直接找高校研究生做网站行吗百度云网盘搜索引擎入口
引言
从上一篇文章开始了对Python中容器的介绍,已经对列表的简单使用做了一些介绍,今天这篇文章,打算首先简单介绍一下元组,同时比较一下元组、列表的异同,然后就列表、元组的一些比较实用的用法,做一些补充说明。
本文的主要内容大概如下:
1、Python中元组的简单介绍
2、元组就是不可变列表?
3、关于遍历的其他方式
4、推导式与生成式的比较
Python中的tuple(元组)
在Python中提供了tuple的容器类型,可以实现不可变容器的支持。
tuple的特点主要有:
1、不可变性:元组一旦创建,不能修改、添加、删除其中的元素(需要注意不可变的严格程度)。
2、有序性:如同列表,元组也是有序的,可以通过索引访问。
3、允许重复:元组不同于set(),元素是可以重复的。
4、支持多种类型:如同列表一样,可以放入任何类型的元素。
元组的使用,除了不能增、删、改,基本是跟列表相同的。
但是,需要注意的是,不可变性的程度,是开发者需要注意到的。
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
print(zhangsan)
# 报错
zhangsan[1] = 23
执行结果:

如果改的是嵌套容器的元素呢:
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
print(zhangsan)
# 报错
# zhangsan[1] = 23
# 改变元素的内容
zhangsan[3].append('running')
print(zhangsan)执行结果:

所以,这个元组不可变的说法,需要开发者自己要有所思考、感知的。
tuple就是不可变的列表?
有些入门教材中,总是习惯于把元组称之为“不可变列表”,刚开始简单使用,其实也是无关紧要的。但是,如果要真正理解元组,这样的模糊认知其实是不够的。
首先,从语意上来说,元组,适合于用作一条记录的存储,而列表更适合一组记录的存储。所以,元组中的项数与项的顺序也有具有了语意,自然不能随意更改。
# 存储了一条记录,项依次为姓名、年龄、性别、爱好,顺序自然不能随意变更,每条记录分别以元组存储表达,多条记录则将之放入列表
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
lisi = ('李四', 23, '女', ['reading', 'singing'])
persons = [zhangsan, lisi]
print(persons)执行结果:

其次,元组是否一定能作为字典的key,这也是需要打个问号的。能作为字典key的,一定是可以哈希的。元组一定可以哈希吗?可以使用内置函数hash()来判断:
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
# 本行会抛出TypeError的异常
hash(zhangsan)执行结果:

因为元组中存储了不可哈希的元素。
那么,自然也不能作为字典的key:
zhangsan = ('张三', 18, '男', ['reading', 'basketball'])
d1 = {zhangsan: 10}执行结果:

最后,除了可以作为不可变列表使用之外,tuple相较于list还是有性能上的优势的:
1、在字面量的构建上,元组可以一次生成,并作为常量存储。列表需要逐个入栈,然后构建列表。
2、给定一个元组zs,tuple(ts)直接返回t的引用,不涉及复制。相比之下,列表ls,list(ls)则会创建zs的副本。
zs = ('张三', 18, '男', ['reading', 'basketball'])
zs2 = tuple(zs)
print(id(zs))
print(id(zs2))ls = ['李四', 23, '女', ['reading', 'singing']]
ls2 = list(ls)
print(id(ls))
print(id(ls2))执行结果:

3、在内存分配和引用存储上,元组长度固定,所以分配的内存空间刚好够用;而列表需要考虑追加元素,所以实际的内存空间会多分配一些。元组中元素的引用都存储在元组结构体中的一个数组中,而列表则把元素的引用数组存储在别处。主要是因为列表可以变长,一旦超出当前分配的空间,Python就需要重新分配引用数组来腾出空间。
关于遍历的其他方式
关于对列表和元组的遍历,其实有两个比较好用的“函数”:enumerate()和zip(),其实,不应该说是函数,严谨来说应该是类:
通过使用enumerate,可以生成带指定索引的元组格式的元素:
from faker import Faker
fk = Faker('zh_CN')names = [fk.unique.name() for _ in range(5)]
print(names)
print('='*5 + 'for names' + '='*5)
# 需要按照编号从1开始输出
# 使用for直接遍历:
for i in range(len(names)):print(f"{i + 1}: {names[i]}")
print('='*5 + 'for enumerate' + '='*5)
# 使用enumerate进行遍历:
for idx, name in enumerate(names, start=1):print(f"{idx}: {name}")执行结果:

通过使用zip,可以将两个列表进行拉链,一一组合为元组的形式。
比如,现在有两个列表,分别存放姓名和性别,需要将每个人的姓名、性别同时输出:
names = [fk.unique.name() for _ in range(5)]
genders = [fk.passport_gender() for _ in range(5)]
print('='*5 + 'for names' + '='*5)
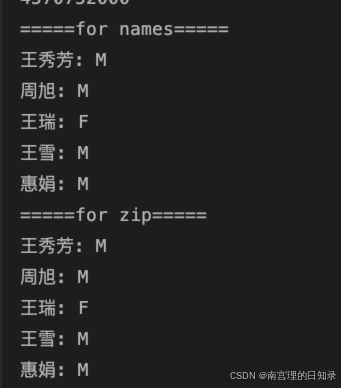
# 使用for直接遍历:
for i in range(len(names)):print(f"{names[i]}: {genders[i]}")
print('='*5 + 'for zip' + '='*5)
# 使用zip进行遍历:
for name, gender in zip(names, genders):print(f"{name}: {gender}")执行结果:
如果两个列表的长度不同呢,我们只取出能匹配上的,匹配不上的就丢弃了,使用zip,自动就可以做到了,但是普通的循环,需要我们自己处理了:
names = [fk.unique.name() for _ in range(5)]
# 性别列表比姓名多了一个
genders = [fk.passport_gender() for _ in range(6)]
print('='*5 + 'for names' + '='*5)
# 使用for直接遍历:
# 长度不同时,需要按照最短的那个来
for i in range(min(len(names), len(genders))):print(f"{names[i]}: {genders[i]}")
print('='*5 + 'for zip' + '='*5)
# 使用zip进行遍历:
for name, gender in zip(names, genders):print(f"{name}: {gender}")此外,zip结合前面提过的*号,还可以实现unzip的效果:
from faker import Faker
fk = Faker('zh_CN')name_gender_map = [(fk.unique.name(), fk.passport_gender()) for _ in range(5)]
print(name_gender_map)
names, genders = zip(*name_gender_map)
print(names)
print(genders)执行结果:

列表推导式与生成器表达式
前面文章中,已经简单介绍了列表推导式的使用,本文将介绍一种新的列表构建的方式——生成器表达式。
使用列表推导式和生成器表达式都可以快速构建一个列表对象(序列),代码编写很快,实际代码执行也会很快,甚至这种一行代码替代for循环的代码习惯之后,更加易于理解!
相较于列表推导式,生成器表达式占用的内存更少,因为生成器表达式使用迭代器协议逐个产生元素,而不是构建整个列表提供给其他构造函数。
生成器表达式的语法跟列表推导式几乎一样,只是把方括号[]换成了圆括号()。
from faker import Faker
fk = Faker('zh_CN')persons = [(fk.name(), fk.random_int(10, 150), fk.random_int(140, 200)) for _ in range(10)]
persons_new = ((fk.name(), fk.random_int(10, 150), fk.random_int(140, 200)) for _ in range(10))
print(type(persons))
print(type(persons_new))
for p in persons_new:print(p)此外,在实际代码编写时,需要注意的是:
Python会忽略[]、{}和()内部的换行。因此,列表、列表推导式、元组、字典等结构完全可以分成几行来写,无须使用续行转义符\。
总结
本文简单介绍了Python中元组的特点,同时对比了元组与列表、推导式与生成式。这些粗略看来,相差不大的概念,仔细思考之后,还是能发现很多值得注意的点,而这些可能就决定了Python代码编写的质量,以及实际运行的效率。