低精度数据类型中来降低模型参数的精度。
工具和数据
下图是我们将在这个项目中构建的文档知识问答应用程序的体系结构。

我们的测试文件是177页的曼联足球俱乐部2022年年报。
为了演示这个项目的量化结果,我们使用一个AMD Ryzen 5 5600X 6核处理器和16GB RAM (DDR4 3600)。
下面是构建这个应用程序时将使用的软件工具:
1、LangChain
LangChain是一个提供了一组广泛的集成和数据连接器,允许我们链接和编排不同的模块。可以常见聊天机器人、数据分析和文档问答等应用。
2、C Transformers
C transformer是一个Python库,它为使用GGML库并在C/ c++中实现了Transformers模型。
为了解释这个事情我们首先要了解GGML:
GGML库是一个为机器学习设计的张量库,它的目标是使大型模型能够在高性能的消费级硬件上运行。这是通过整数量化支持和内置优化算法实现的。
也就是说,llm的GGML版本(二进制格式的量化模型)可以在cpu上高性能地运行。因为我们最终是使用Python的,所以还需要C Transformers库,它其实就是为GGML模型提供了Python API。
C transformer支持一组选定的开源模型,包括像Llama、GPT4All-J、MPT和Falcon等的流行模型。

3、sentence-transformer
sentence-transformer提供了简单的方法来计算句子、文本和图像的嵌入。它能够计算100多种语言的嵌入。我们将在这个项目中使用开源的all-MiniLM-L6-v2模型。
4、FAISS
Facebook AI相似度搜索(FAISS)是一个为高效相似度搜索和密集向量聚类而设计的库。
给定一组嵌入,我们可以使用FAISS对它们进行索引,然后利用其强大的语义搜索算法在索引中搜索最相似的向量。
虽然它不是传统意义上的成熟的向量存储(如数据库管理系统),但它以一种优化的方式处理向量的存储,以实现有效的最近邻搜索。
5、Poetry
Poetry用于设置虚拟环境和处理Python包管理。相比于venv,Poetry使依赖管理更加高效和无缝。这个不是只做参考,因为conda也可以。
开源LLM
开源LLM领域已经取得了巨大的进步,在HuggingFace的开放LLM排行榜上可以找到模型。为了紧跟时代,我们选择了最新的开源Llama-2-70B-Chat模型(GGML 8位):
1、Llama 2
它是C Transformers库支持的开源模型。根据LLM排行榜排名(截至2023年7月),在多个指标中表现最佳。在原来的Llama 模型设定的基准上有了巨大的改进。
2、模型尺寸:7B
LLM将主要用于总结文档块这一相对简单的任务。因此选择了7B模型,因为我们在技术上不需要过大的模型(例如65B及以上)来完成这项任务。
3、微调版:Llama-2-7B-Chat
lama-2- 7b基本模型是为文本补全而构建的,因此它缺乏在文档问答用例中实现最佳性能所需的微调。而lama-2 - 7b - chat模型是我们的理想候选,因为它是为对话和问答而设计的。该模型被许可(部分)用于商业用途。这是因为经过微调的模型lama-2- chat模型利用了公开可用的指令数据集和超过100万个人工注释。
4、8位量化
考虑到RAM被限制为16GB, 8位GGML版本是合适的,因为它只需要9.6GB的内存而原始的非量化16位模型需要约15gb的内存
8位格式也提供了与16位相当的响应质量,而其他更小的量化格式(即4位和5位)是可用的,但它们是以准确性和响应质量为代价的。
构建步骤指导
我们已经了解了各种组件,接下来让逐步介绍如何构建文档问答应用程序。
由于已经有许多教程了,所以我们不会深入到复杂和一般的文档问答组件的细节(例如,文本分块,矢量存储设置)。在本文中,我们将把重点放在开源LLM和CPU推理方面。
1、数据处理和矢量存储
这一步的任务是:将文本分割成块,加载嵌入模型,然后通过FAISS 进行向量的存储
from langchain.vectorstores import FAISSfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.document_loaders import PyPDFLoader, DirectoryLoaderfrom langchain.embeddings import HuggingFaceEmbeddings# Load PDF file from data pathloader = DirectoryLoader('data/',glob="*.pdf",loader_cls=PyPDFLoader)documents = loader.load()# Split text from PDF into chunkstext_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)texts = text_splitter.split_documents(documents)# Load embeddings modelembeddings = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2',model_kwargs={'device': 'cpu'})# Build and persist FAISS vector storevectorstore = FAISS.from_documents(texts, embeddings)vectorstore.save_local('vectorstore/db_faiss')
运行上面的Python脚本后,向量存储将被生成并保存在名为’vectorstore/db_faiss’的本地目录中,并为语义搜索和检索做好准备。
2、设置提示模板
我们使用lama-2 - 7b - chat模型,所以需要使用的提示模板。
一些chat的模板在这里不起作用,因为我们的Llama 2模型没有针对这种会话界面进行专门优化。所以我们需要使用更加直接的模板,例如:
qa_template = """Use the following pieces of information to answer the user's question.If you don't know the answer, just say that you don't know, don't try to make up an answer.Context: {context}Question: {question}Only return the helpful answer below and nothing else.Helpful answer:"""
需要注意的是,相对较小的LLM(如7B),对格式特别敏感。当改变提示模板的空白和缩进时,可能得到了稍微不同的输出。
3、下载lama-2 - 7b - chat GGML二进制文件
由于我们将在本地运行LLM,所以需要下载量化的lama-2 - 7b - chat模型的二进制文件。
我们可以通过访问TheBloke的Llama-2-7B-Chat GGML页面来实现,然后下载名为Llama-2-7B-Chat .ggmlv3.q8_0.bin的GGML 8位量化文件。

下载的是8位量化模型的bin文件可以保存在合适的项目子文件夹中,如/models。
这个页面还显示了每种量化格式的更多信息和详细信息:

4、LangChain集成
我们将利用C transformer和LangChain进行集成。也就是说将在LangChain中使用CTransformers LLM包装器,它为GGML模型提供了一个统一的接口。
from langchain.llms import CTransformers# Local CTransformers wrapper for Llama-2-7B-Chatllm = CTransformers(model='models/llama-2-7b-chat.ggmlv3.q8_0.bin', # Location of downloaded GGML modelmodel_type='llama', # Model type Llamaconfig={'max_new_tokens': 256,'temperature': 0.01})
这里就可以为LLM定义大量配置设置,例如最大令牌、最高k值、温度和重复惩罚等等,这些参数在我们以前的文章已经介绍过了。
这里我将温度设置为0.01而不是0,因为设置成0时,得到了奇怪的响应。
5、构建并初始化RetrievalQA
准备好提示模板和C Transformers LLM后,我们还需要编写了三个函数来构建LangChain RetrievalQA对象,该对象使我们能够执行文档问答。
from langchain import PromptTemplatefrom langchain.chains import RetrievalQAfrom langchain.embeddings import HuggingFaceEmbeddingsfrom langchain.vectorstores import FAISS# Wrap prompt template in a PromptTemplate objectdef set_qa_prompt():prompt = PromptTemplate(template=qa_template,input_variables=['context', 'question'])return prompt# Build RetrievalQA objectdef build_retrieval_qa(llm, prompt, vectordb):dbqa = RetrievalQA.from_chain_type(llm=llm,chain_type='stuff',retriever=vectordb.as_retriever(search_kwargs={'k':2}),return_source_documents=True,chain_type_kwargs={'prompt': prompt})return dbqa# Instantiate QA objectdef setup_dbqa():embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2",model_kwargs={'device': 'cpu'})vectordb = FAISS.load_local('vectorstore/db_faiss', embeddings)qa_prompt = set_qa_prompt()dbqa = build_retrieval_qa(llm, qa_prompt, vectordb)return dbqa
6、代码整合
最后一步就是是将前面的组件组合到main.py脚本中。使用argparse模块是因为我们将从命令行将用户查询传递到应用程序中。
这里为了评估CPU推理的速度,还使用了timeit模块。
import argparseimport timeitif __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument('input', type=str)args = parser.parse_args()start = timeit.default_timer() # Start timer# Setup QA objectdbqa = setup_dbqa()# Parse input from argparse into QA objectresponse = dbqa({'query': args.input})end = timeit.default_timer() # End timer# Print document QA responseprint(f'\nAnswer: {response["result"]}')print('='*50) # Formatting separator# Process source documents for better displaysource_docs = response['source_documents']for i, doc in enumerate(source_docs):print(f'\nSource Document {i+1}\n')print(f'Source Text: {doc.page_content}')print(f'Document Name: {doc.metadata["source"]}')print(f'Page Number: {doc.metadata["page"]}\n')print('='* 50) # Formatting separator# Display time taken for CPU inferenceprint(f"Time to retrieve response: {end - start}")
示例查询
现在是时候对我们的应用程序进行测试了。我们用以下命令询问阿迪达斯(曼联的全球技术赞助商)应支付的最低保证金额:
python main.py "How much is the minimum guarantee payable by adidas?"
结果如下:
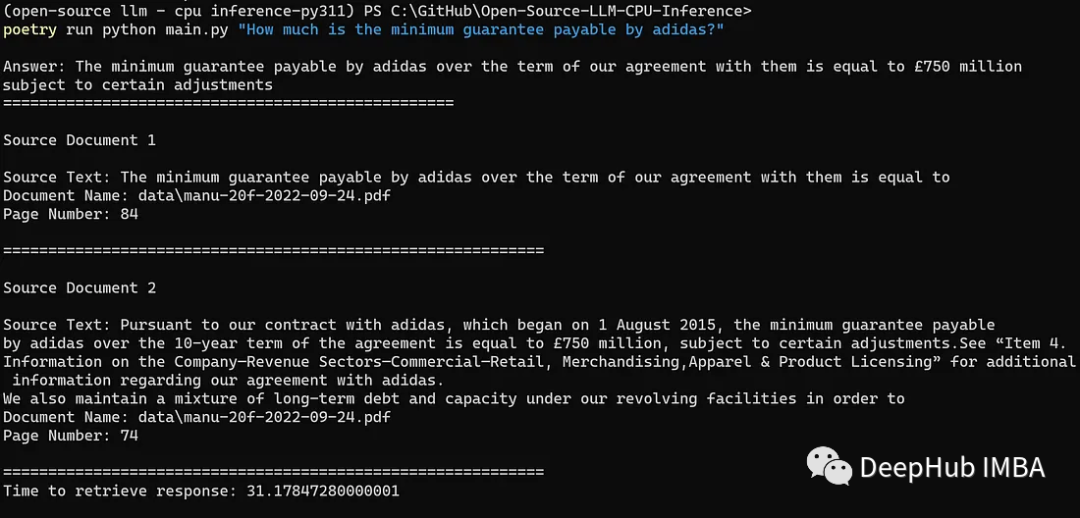
我们成功地获得了正确响应(即£7.5亿),以及语义上与查询相似的相关文档块。
从启动应用程序并生成响应的总时间为31秒,这是相当不错的,因为这只是在AMD Ryzen 5600X(中低档的消费级CPU)上本地运行它。并且在gpu上运行LLM推理(例如,直接在HuggingFace上运行)也需要两位数的时间,所以在CPU上量化运行的结果是非常不错的。
作者:Kenneth Leung
相关资源
https://avoid.overfit.cn/post/9df8822ed2854176b68585226485ee0f