网站建设三要素口碑推广
一、requests模块简介
requests模块是一个第三方模块,需要在python环境中安装:
pip install requests
该模块主要用来发送 HTTP 请求,requests 模块比 urllib 模块更简洁。
requests模块支持:
- 自动处理url编码
- 自动处理post请求参数
- 支持文件上传
- 支持自动响应内容的编码
- 自动实现持久连接keep-alive
- 简化cookie和代理操作等
1、基本步骤
requests模块使用的基本步骤:
# 导入模块
import requests# 目标url
url = 'https://www.baidu.com'# 向目标url发送请求方法。比如:get/post等
response = requests.get(url)# 打印响应内容
print(response.ok) # True
print(response.status_code) # 200
print(response.url) # https://www.baidu.com/
print(response.apparent_encoding) # utf-8
print(response.text)
print(response.content.decode())
2、requests方法
requests的请求方法有:
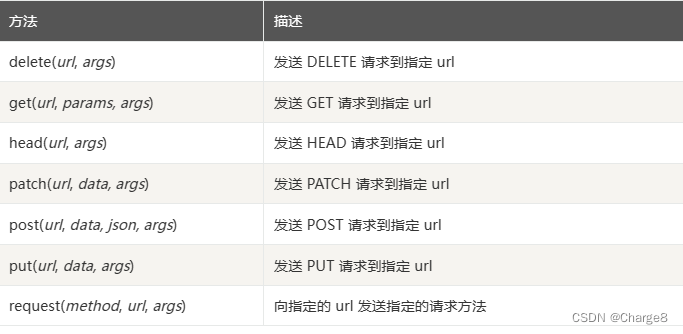
参数说明:
- method:请求方法。
- url:请求url。
- params:请求url参数。比如:get参数。
- data:请求要发送到指定 url 的字典、元组列表、字节或文件对象等。比如:post参数数据。
- json:请求要发送到指定 url 的 JSON 对象。比如:post参数数据。
- args:请求其他属性参数。比如 cookies、headers、verify、timeout等。
常见 args请求属性如下:
- headers:请求头。
- cookies:请求cookies
- timeout:设置响应超时时间。
- verify:这是本次请求是否进行证书校验。
3、response对象
每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息。响应信息如下:
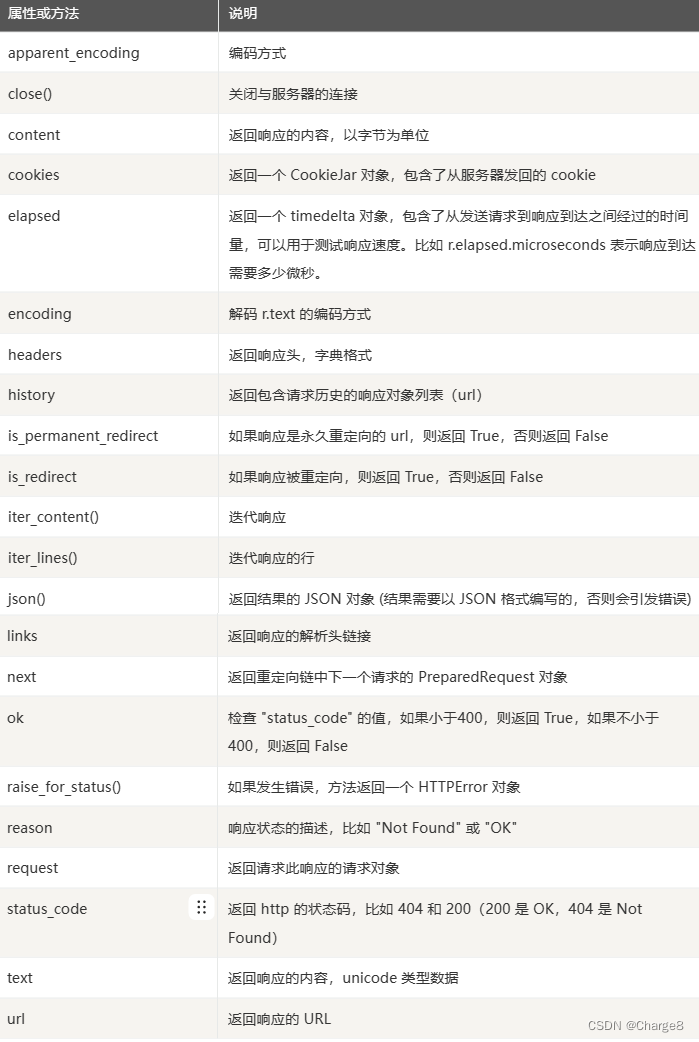
3.1 response.text和response.content 的区别
(1)response.text
response.text
- 类型:str
- 解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码。
(2)response.content
response.content
- 类型:bytes
- 解码类型: 没有指定
通过对response.content指定decode,来解决中文乱码。
response.content.decode() # 默认utf-8response.content.decode('gbk') # 指定编码
二、get请求
get() 方法可以发送 GET 请求到指定 url,一般格式如下:
response = requests.get(url, params,args)
参数说明:
- url参数:请求 url。
- params:请求参数。比如:get参数。
- args参数:请求其他属性参数,比如 cookies、headers、verify、timeout等。
1、不带参数请求
url = 'https://www.baidu.com'# 不带参数的get请求
response = requests.get(url)
2、带参数请求
2.1 url携带参数
url = 'https://www.baidu.com/?p1=python&p2=java'# url携带参数 get请求
response = requests.get(url)
print(response.url) # https://www.baidu.com/?p1=python&p2=java
2.2 构建字典参数
url = 'https://www.baidu.com'
url_params = {'p1': 'python', 'p2': None, 'p3': 'java'}# url携带字典参数 get请求,如果值为None的键不会被添加到url中
response = requests.get(url, url_params)
print(response.url) # https://www.baidu.com/?p1=python&p3=java
注意:字典传递参数,如果值为None的键都不会被添加到 url中。
三、post请求
post() 方法可以发送 POST 请求到指定 url,一般格式如下:
response = requests.post(url, data={key: value}, json={key: value}, args)
参数说明:
- url参数:请求 url。
- data参数:请求要发送到指定 url 的字典、元组列表、字节或文件对象等。
- json参数:请求要发送到指定 url 的 JSON 对象。
- args参数:请求其他属性参数,比如 cookies、headers、verify、timeout等。
1、表单参数请求
方式1:
url = 'https://www.baidu.com'
payload = {'key1': 'value1', 'key2': None, 'key3': 'value3'}# 表单参数请求
response = requests.post(url, data=payload)
print(response.url) # https://www.baidu.com/
print(response.request.body) # key1=value1&key3=value3
注意:如果值为None的键都不会被传递。
方式2:
import requests
import jsonurl = 'https://www.baidu.com'
payload = {'key1': 'value1', 'key2': None, 'key3': 'value3'}
headers = {'content-type': 'application/json'}# 表单参数请求
response = requests.post(url, data=json.dumps(payload), headers=headers)
print(response.url) # https://www.baidu.com/
print(response.request.body) # {"key1": "value1", "key2": null, "key3": "value3"}
print(response.request.headers) # {'User-Agent': 'python-requests/2.28.2', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'content-type': 'application/json', 'Content-Length': '50'}注意:如果值为None的键都会被传递,值为null。
2、Json参数请求
url = 'https://www.baidu.com'
payload = {"key1": "value1", "key2": None, "key3": "value3", "key3": 33}
headers = {'content-type': 'application/json'}response = requests.post(url, json=payload, headers=headers)
print(response.url) # https://www.baidu.com/
print(response.request.body) # b'{"key1": "value1", "key2": null, "key3": 33}'
print(response.request.headers) # {'User-Agent': 'python-requests/2.28.2', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'content-type': 'application/json', 'Content-Length': '44'}3、添加请求属性参数实例
这里添加请求 timeout,cookies,headers。
url = 'https://www.baidu.com'
payload = {"key1": "value1", "key2": None, "key3": "value3", "key3": 33}
headers = {'content-type': 'application/json'}
cookies = {'testCookies_1': 'Hello_Python3', 'testCookies_2': 'Hello_Java'}try:response = requests.post(url, json=payload, headers=headers, cookies=cookies, timeout=5)if response.status_code != 200: # 如果响应状态码不是 200,就主动抛出异常print('响应失败:status_code = ' + str(response.status_code))print('响应失败:' + str(response.reason))else:print("=====================")print(response.url) # https://www.baidu.com/print(response.request.body) # b'{"key1": "value1", "key2": null, "key3": 33}'print(response.request.headers) # {'User-Agent': 'python-requests/2.28.2', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'content-type': 'application/json', 'Cookie': 'testCookies_1=Hello_Python3; testCookies_2=Hello_Java', 'Content-Length': '44'}print(response.request._cookies) # <RequestsCookieJar[<Cookie testCookies_1=Hello_Python3 for />, <Cookie testCookies_2=Hello_Java for />]>
except requests.RequestException as e:print("请求失败,异常信息e={}".format(e))
except:raise
finally:response.close()
四、利用requests.session请求
requests模块中的 Session类能够自动处理发送请求获取响应过程中产生的cookie,进而达到状态保持的目的。
作用及场景:
- 自动处理cookie,即下一次请求会带上前一次的cookie
- 自动处理连续的多次请求过程中产生的cookie
示例代码如下:
import requests# 构造请求头字典
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36','content-type': 'application/json'
}
cookies = {'testCookies_1': 'Hello_Python3','testCookies_2': 'Hello_Java'
}# 构造请求参数字典
data = {'authenticity_token': 'authenticity_token','login': input('输入账号:'),'password': input('输入密码:')
}# 实例化session对象
session = requests.session()# 请求1
post_url = 'https://blog.csdn.net'
response1 = session.post(post_url, data=data, headers=headers, cookies=cookies)print("==========session.post===========")
print(response1.url)
print(response1.request.body)
print(response1.request.headers)
print(response1.request._cookies)
print(response1.cookies)# 请求2
get_url = 'https://blog.csdn.net'
# response2 = session.get(get_url, headers=headers)
response2 = session.get(get_url)print("==========session.get===========")
print(response2.url)
print(response2.request.body)
print(response2.request.headers)
print(response2.request._cookies)

– 求知若饥,虚心若愚。