西安都蓝网站建设百度免费打开
文章目录
- (55)HDFS 写数据流程
- (56) 节点距离计算
- (57)机架感知(副本存储节点选择)
- (58)HDFS 读数据流程
- 参考文献
(55)HDFS 写数据流程
数据文件ss.avi是如何从客户端写到HDFS的?
完整流程见下图,接下来我们会按顺序详细捋一下
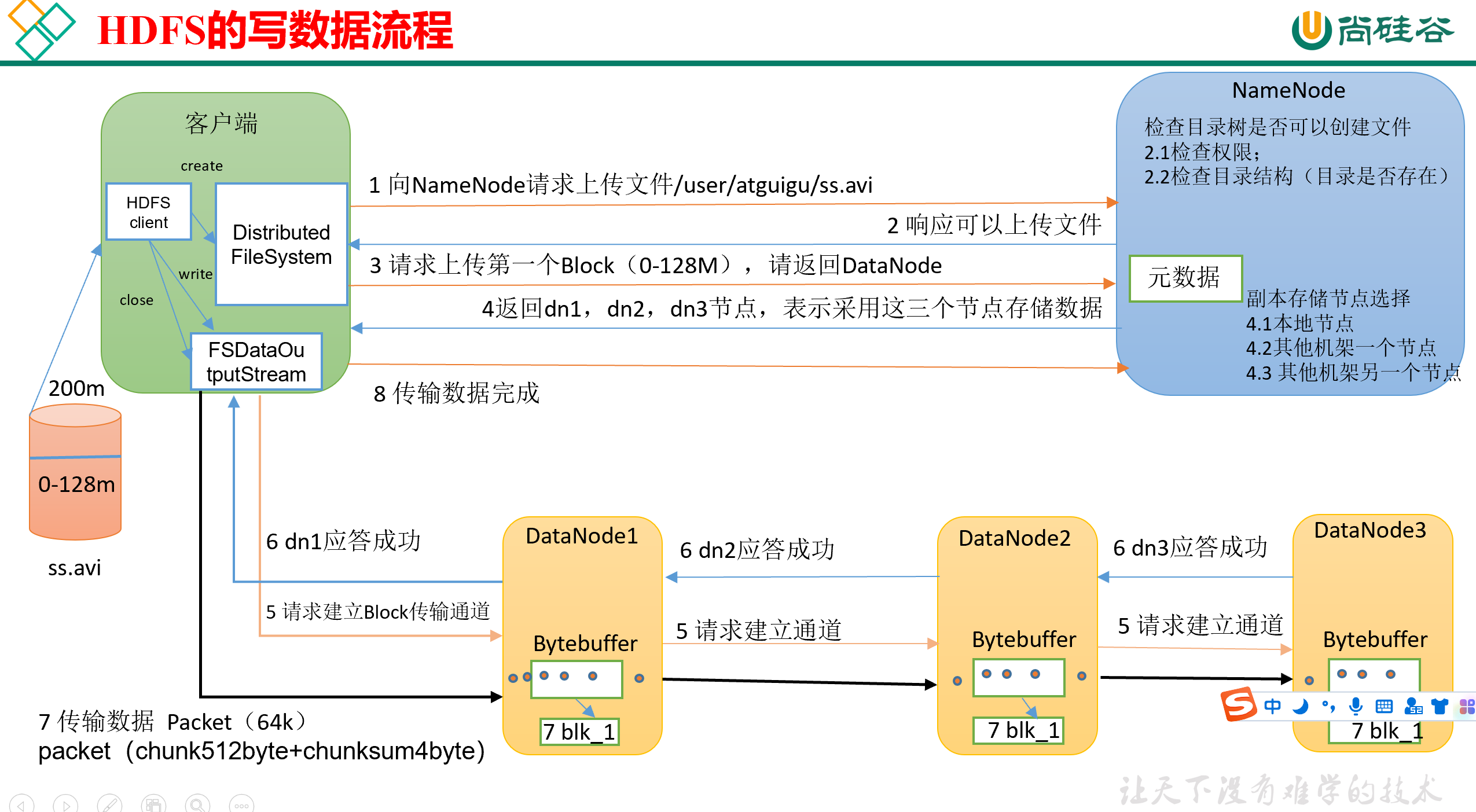
0)首先,客户端里需要有一个HDFS Client,这个HDFS客户端在创建的时候需要限制是Distributed FileSystem。(因为HDFS Client有很多种类型,默认是Local的)。
1)其次,向NameNode发送请求,请求将文件ss.avi发送到NameNode的指定目录下,这里假定是/user/atguigu/。
2)NameNode接收请求,并针对本次请求进行检查:
- 检查该客户端是否有权限在指定目录下写文件;
- 检查指定的目录树是否存在
然后,NameNode检查完之后,发回响应,通知Client可以上传文件。
3)再然后,Client接收到响应,请求上传第一个Block(0M~128M),要求NameNode返回存储用的DataNode位置。(即请求NameNode告知我应该往哪儿存)
4)接着,NameNode接收到请求,开始寻找合适的DataNode,并将其返回。默认情况下,HDFS是保留3个副本,因此会返回3个DataNode。
这里需要注意,NameNode挑选DataNode的时候,是有一个基本策略的,在3.x中,优先级从高到低是:
- 本地节点
- 其它机架的一个节点
- 其它机架(跟第二个相同)的另一个节点
而在2.x版本中,是按照:
- 本地节点
- 本地机架的另一个节点
- 其它机架的一个节点
这个之后会详细说明。
同时,DataNode的挑选也遵守负载均衡,某个节点存放的数据也不能过多。
5)再其次,Client接收到NameNode返回的DataNode名单之后,就会创建FSDataOutputStream,向名单里的DataNode写数据。
那Client具体是怎么往DataNode里写的呢?
Client只跟DataNode1建立Block传输通道,然后DataNode1跟DataNode2建立传输通道,DataNode2跟DataNode3建立传输通道,整个过程是一个串联的。
传输通道中,每次发送的数据量是一个Packet(64K),一个Packet包含若干个chunk(512B)+chunksum(4B的校验位)的组合,当一个Packet的大小达到了64K之后(chunk组合的数量够了),就可以发送了。
Client发送一个Packet之后,还会维护一个ACK缓冲队列,在里面备份刚才发送的Packet。
每次发送了一个packet之后,各个DataNode要按顺序返回应答。待到Client接收到最后的应答之后,就认为这个packet传输完成了,就会从ACK缓冲队列中删掉这个packet的备份。如果传输失败,则从ack队列中缓冲读取,继续发送。
为了加快传输速度,DataNode内部是边读边传边写,一边从管道里读一个Packet,一边往磁盘里写一个Packet,一边把内存中的Packet直接传给下面的DataNode。
6)当一个block传输完成后,客户端会再次请求NameNode上传第二个block,即从第3步开始重复执行,直到最后数据传输完成。
(56) 节点距离计算
在选择副本存储节点的时候,主要考虑节点的距离(越近越好) + 负载均衡(单个节点总负载不能太高)
如何计算两个服务器之间的节点距离呢?
所谓的节点距离就是,两个节点到达最近的公共祖先的距离之和。
计算距离的时候有些基本准则,跟树有些类似,整个架构的子孙关系是:
互联网 -> 集群(类似机房)-> 机架 -> 节点服务器
简单的说就是节点的直接祖先是机架,机架的直接祖先是集群。
每个节点服务器到自己机架的距离是1,到自己所在集群的距离是2,到整个互联网的距离是3。
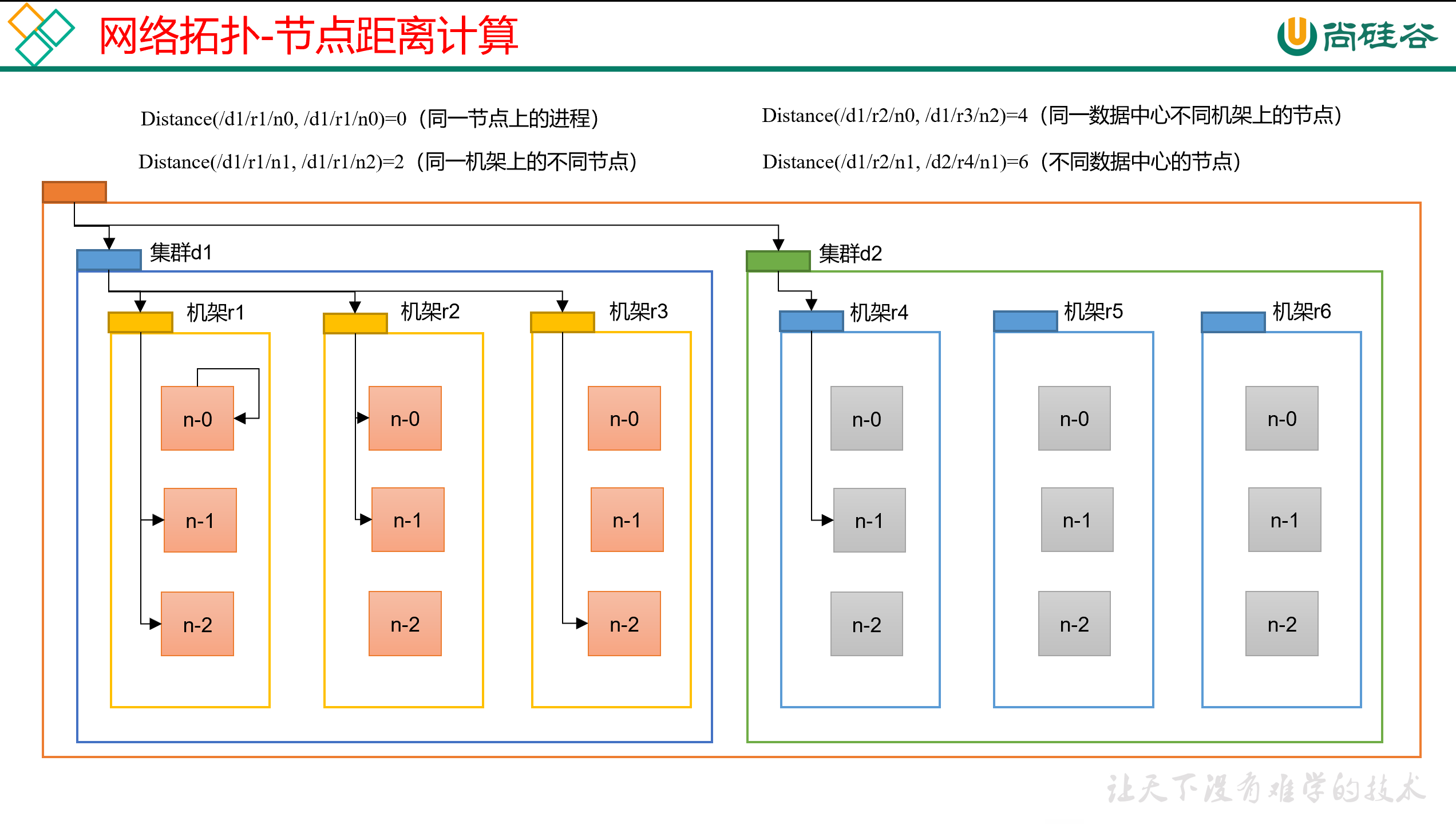
所以,结合图可见,节点间的距离其实是固定的:
- 同一节点的距离是0
- 同一机架上的两个节点,距离是2(共同祖先是机架,即节点1 -> 共同机架 -> 节点2);
- 同一集群,不同机架上的两个节点,距离是4(共同祖先是集群,即节点1 -> 机架1 -> 共同集群 -> 机架2 -> 节点2);
- 不同集群上的两个节点,距离是6(共同祖先是互联网,链路就不演示了);
(57)机架感知(副本存储节点选择)
即副本存储节点的选择策略
3.x的基本策略:
- 本地节点
- 其他机架上的一个节点(随机)
- 第二个副本所在机架上的另一个节点(随机)
所谓的本地节点,是指client的位置而言的,即client所在的节点视为是本地节点。
如果Client是在集群外,那就随便选一个节点作为本地节点。
这里其实有一个权衡,为了更加安全,所以第二个副本选择为另一个机架,防止前两个副本都在一个机架上,机架坏了,副本就没了。
但是如果是基于这种考虑,那第三个副本应该放在第3个机架上更安全啊,为什么要放在第2个机架上呢?
主要是考虑到效率问题,同机架内节点做数据传输更快,而且两个机架都出问题的情况比较少,所以就没必要那么谨慎的备份3个机架了。
(58)HDFS 读数据流程
我们有一个NameNode,和3个DataNode,现在想从DataNode下载一个ss.avi文件,完整流程见下图:
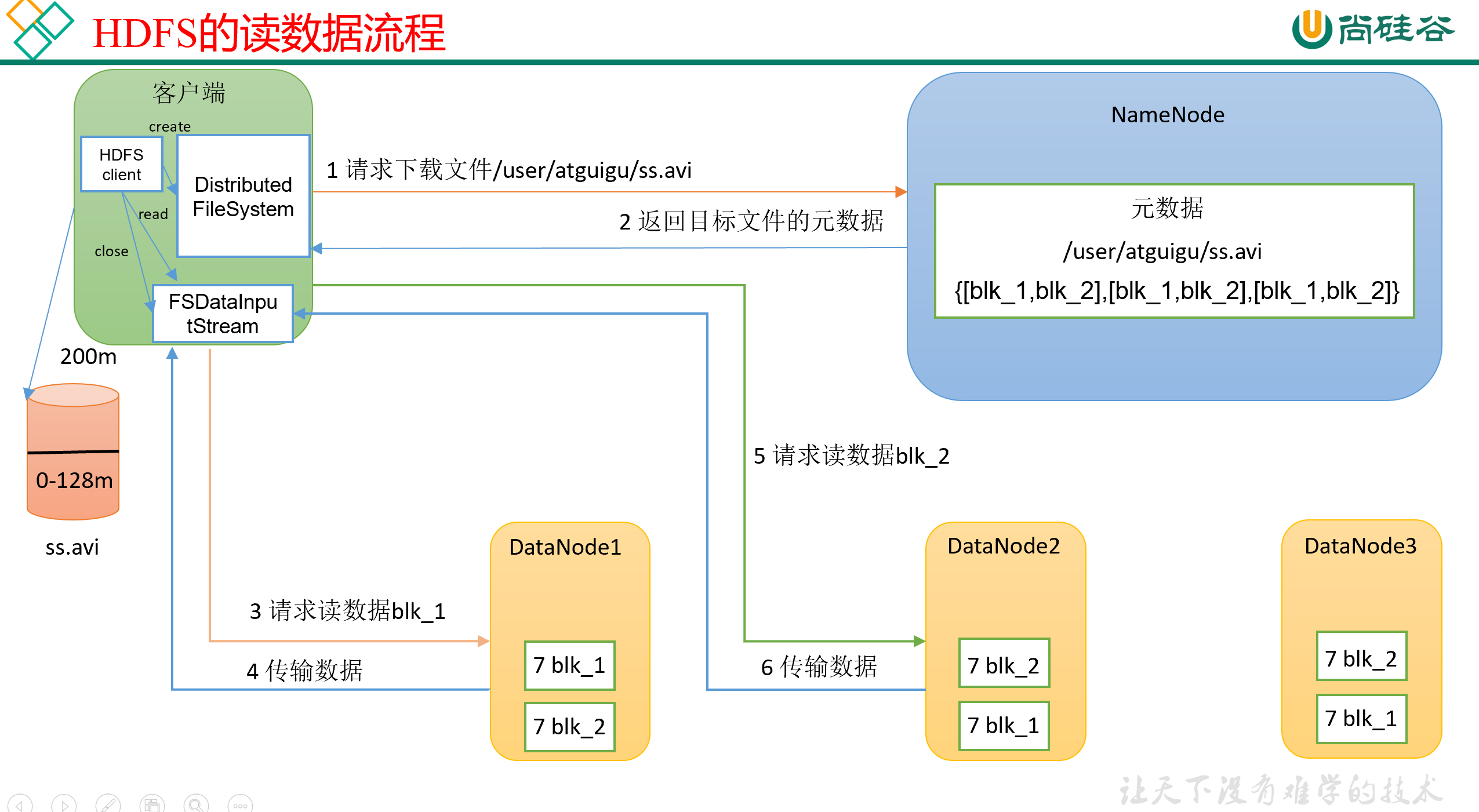
0)首先,客户端Client会生成一个Distributed FileSystem对象,来由它代表自己,对外做交互。
1)然后,Client会向NameNode发送文件的下载请求,比如说告诉它,我想下/user/atguigu/ss.avi这个文件;
2)NameNode接收到客户端的请求,然后就开始检查,自己目录里有没有这个文件、这个文件是不是这个客户端有权限下载的。如果这些检查都通过了,那么NameNode会把目标文件的元信息发送回Client。
3)Client接收到反馈,开始生成一个FSDataInputStream对象,来由它代表自己,对外建立数据传输。
注意,NameNode在反馈的时候,会把目前文件的所有副本地址都返回给Client,那 Client应该选择哪个或者哪些副本去读取呢? 这里是有两个基本原则的:
- 一般是选择节点距离最近的那个副本节点。
- 负载均衡。每个节点可接受的线程数是有上限的,如果最近的节点当前的任务已经超过负载的话,那就可以换到别的副本去读,加快速度。
然后,NameNode会向指定的副本节点发送读请求。
注意:Client在读的时候是串行读,第一块读完了之后再读第二块,不是咔咔咔开多个线程,好几块一起读。
为什么不并行读呢?大概是因为并行读没法保证拼接的顺序吧。
4)客户端以Packet为单位接收,先在本地缓存,最后再写入目标文件。
参考文献
- Hadoop2.x与Hadoop3.x副本选择机制
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】