个人网站建设流程深圳互联网公司50强
第七章 共享变量
在默认情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark提供了两种类型的变量:
1)、广播变量Broadcast Variables
- 广播变量用来把变量在所有节点的内存之间进行共享,在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本;
2)、累加器Accumulators - 累加器支持在所有不同节点之间进行累加计算(比如计数或者求和);
官方文档:http://spark.apache.org/docs/2.4.5/rdd-programming-guide.html#shared-variables
7.1 广播变量
广播变量允许开发人员在每个节点(Worker or Executor)缓存只读变量,而不是在Task之间传递这些变量。使用广播变量能够高效地在集群每个节点创建大数据集的副本。同时Spark还使用高效的广播算法分发这些变量,从而减少通信的开销。
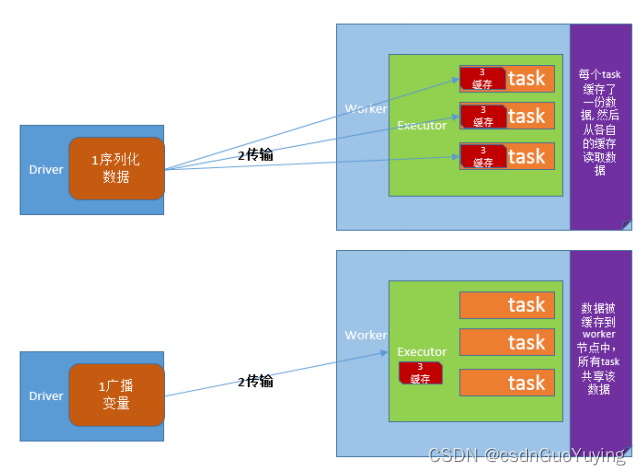
可以通过调用sc.broadcast(v)创建一个广播变量,该广播变量的值封装在v变量中,可使用获取
该变量value的方法进行访问。

7.2 累加器
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能,即确提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取Accumulator的值,只有Driver程序可以读取Accumulator的值。创建的Accumulator变量的值能够在Spark Web UI上看到,在创建时应该尽量为其命名。
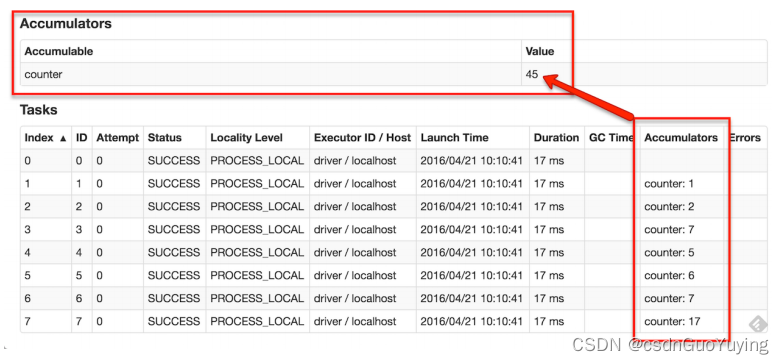
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
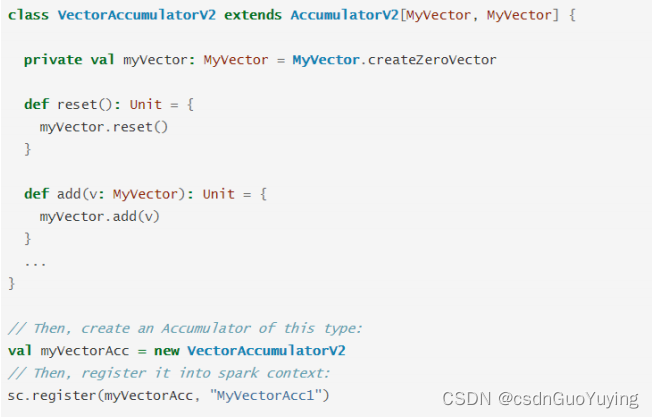
当内置的Accumulator无法满足要求时,可以继承AccumulatorV2实现自定义的累加器。实现自定义累加器的步骤:
- 第一步、继承AccumulatorV2,实现相关方法;
- 第二步、创建自定义Accumulator的实例,然后在SparkContext上注册它;
官方提供实例如下:
7.3 案例演示
以词频统计WordCount程序为例,假设处理的数据如下所示,包括非单词符合,统计数据词频时过滤非单词的符合并且统计总的格式。

实现功能:
第一、过滤非单词符合
- 非单词符合存储列表List中

- 使用广播变量广播列表

第二、累计统计非单词符号出现次数
- 定义一个LongAccumulator累加器,进行计数

范例演示完整代码如下
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
* 基于Spark框架使用Scala语言编程实现词频统计WordCount程序,将符号数据过滤,并统计出现的次数
* -a. 过滤标点符号数据
* 使用广播变量
* -b. 统计出标点符号数据出现次数
* 使用累加器
*/
object SparkSharedVariableTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// a. 读取文件数据
val datasRDD: RDD[String] = sc.textFile("datas/filter/datas.input", minPartitions = 2)
// TODO: 字典数据,只要有这些单词就过滤: 特殊字符存储列表List中
val list: List[String] = List(",", ".","!","#","$","%")
// TODO: 通过广播变量 将列表list广播到各个Executor内存中,便于多个Task使用
val listBroadcast: Broadcast[List[String]] = sc.broadcast(list)
// TODO: 定义累加器,记录单词为符号数据的个数
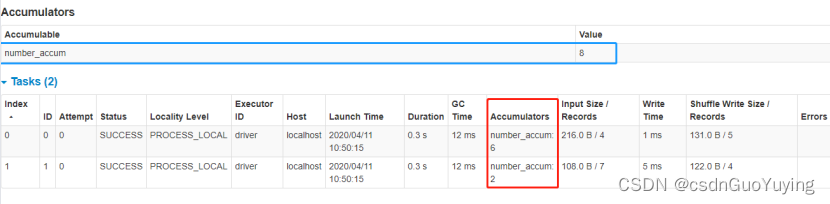
val accumulator: LongAccumulator = sc.longAccumulator("number_accum")
// b. 分割单词,过滤数据
val wordsRDD = datasRDD
// 1)、过滤数据,去除空行数据
.filter(line => null != line && line.trim.length > 0)
// 2)、分割单词
.flatMap(line => line.trim.split("\\s+"))
// 3)、过滤字典数据:符号数据
.filter{word =>
// 获取符合列表 TODO: 从广播变量中获取列表list的值
val listValue = listBroadcast.value
// 判断单词是否为符号数据,如果是就过滤掉
val isFlag = listValue.contains(word)
if(isFlag){
// TODO: 如果单词为符号数据,累加器加1
accumulator.add(1L)
}
!isFlag
}
val resultRDD: RDD[(String, Int)] = wordsRDD
// 转换为二元组
.mapPartitions{iter => iter.map(word => (word, 1))}
// 按照单词聚合统计
.reduceByKey((tmp, item) => tmp + item)
resultRDD.foreach(println)
println(s"过滤符合数据的个数:${accumulator.value}")
// 应用程序运行结束,关闭资源
sc.stop()
}
}
运行应用,查看WEB UI监控,定义累加器的值: