合肥论坛建站模板网络推广网址
前言
本文是mysql连接池的实现。学完mysql连接池之后,接下来会结合多线程来进行测试,看看使用连接池性能高,还是不要连接池性能高,具体能差多少。当然这是下一篇文章了哈哈哈哈哈。当前首要任务是学会连接池,会都不会,还用个啥哈哈哈哈。
一、池化技术
池化技术能够减少资源对象的创建次数,提高程序的响应性能,特别是在高并发下这种提高更加明显。
使用池化技术缓存的资源对象有如下共同特点:
- 对象创建时间长;
- 对象创建需要大量资源;
- 对象创建后可被重复使用;
就比如线程池,创建线程和销毁线程是比较耗时间的,那么我们是不是就可以创建一堆线程
放到一起去管理,等有任务到来的时候再从池子里找一个空闲的线程池去处理任务,这样是
不是提升了效率,虽然这样牺牲了一点空间,但是随着计算机的发展,内存并不是问题,大
的问题是计算机的处理能力,因为现今的计算机的处理能力很难再提升了,所以我们需要在
空间和效率方面选择效率,因为空间很容易提升,但是处理能力很难提示,所以我们需要池
式组件。
像常见的线程池、内存池、连接池、对象池都具有以上的共同特点。
我们在学mysql连接池里就拿线程池来说一下:
1.线程创建时间慢并且创建需要大量资源,因为他要陷入内核,然后cpu调度,并且也要分配一个task struct和线程私有栈,独立上下文(void* argc)
这些都是线程私有的
二、什么是数据库连接池
定义:数据库连接池(Connection pooling)是程序启动时建立足够的数据库连接,并将这些连接组成
一个连接池,由程序动态地对池中的连接进行申请,使用,释放。
大白话:创建数据库连接是一个很耗时的操作,也容易对数据库造成安全隐患。所以,在程序初始化的
时候,集中创建多个数据库连接,并把他们集中管理,供程序使用,可以保证较快的数据库读写速度,
还更加安全可靠。
这里讲的数据库,不单只是指Mysql,也同样适用于Redis。
其实在简单的一点说就是用一个池子保存已收到的mysql连接,并且该连接没有被断开,
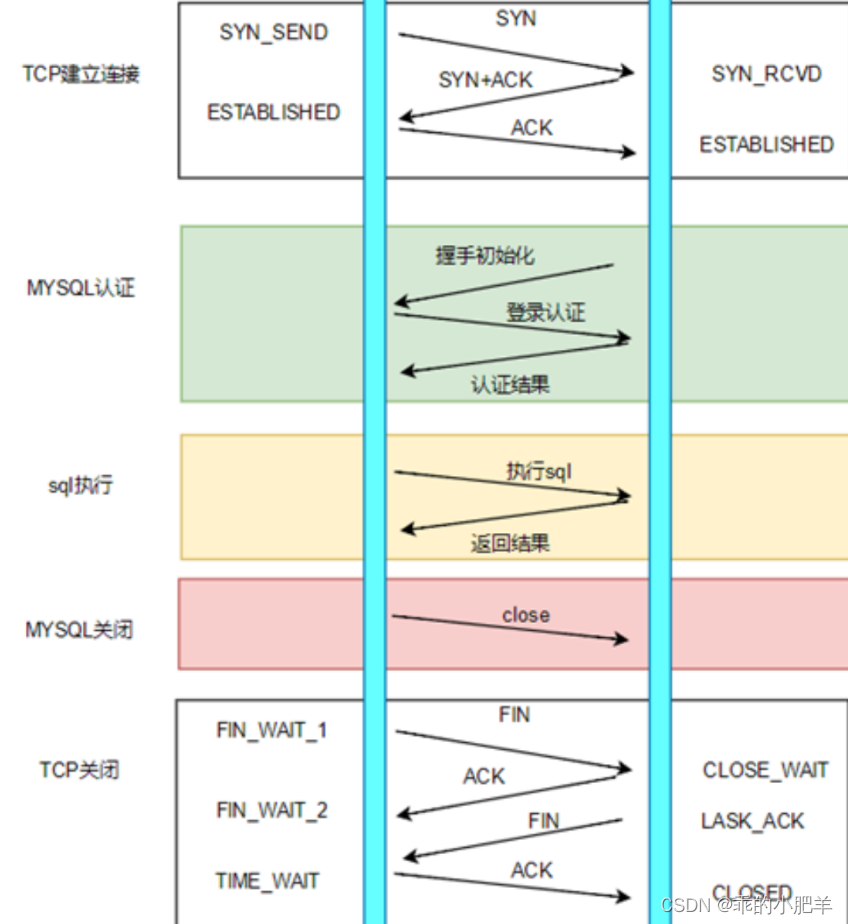
因为mysql建立连接也需要很多步骤,先要经过1.tcp三次握手,然后在2.经过mysql认证
,3.sql语句执行,4.mysql关闭,5.tcp四次挥手,
所以建立mysql连接创建时间长,并且创建和销毁需要耗费很长时间,且该sql连接可能会被经常重复使用,所以满足池式组件优化的点:
- 对象创建时间长;
- 对象创建需要大量资源;
- 对象创建后可被重复使用;
三、为什么使用数据库连接池
资源复用:
由于数据库连接得到复用,避免了频繁的创建、释放连接引起的性能开销,在减少系统消耗的基础
上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量)。
更快的系统响应速度:
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化(这些连接其实一直保持连接的---核心要点,如果不是保持连接的,那么就不算是连接池了)
工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了从数据库连接初始化和释
放过程的开销,从而缩减了系统整体响应时间。
统一的连接管理,避免数据库连接泄露:
在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而
避免了常规数据库连接操作中可能出现的资源泄露。
不使用连接池
1. TCP建立连接的三次握手(客户端与MySQL服务器的连接基于TCP协议)
2. MySQL认证的三次握手
3. 真正的SQL执行
4. MySQL的关闭
5. TCP的四次握手关闭
可以看到,为了执行一条SQL,需要进行TCP三次握手,Mysql认证、Mysql关闭、TCP四次挥手等其他
操作,执行SQL操作在所有的操作占比非常低。
优点 :实现简单 省了连接池的设计。
缺点:每一次发起SQL操作都经历TCP建立连接、数据库用户身份验证、数据库用户登出、TCP断开连接。
网络IO较多
带宽利用率低
QPS较低
应用频繁低创建连接和关闭连接,导致临时对象较多,带来更多的内存碎片
在关闭连接后,会出现大量TIME_WAIT 的TCP状态(在2个MSL之后关闭)(出现大量time_wait对客户端和服务器的影响可以看其他博主写的全方面了解TCP的文章)
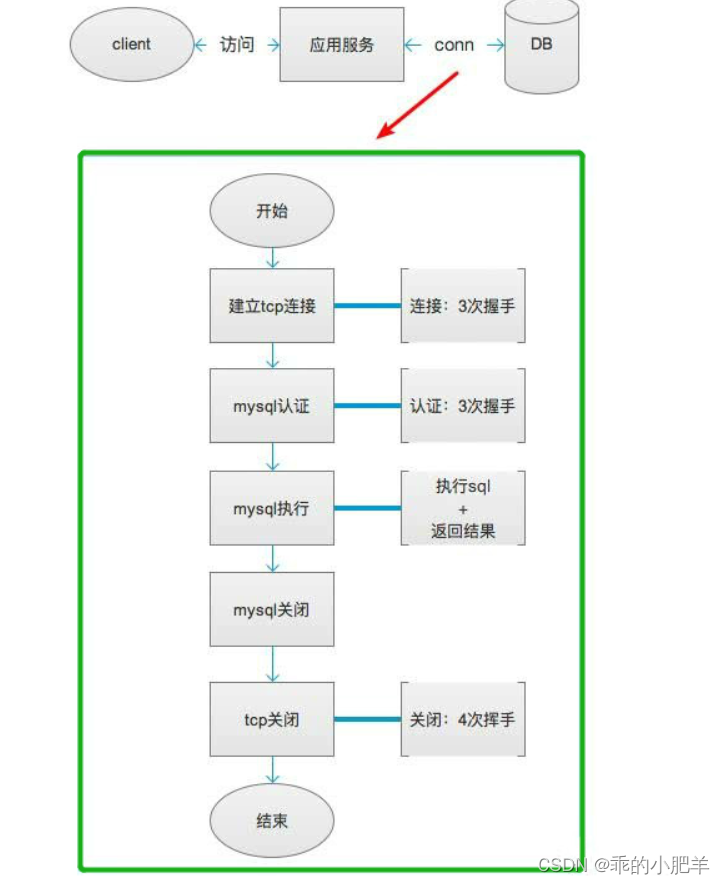
使用连接池(连接池其实是可以算作mysql本身的东西)
第一次访问的时候,需要建立连接。 但是之后的访问,均会复用之前创建的连接,直接执行SQL语句。

优点:
- 降低了网络开销
- 连接复用,有效减少连接数。
- 提升性能,避免频繁的新建连接。新建连接的开销比较大
- 没有TIME_WAIT状态的问题
缺点:
- 设计较为复杂
长连接和连接池的区别
长连接是一些驱动、驱动框架、ORM工具的特性,由驱动来保持连接句柄的打开,以便后续的数据
库操作可以重用连接,从而减少数据库的连接开销。
而连接池是应用服务器的组件,它可以通过参数来配置连接数、连接检测、连接的生命周期等。
连接池内的连接,其实就是长连接。(核心)
连接池就是长连接,但是需要把长连接放到池里面去管理
直接使用长连接的话:每个线程绑定一个连接。但是有些线程需要操作数据库,有些线程不需要操作数据库。那么在执行对应任务的时候,就需要传个参数实现,把对应的连接参数传过来,解耦性比较差。
使用连接池的话:封装任务时候,如果要操作数据库,可以直接从连接池中获取
其实朋友们不要有误区,我们前面说的的要每次连接数据库需要请求tcp三次握手,这些是基于短连接的状态,而长连接不会进行一直连接,但是长连接并没有很好的解决效率的问题,如果一个线程绑定一个连接的话,百万线程就有百万连接,那么会造成资源浪费和服务器效率降低!!
(不是放着的sql语句请求连接,而是我们的mysql连接池让我们每次向mysql服务器请求省了tcp三次握手,mysql认证,mysql关闭和tcp四次挥手这步)并不是省了sql语句这步,sql语句请求并不会发起tcp请求和mysql认证
四、数据库连接池运行机制
- 从连接池获取或创建可用连接;
- 使用完毕之后,把连接返回给连接池;
- 在系统关闭前,断开所有连接并释放连接占用的系统资源;

五、连接池和线程池的关系
连接池和线程池的区别
线程池:主动调用任务。当任务队列不为空的时候从队列取任务取执行。
比如去银行办理业务,窗口柜员是线程,多个窗口组成了线程池,柜员从排号队列叫号执行。
连接池:被动被任务使用。当某任务需要操作数据库时,只要从连接池中取出一个连接对象,当任
务使用完该连接对象后,将该连接对象放回到连接池中。如果连接池中没有连接对象可以用,那么
该任务就必须等待。
比如去银行用笔填单,笔是连接对象,我们要用笔的时候去取,用完了还回去。
连接池和线程池设置数量的关系:
一般线程池线程数量和连接池连接对象数量一致;
一般线程执行任务完毕的时候归还连接对象;
说了这么多,终于到了连接池的设计与实现了
六、连接池设计要点
使用连接池需要预先建立数据库连接。
连接池设计思路:
1. 连接到数据库,涉及到数据库ip、端口、用户名、密码、数据库名字等;
a. 连接的操作,每个连接对象都是独立的连接通道,它们是独立的 **(长连接)**
b. 配置最小连接数和最大连接数 (同时并发多个线程,有的要操作数据库,有的不需要)
2. 需要一个队列管理他的连接,比如使用list;
3. 获取连接对象:
4. 归还连接对象;
5. 连接池的名字 (便于扩展,可以划分不同的数据库)
连接池设计逻辑
其实就是创建多个连接对象,用一个队列存起来(空闲队列),当要用连接对象操作数据库的时候,就把存起来的对象拿出来用(获取连接),并把它移除,放到存储使用对象的容器中(使用队列)。当用完它之后,就把它从使用队列中移除,放到空闲队列中,等着让其他想要操场数据库的线程接着使用,避免了频繁的创建和销毁。当系统运行完毕,把所有创建的对象统一销毁即可。
构造函数
设计思路图:

CDBPool::CDBPool(const char *pool_name, const char *db_server_ip, uint16_t db_server_port,const char *username, const char *password, const char *db_name, int max_conn_cnt)
{m_pool_name = pool_name;m_db_server_ip = db_server_ip;m_db_server_port = db_server_port;m_username = username;m_password = password;m_db_name = db_name;m_db_max_conn_cnt = max_conn_cnt; // m_db_cur_conn_cnt = MIN_DB_CONN_CNT; // 最小连接数量
}

初始化
设计思路图:

代码实现:
int CDBPool::Init()
{// 创建固定最小的连接数量for (int i = 0; i < m_db_cur_conn_cnt; i++){CDBConn *pDBConn = new CDBConn(this);int ret = pDBConn->Init();if (ret){delete pDBConn;return ret;}m_free_list.push_back(pDBConn);}// log_info("db pool: %s, size: %d\n", m_pool_name.c_str(), (int)m_free_list.size());return 0;
}请求获取连接
设计思路图:
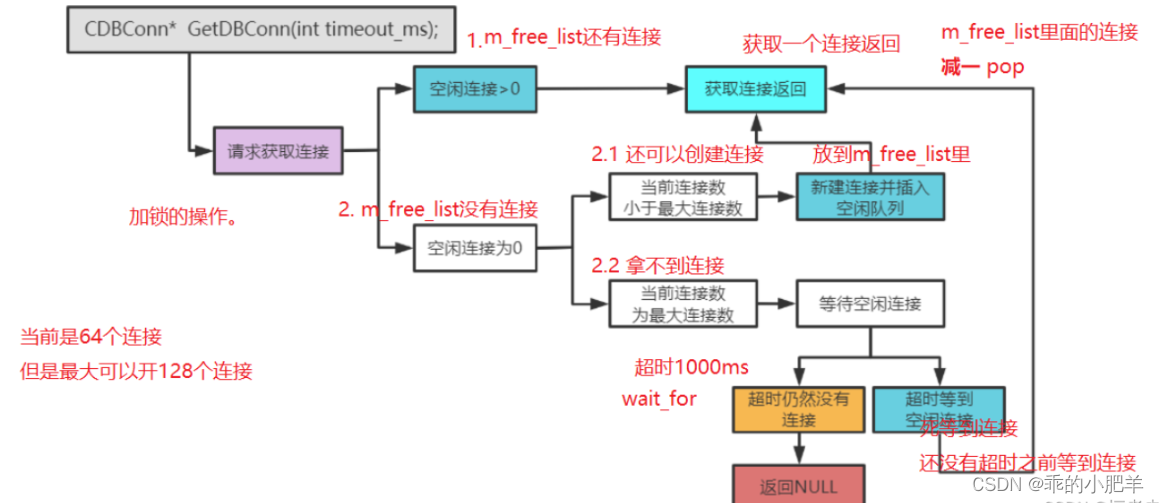
CDBConn *CDBPool::GetDBConn(const int timeout_ms)
{std::unique_lock<std::mutex> lock(m_mutex);if(m_abort_request) {log_warn("have aboort\n");return NULL;}if (m_free_list.empty()) // 当没有连接可以用时{// 第一步先检测 当前连接数量是否达到最大的连接数量 if (m_db_cur_conn_cnt >= m_db_max_conn_cnt){// 如果已经到达了,看看是否需要超时等待if(timeout_ms <= 0) // 死等,直到有连接可以用 或者 连接池要退出{log_info("wait ms:%d\n", timeout_ms);m_cond_var.wait(lock, [this] {// log_info("wait:%d, size:%d\n", wait_cout++, m_free_list.size());// 当前连接数量小于最大连接数量 或者请求释放连接池时退出return (!m_free_list.empty()) | m_abort_request;});} else {// return如果返回 false,继续wait(或者超时), 如果返回true退出wait// 1.m_free_list不为空// 2.超时退出// 3. m_abort_request被置为true,要释放整个连接池m_cond_var.wait_for(lock, std::chrono::milliseconds(timeout_ms), [this] {// log_info("wait_for:%d, size:%d\n", wait_cout++, m_free_list.size());return (!m_free_list.empty()) | m_abort_request;});// 带超时功能时还要判断是否为空if(m_free_list.empty()) // 如果连接池还是没有空闲则退出{return NULL;}}if(m_abort_request) {log_warn("have aboort\n");return NULL;}}else // 还没有到最大连接则创建连接{CDBConn *pDBConn = new CDBConn(this); //新建连接int ret = pDBConn->Init();if (ret){log_error("Init DBConnecton failed\n\n");delete pDBConn;return NULL;}else{m_free_list.push_back(pDBConn);m_db_cur_conn_cnt++;// log_info("new db connection: %s, conn_cnt: %d\n", m_pool_name.c_str(), m_db_cur_conn_cnt);}}}CDBConn *pConn = m_free_list.front(); // 获取连接m_free_list.pop_front(); // STL 吐出连接,从空闲队列删除// pConn->setCurrentTime(); // 伪代码m_used_list.push_back(pConn); // return pConn;
}
这里主要说下当当前连接数为最大连接数时的两步操作。
一共设计了两种等待方式,根据传的 计量时间(timeout_ms) 来判断,如果timeout_ms<=0,则表明我选择死等的方式,即一直阻塞等待,止到有空闲连接为止
否则,timeout_ms>0,则表示等待阻塞这么长时间,如果超过了这么长时间,还么空闲连接,直接返回NULL即可。
归还连接
设计思路图:

void CDBPool::RelDBConn(CDBConn *pConn)
{std::lock_guard<std::mutex> lock(m_mutex);list<CDBConn *>::iterator it = m_free_list.begin();for (; it != m_free_list.end(); it++) // 避免重复归还{if (*it == pConn) {break;}}if (it == m_free_list.end()){m_used_list.remove(pConn);m_free_list.push_back(pConn);m_cond_var.notify_one(); // 通知取队列} else {log_error("RelDBConn failed\n");}
}
这里notify_one()指唤醒死等阻塞和超时阻塞等待哪里
即这里的notify_one()唤醒请求获取连接中的wait和wait_for()。这是一对。通过写博客瞬间又有了一种我懂了的感觉哈哈哈哈。复现完代码了,我还以为是唤醒多线程(线程池)那里的wait呢哈哈哈哈,浅薄了
析构连接池
设计思路图:
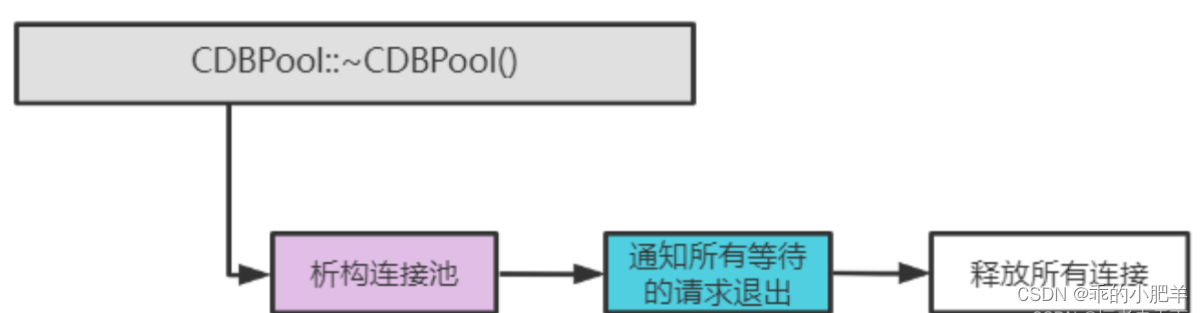
// 释放连接池
CDBPool::~CDBPool()
{std::lock_guard<std::mutex> lock(m_mutex);m_abort_request = true;m_cond_var.notify_all(); // 通知所有在等待的for (list<CDBConn *>::iterator it = m_free_list.begin(); it != m_free_list.end(); it++){CDBConn *pConn = *it;delete pConn;}m_free_list.clear();
}
释放掉所有的连接对象。
不知道你看,刚开始定义变量和获取连接方法 实现的时候对bool类型的m_abort_request是否有过疑惑啊。我去这个变量是干啥的啊,有啥用啊。怎么完全看不懂啊。
当看到这里析构函数的时候,哦是不是明白了,m_abort_request默认为false,当它为true的时候代表,连接池释放退出。哈哈哈,到这里连接池基本已经实现完成了。