wordpress自动推送给百度泰安seo网络公司
JDBC 的全称是 Java Database Connectivity,是一套面向关系型数据库的规范。虽然数据库各有不同,但这些数据库都提供了基于 JDBC 规范实现的 JDBC 驱动。开发者只需要面向 JDBC 接口编程,就能在很大程度上规避数据库差异带来的问题。Java 应用程序基本上是通过 JDBC 来连接并操作数据库的,哪怕我们使用了对象关系映射框架(例如 Hibernate),其底层也是用 JDBC 来与数据库进行交互的。
6.1 配置数据源
无论是简单的增删改查操作,还是复杂的数据分析任务,都需要先提供一个数据源( DataSource)。顾名思义,数据源就是数据的源头,即可以从中获取数据的地方。数据源的常见实现是连接池,开发者能通过连接池来管理 JDBC 连接。由于 JDBC 操作都是基于连接的,因而在本章的第一部分中,我们先来了解一下连接池。
6.1.1 数据库连接池
在学习 Java 时,大家可能学习过 JDBC 的基础知识。JDBC 通过 java.sql 包中的 Connection 来连接数据库,随后创建 Statement 或 PreparedStatement 执行 SQL 语句。如果是查询操作,在 JDBC 中会用 ResultSet 来代表返回的结果集。一个普通的查询操作可能如代码示例 6-1 所示。
代码示例 6-1 基础的 JDBC 查询操作示例片段
Class.forName("org.h2.Driver");
// 此处使用了try-with-resource的语法,因此不用在finally语法段中关闭资源
try (Connection connection = DriverManager.getConnection("jdbc:h2:mem:test_db");Statement statement = connection.createStatement();ResultSet resultSet = statement.executeQuery("SELECT X FROM SYSTEM_RANGE(1, 10)")) {while (resultSet.next()) {log.info("取值:{}", resultSet.getInt(1));}
} catch (Exception e) {log.error("出错啦", e);
}
这样的代码虽然不复杂,但是在真实的生产环境中,并不推荐大家自己来创建并管理数据库连接,主要原因是创建一个 JDBC 连接的成本非常高。我们建议通过数据库连接池来管理连接,它的主要功能有:
- 根据配置,事先创建一定数量的连接放在连接池中,以便在需要的时候直接返回现成的连接;
- 维护连接池中的连接,根据配置,清理已存在的连接。
我们常用的数据库连接池都实现了 DataSource 接口,通过其中的 getConnection() 方法即可获得一个连接。本节将介绍目前比较流行的两个连接池——HikariCP 和 Druid。此外,业界还有其他一些连接池的出镜率也比较高,比如 DBCP2 和 C3P0 等。
-
HikariCP
Spring Boot 2. x 项目的默认数据库连接池是 HikariCP,Hikari 这个词在日语中的意思是“光”,也许作者起这个名字是为了突出它“速度快”的这个特点。在工程中引入数据库相关的 Spring Boot Starter,默认就会引入 HikariCP 的依赖。例如,在 Spring Initializr 上选中 H2、JDBC API 和 Lombok 三个组件,生成一个工程,其中的依赖就包括如下内容:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId><scope>runtime</scope>
</dependency>
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope>
</dependency>
Spring Boot 的自动配置机制在检测到 CLASSPATH 中存在 H2 数据库的依赖,且没有配置过 DataSource 时,会进行自动配置,提供一个基于内存数据库的数据源。在下一节中我们还会看到不用 Spring Boot 自动配置,而是手动配置一个 DataSource 的例子。我们可以通过一段测试代码来验证一下,如代码示例 6-2 所示。
代码示例 6-2 DatasourceDemoApplicationTests 测试类代码片段
@SpringBootTestclass DatasourceDemoApplicationTests {@Autowiredprivate ApplicationContext applicationContext;
@Testvoid testDataSource() throws SQLException {assertTrue(applicationContext.containsBean("dataSource"));DataSource dataSource = applicationContext.getBean("dataSource", DataSource.class);assertTrue(dataSource instanceof HikariDataSource);
Connection connection = dataSource.getConnection();assertTrue(connection instanceof HikariProxyConnection);connection.close();
assertEquals(10, ((HikariDataSource) dataSource).getMaximumPoolSize());}}
在 testDataSource() 方法中,我们做了如下一些动作:
(1) 先判断上下文中是否存在名为 dataSource 的 Bean;
(2) 如果存在,则取出该 Bean,同时要求这个 Bean 是实现了 DataSource 接口的;
(3) 判断取出的 dataSource 是 HikariDataSource 类型的;
(4) 从 dataSource 中取出一个连接,判断它是否为 HikariProxyConnection 类型;
(5) 判断连接池的最大连接数是否为 10,这是一个默认值。
运行后,这个单元测试能够顺利通过。
在实际使用时,可以直接注入 DataSource Bean,但在更多的情况下,我们并不会直接去操作 DataSource,而是使用更上层的 API。在后文中我们会看到 Spring Framework 的一些 JDBC 封装操作。
HikariCP 有不少配置项,用于调整连接池的大小和各种超时设置,可以直接配置在连接池对象上。Spring Boot 为我们提供了方便的配置方式,在 application.properties 中就可以修改自动配置的连接池,具体的参数如表 6-1 所示。
表 6-1 HikariCP 的常用配置项
| 配置项 | Spring Boot 配置属性 | 配置含义 |
|---|---|---|
jdbcUrl | spring.datasource.url | 用于连接数据库的 JDBC URL |
username | spring.datasource.username | 连接数据库使用的用户名 |
password | spring.datasource.password | 连接数据库使用的密码 |
maximumPoolSize | spring.datasource.hikari.maximum-pool-size | 连接池中的最大连接数 |
minimumIdle | spring.datasource.hikari.minimum-idle | 连接池中保持的最小空闲连接数 |
connectionTimeout | spring.datasource.hikari.connection-timeout | 建立连接时的超时时间,单位为秒 |
idleTimeout | spring.datasource.hikari.idle-timeout | 连接清理前的空闲时间,单位为秒 |
maxLifetime | spring.datasource.hikari.max-lifetime | 连接池中连接的最大存活时间,单位为秒 |
茶歇时间:HikariCP 为什么说自己比别人快
HikariCP 官方一直将“快”作为自己的亮点。从官方性能测试的结果来看,HikariCP 的性能数倍于 DBCP2、C3P0 和 Tomcat 连接池。
官方有一篇“Down the Rabbit Hole”的文章,简单说明了 HikariCP 性能出众的原因:
- 通过字节码进行加速,
JavassistProxyFactory中使用Javassist直接生成了大量字节码塞到了ProxyFactory中,同时还对字节码进行了精确地优化;- 使用
FastList代替了 JDK 内置的ArrayList;- 从 .NET 中借鉴了无锁集合
ConcurrentBag。由此可见,HikariCP 的作者还是在连接池的性能调优方面下了很多功夫的,甚至可以说用上了不少“奇技淫巧”。
-
Druid
阿里巴巴开源的 Druid 数据库连接池在阿里巴巴集团内部得到了广泛的应用,在国内也有大量的使用者。暂且不论 Druid 是否是 Java 语言中最好的数据库连接池,但其官方宣称它是面向监控而生的数据库连接池倒是一个不争的事实。在监控能力之外,Druid 还提供了很丰富的功能,例如:
- 针对主流数据库的适配,包含驱动、连接检查、异常等;
- 内置 SQL 注入防火墙功能;
- 内置数据库密码非对称加密功能;
- 内置针对数据库异常的
ExceptionSorter,可对不同的异常进行区别对待; - 内置丰富的日志信息;
- 提供了强大的扩展能力,可在 JDBC 连接操作的各个阶段注入自己的逻辑。
如果用一个字来形容 HikariCP 的特点,那就是“快”,它需要配合其他的一些组件才能实现某些功能。Druid 的特点应该就是“全”,仅其内置的功能就已经能满足绝大部分生产环境中的苛刻要求了,更不用说我们还能对它进行扩展。
Druid 提供了一个 Spring Boot Starter 来适配 Spring Boot 的自动配置功能。也就是说,除了自己动手配置一个 DruidDataSource Bean 以外,我们也可以通过自动配置的方式来提供数据源的 Bean。
仍旧以上面的 DataSourceDemo 为例,在 pom.xml 中添加如下依赖(版本可通过官方主页查询)即可引入 Druid 的支持。如果可以的话,建议从 spring-boot-starter-jdbc 中排除掉 HikariCP 的依赖,因为项目中不再需要它了:
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version>
</dependency>
对于测试代码,我们也稍作调整,将判断的条件替换为 Druid 的类,具体如代码示例 6-3 所示。
代码示例 6-3 DatasourceDemoApplicationTests 测试类代码片段
@SpringBootTest
class DatasourceDemoApplicationTests {@Autowiredprivate ApplicationContext applicationContext;
@Testvoid testDataSource() throws SQLException {assertTrue(applicationContext.containsBean("dataSource"));DataSource dataSource = applicationContext.getBean("dataSource", DataSource.class);assertTrue(dataSource instanceof DruidDataSource);
Connection connection = dataSource.getConnection();assertTrue(connection instanceof DruidPooledConnection);connection.close();
assertEquals(DruidDataSource.DEFAULT_MAX_ACTIVE_SIZE,((DruidDataSource) dataSource).getMaxActive());}
}
在判断出使用了 H2 内嵌数据库后,通过 druid-spring-boot-starter 也能自动创建数据源的 Bean。我们对其类型和一些默认配置做了判断。与 HikariCP 类似,Druid 也提供了很多配置项,其中常用的内容如表 6-2 所示,关于 Druid 的高阶功能,我们会在后续的章节中再展开讨论。
表 6-2 Druid 的常用配置项
| 配置项 | Spring Boot 配置属性 | 配置含义 |
|---|---|---|
url | spring.datasource.url | 用于连接数据库的 JDBC URL |
username | spring.datasource.username | 连接数据库使用的用户名 |
password | spring.datasource.password | 连接数据库使用的密码 |
initialSize | spring.datasource.druid.initial-size | 初始化连接池时建立的连接数 |
maxActive | spring.datasource.druid.max-active | 连接池中的最大连接数 |
minIdle | spring.datasource.druid.min-idle | 连接池中保持的最小空闲连接数 |
maxWait | spring.datasource.druid.max-wait | 获取连接的最大等待时间,单位为毫秒 |
testOnBorrow | spring.datasource.druid.test-on-borrow | 获取连接时检查连接,会影响性能 |
testOnReturn | spring.datasource.druid.test-on-return | 归还连接时检查连接,会影响性能 |
testWhileIdle | spring.datasource.druid.test-while-idle | 检查空闲的连接,具体的检查发生在获取时,对性能几乎无影响 |
filters | spring.datasource.druid.filters | 要配置的插件过滤器列表 |
6.1.2 数据源配置详解
Spring Boot 为了减少数据源的配置工作,做了大量的基础工作,比如:
- 提供了方便的
spring.datasource通用配置参数; - 提供了针对多种连接池的单数据源自动配置;
- 提供了针对内嵌数据库的特殊自动配置。
接下来就让我们分别来了解这些特性以及它们的实现原理。在本节的最后,会以 MySQL 为例,配置一个数据源。
-
数据源配置参数详解
Spring Boot 为数据源配置提供了一个
DataSourceProperties,用于绑定spring.datasource的配置内容。它的类定义如下:
@ConfigurationProperties(prefix = "spring.datasource")
public class DataSourceProperties implements BeanClassLoaderAware, InitializingBean {}
之前在介绍 HikariCP 和 Druid 时,我们已经看到过一些配置项了,现在再跟着 DataSourceProperties 重新认识一下 Spring Boot 提供的配置项,具体如表 6-3 所示。
表 6-3 Spring Boot 提供的部分常用 spring.datasource 配置项
| 配置项 | 默认值 | 说明 |
|---|---|---|
spring.datasource.url | 数据库的 JDBC URL | |
spring.datasource.username | 连接数据库的用户名 | |
spring.datasource.password | 连接数据库的密码 | |
spring.datasource.name | 使用内嵌数据库时为 testdb | 数据源的名称 |
spring.datasource.jndi-name | 获取数据源的 JNDI 名称 | |
spring.datasource.type | 根据 CLASSPATH 自动探测 | 连接池实现的全限定类名 |
spring.datasource.driver-class-name | 根据 URL 自动探测JDBC | 驱动类的全限定类名 |
spring.datasource.generate-unique-name | true | 是否随机生成数据源名称 |
我们一般会配置表 6-3 中的前三个配置项,再结合一些连接池的配置(Spring Boot 内置了对 HikariCP、DBCP2 和 Tomcat 连接池的支持),还有其他对应的配置,分别放在了如下前缀的配置项中:
spring.datasource.hikari.*(在之前的章节中已经见过一些了);spring.datasource.dbcp2.*;spring.datasource.tomcat.*。
还有一些与初始化相关的配置,稍后再做说明。
-
数据源自动配置详解
Spring Boot 的数据源自动配置,是一个很好的自动配置实现示范。我们通过
DataSourceAutoConfiguration类可以学习到很多自动配置的技巧,例如条件控制、内嵌配置类、导入其他配置等。DataSourceAutoConfiguration会先判断是否存在DataSource和EmbeddedDatabaseType,满足条件则导入DataSourcePoolMetadataProvidersConfiguration和DataSourceInitializationConfiguration两个配置类,前者配置连接池元数据提供者,后者进行数据源初始化配置。整个
DataSourceAutoConfiguration分为两个内嵌配置类——内嵌数据库配置类EmbeddedDatabaseConfiguration和连接池数据源配置类PooledDataSourceConfiguration。下面来看一下连接池数据源的配置。PooledDataSourceConfiguration会直接导入DataSourceConfiguration中关于 HikariCP、DBCP2、Tomcat 和通用数据源的配置,随后这些配置类再根据自己的条件决定是否生效;此外DataSourceJmxConfiguration配置类也会根据条件将不同数据库连接池的信息发布到 JMX 端点上。我们以 HikariCP 的自动配置
DataSourceConfiguration.Hikari为例,来看一下 Spring Boot 是如何为我们自动配置DataSource的。其他类型数据库连接池的配置与它大同小异,下面是具体的代码:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(HikariDataSource.class)
@ConditionalOnMissingBean(DataSource.class)
@ConditionalOnProperty(name = "spring.datasource.type", havingValue = "com.zaxxer.hikari.
HikariDataSource", matchIfMissing = true)
static class Hikari {@Bean@ConfigurationProperties(prefix = "spring.datasource.hikari")HikariDataSource dataSource(DataSourceProperties properties) {HikariDataSource dataSource = createDataSource(properties, HikariDataSource.class);if (StringUtils.hasText(properties.getName())) {dataSource.setPoolName(properties.getName());}return dataSource;}
}
首先,判断 CLASSPATH 中存在 HikariDataSource 类,并且尚未配置 DataSource。如果配置了 spring.datasource.type 并且是 HikariCP 的类,或者这个属性为空,则配置生效。
接着,创建一个 HikariDataSource 数据源对象,如果指定了数据源名称,则进行赋值。
最后,通过 @ConfigurationProperties 将 spring.datasource.hikari.* 的属性都绑定到返回的 HikariDataSource 对象上,这个对象就是 Spring 上下文中的 DataSource Bean 了。
-
内嵌数据库的特殊逻辑
在之前的示例中,我们使用了 H2 内嵌数据库,它可以轻松地将所有数据保存在本机内存中,程序关闭后,内存中的数据就消失了。因此,H2 用来作为测试数据库非常合适。我们在后续的示例中也会大量地使用 H2。
EmbeddedDatabaseType定义了 Spring Boot 内置支持的三种数据库,即 HSQL、H2 和 Derby,EmbeddedDatabaseConnection则分别定义了三者的 JDBC 驱动类和用来创建内存数据库的 JDBC URL。系统启动时会根据 CLASSPATH 来判断是否存在对应的驱动类。随后,EmbeddedDataSourceConfiguration.dataSource()方法会根据前面的信息来创建DataSource对象。创建完内嵌数据库的
DataSource后,Spring Boot 还会为我们进行数据库的初始化工作,我们可以在这个过程中建表,并导入初始的数据。初始化动作是由DataSourceInitializer类来实现的,它会根据spring.sql.init.schema-locations和spring.sql.init.data-locations这两个属性来初始化数据库中的表和数据,默认通过读取 CLASSPATH 中的 schema.sql 和 data.sql 文件来进行初始化。表 6-4 罗列了一些与数据源初始化相关的配置项。表 6-4 与数据源初始化相关的配置项
当前配置项 旧配置项 默认值 说明 spring.sql.init.modespring.datasource.initialization-modeembedded何时使用 DDL 和 DML脚本初始化数据源,可选值为 embedded、always和neverspring.sql.init.platformspring.datasource.platformall脚本对应的平台,用来拼接最终的 SQL 脚本文件名,例如,schema-.sql spring.sql.init.separatorspring.datasource.separator;脚本中的语句分隔符 spring.sql.init.encodingspring.datasource.sql-script-encodingSQL 脚本的编码 spring.sql.init.continue-on-errorspring.datasource.continue-on-errorfalse初始化过程中报错是否停止初始化 spring.sql.init.schema-locationsspring.datasource.schema默认会用schema.sql 初始化用的 DDL 脚本 spring.sql.init.username`spring.datasource.schema-username `DDL 语句运行所用的用户名,如与连 接用的不一样,可在此指定 spring.sql.init.passwordspring.datasource.schema-passwordDDL 语句运行所用的密码,如与连接 用的不一样,可在此指定 spring.sql.init.data-locationsspring.datasource.data默认会用 data.sql 初始化用的 DML 脚本 spring.sql.init.usernamespring.datasource.data-usernameDML 语句运行所用的用户名,如与连接用的不一样,可在此指定 spring.sql.init.passwordspring.datasource.data-passwordDML 语句运行所用的密码,如与连接用的不一样,可在此指定
DDL 是数据定义语言,一般对应与表结构相关的内容;DML 是数据操作语言,一般对应与表数据库增删改查相关的操作内容。
第一个配置项就告诉我们,Spring Boot 只是默认为内嵌数据库做初始化,其实,我们也可以对任意数据库进行初始化。不过在实际生产中,这种初始化工作很少由系统来实现,更多的是通过一定的流程,经 DBA 审批后自动或人工进行变更的。
-
配置一个连接 MySQL 的数据源
在工作中,我们的系统一般都会连接类似 MySQL、Oracle 这样的数据库,很少会用 H2、Derby,所以在本节的最后,我们以 MySQL 为例,看看 Spring Boot 程序该如何来连接生产数据库。
要连接数据库,首先需要在 pom.xml 的
<dependencies/>中加入 MySQL 的 JDBC 驱动,可以像下面这样添加依赖:
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId>
</dependency>
spring-boot-dependencies 会自动为我们管理 mysql-connector-java 的版本。例如,Spring Boot 2.6.3 中用的就是 mysql-connector-java 8.0.28。随后,我们在 application.properties 中添加与数据源相关的配置,如代码示例 6-4 所示。
代码示例 6-4 application.properties 中 MySQL 数据源的配置
spring.datasource.url=jdbc:mysql://localhost/binary-tea?useUnicode=true&characterEncoding=utf8
spring.datasource.username=binary-tea
spring.datasource.password=binary-tea
spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.minimum-idle=10
这个配置会连接本机安装的 MySQL,端口是默认的 3306,连接的数据库是 binary-tea,用户名和密码也是 binary-tea。
请注意 在生产环境请不要使用这样的“弱密码”,而且密码不要用明文配置在文件中。
随后,对测试代码稍作修改,让它检查一下我们是否成功连接了 MySQL。具体见代码示例 6-5。
代码示例 6-5 DatasourceDemoApplicationTests 测试类代码片段
@SpringBootTestclass DatasourceDemoApplicationTests {@Autowiredprivate ApplicationContext applicationContext;@Value("$")private String jdbcUrl;@Testvoid testDataSource() throws SQLException {assertTrue(applicationContext.containsBean("dataSource"));DataSource dataSource = applicationContext.getBean("dataSource", DataSource.class);assertTrue(dataSource instanceof HikariDataSource);HikariDataSource hikari = (HikariDataSource) dataSource;assertEquals(20, hikari.getMaximumPoolSize());assertEquals(10, hikari.getMinimumIdle());assertEquals("com.mysql.cj.jdbc.Driver", hikari.getDriverClassName());assertEquals(jdbcUrl, hikari.getJdbcUrl());Connection connection = hikari.getConnection();assertNotNull(connection);connection.close();}}
通过这个测试,我们可以看到 Spring Boot 根据我们的 JDBC URL 和 CLASSPATH 自动推断出了所需的 JDBC 驱动类,并将其设置为了 com.mysql.cj.jdbc.Driver。我们也可以自己来创建 DataSource Bean,HikariCP 本身也能自己来选择驱动,但如果此时 driverClassName 为空,则可以去掉那个判断。代码示例 6-6 是自己创建 Bean 的代码。
代码示例 6-6 自己配置 HikariDataSource Bean 的代码
@Bean
@ConfigurationProperties("spring.datasource.hikari")
public DataSource dataSource(DataSourceProperties properties) {HikariDataSource dataSource = new HikariDataSource();dataSource.setJdbcUrl(properties.getUrl());dataSource.setUsername(properties.getUsername());dataSource.setPassword(properties.getPassword());return dataSource;
}
如果使用 XML 的方式,可能会像下面这样:
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beanshttps://www.springframework.org/schema/beans/spring-beans.xsd"><bean id="dataSource" class="com.zaxxer.hikari.HikariDataSource"><property name="jdbcUrl" ref="$"/><property name="username" ref="$"/><property name="password" ref="$"/><property name="maxPoolSize" ref="$"/><property name="minIdle" ref="$"/><!-- 其他配置省略 --></bean></beans>
茶歇时间:使用 Docker 简化本地开发环境的准备工作
随着容器技术的普及,在生产和测试环境使用 Kubernetes 早已不是什么新鲜事了。容器中不仅包含了我们的工程,还包含了工程运行所需的整个环境。而且,容器技术相比传统的虚拟机更节省资源,运行效率更高,是交付与运行的理想之选。
Docker 是目前比较常用的容器,它提供了针对不同操作系统的支持,可以非常方便地在本地搭建起一套环境。在开发时,我们经常需要搭建各种基础设施,比如,MySQL 数据库、Redis、Zookeeper 等。有了 Docker,搭建这些基础设施就变成了简单的几条命令。
以上面提到的 MySQL 为例,要在本机从头开始搭建一套 MySQL,只需简单的两句命令。
首先,通过
docker pull命令从仓库中获取 MySQL 的镜像:▸ docker pull mysql接着,根据官方镜像的说明运行 MySQL,并进行相应的初始化:
▸ docker run --name binary-tea-mysql -d -p 3306:3306 -v ~/docker-data/mysql/binary-tea:/var/lib/mysql -e MYSQL_DATABASE=binary-tea -e MYSQL_USER=binary-tea -e MYSQL_PASSWORD=binary-tea -e MYSQL_ROOT_PASSWORD=root_password mysql这里,我们简单说明一下
docker run的命令,命令最后的mysql是镜像名,前面几个参数的作用见表 6-5。表 6-5
docker run命令中几个参数的作用参数作用
--name指定了运行后容器的名称,如果不指定的话,Docker 会自动生成一个-d在后台运行容器-p将容器中的端口映射到宿主机上,例如,这里就可以通过本机的 3306 端口来访问容器的 3306 端口-v将宿主机的某个目录挂载到容器中,例如,这里就把本机的 ~/docker-data/mysql/binary-tea 目录挂载到了容器里-e用来指定容器的环境变量
除了 docker run,常用的命令还有 docker stop、 docker start 和 docker ps。 docker stop 用来停止运行中的容器, docker start 则是将停止运行的容器再启动起来,例如,可以用 docker stop binary-tea-mysql 来停止刚才由 docker run 创建的容器。 docker ps 命令可以查看当前正在运行的容器。
Docker 涉及的内容非常多,如果大家感兴趣的话,可以前往其官方网站了解更多信息。
6.2 使用 JDBC 操作数据库
在建立了数据源之后,想要操作数据,最简单的办法就是使用 JDBC 提供的接口,正如 6.1 节开头那样。但使用原生 API 需要做很多模板化的工作,而且在一些细节上如果处理不当也会造成一些麻烦。Spring Framework 为我们提供了一整套关于 JDBC 的封装,Spring Boot 更是贴心地提供了相关的自动配置。在本节中,我们就来了解一些与数据操作相关的内容。
说起 JDBC 操作,最基本的就是增删改查操作,但无论是什么操作,都遵循一个基本的流程:
(1) 获取 Connection 连接;
(2) 通过 Connection 创建 Statement 或者 PreparedStatement;
(3) 执行具体的 SQL 操作;
(4) 关闭 Statement 或者 PreparedStatement;
(5) 关闭 Connection。
可以看到,其中只有第 (3) 步是与我们的逻辑有关的,其他的步骤都是基本一样的,GoF 23 中的模板模式就非常适用这种情况。实际上,Spring Framework 也是这么做的,它为我们提供了 JdbcTemplate 和 NamedParameterJdbcTemplate 两个模板类,我们可以通过它们进行各种 SQL 操作。
接下来,让我们以 JdbcTemplate 为例来了解下如何通过模板类进行增删改查操作。
6.2.1 查询类操作
JdbcTemplate 中提供了很多参数与返回类型的 query 前缀方法,其中,比较常用的是 query() 和 queryForObject()。它们也有很多参数和返回类型,本节中只会介绍其中的几个,其他的可以通过 JavaDoc 或者 JdbcTemplate 的代码来了解。现在,继续以我们的奶茶店系统为例,演示一下 JDBC 相关的操作。
需求描述 假设,顾客进店点饮品,我们需要准备一份菜单,其中包含饮品的名称和价格。此处,需要提供两个查询方法,一个用来查询菜单中的条目总数,当条目总数多的时候,可以让顾客感觉我们店内饮品选择多样化,条目总数少的时候,可以说我们只做精品;另一个用来查询菜单的明细,在启动时打印一下店里的菜单。
以第 5 章的 binarytea-endpoint 例子作为基础,我们新建一个 binarytea-jdbc 项目,菜单信息会被保存在名为 t_menu 的表中,并提供相应的接口。在项目的 pom.xml 文件依赖中增加如下内容,分别是 Spring Boot 的 JDBC 依赖、H2 数据库依赖以及 Lombok。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId><scope>runtime</scope>
</dependency>
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional>
</dependency>
先为菜单条目创建一个对应的模型(Model)类,其中的内容与数据表结构一一对应。在后续操作时,它可以将查询所得结果转换为这个类型,这样更便于使用,也易于理解,具体见代码示例 6-7。其中,我们通过 Lombok 注解减少了大量方法代码的编写工作。
请注意 请务必事先在 IDEA 中安装 Lombok 插件。
代码示例 6-7 MenuItem 类的声明
package learning.spring.binarytea.model;// 省略 import@Builder
@Getter
@Setter
@ToString
public class MenuItem {private Long id;private String name;private String size;private BigDecimal price; // 暂时用BigDecimal表示金额private Date createTime;private Date updateTime;
}
主要的查询逻辑都会放在 MenuRepository 中,这个类上添加了 @Repository 注解,用来告诉 Spring 容器这个类要创建 Bean 实例,并且它代表了一个数据仓库(Repository)。容器会自动注入构造方法所需的 JdbcTemplate 实例,我们也可以提供空构造方法,在 jdbcTemplate 的声明上添加 @Autowired,效果是一样的。具体的类声明见代码示例 6-8。
代码示例 6-8 MenuRepository 类的声明
package learning.spring.binarytea.repository;// 省略import@Repository
public class MenuRepository {private JdbcTemplate jdbcTemplate;public MenuRepository(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;}// 几个查询方法待说明
}
要查询的 SQL 只返回一个值,那么可以使用 queryForObject(String sql, Class<T> requiredType) 方法,例如,代码示例 6-9 会返回表中记录的总数。
代码示例 6-9 统计总数的 countMenuItems() 方法
public long countMenuItems() {return jdbcTemplate.queryForObject("select count(*) from t_menu", Long.class);
}
返回的结果有多个字段,可以用 queryForMap() 将它们都放到一个 Map<String, Object> 中,也可以通过 RowMapper 将字段映射到某个对象上。例如,代码示例 6-10 用 queryForObject(String sql, RowMapper<T> rowMapper, @Nullable Object... args) 方法查询单条记录,并将字段内容填充进 MenuItem 里。
代码示例 6-10 查询单条记录的 queryForItem() 方法
public MenuItem queryForItem(Long id) {return jdbcTemplate.queryForObject("select * from t_menu where id = ?", rowMapper(), id);
}private RowMapper<MenuItem> rowMapper() {return (resultSet, rowNum) -> {return MenuItem.builder().id(resultSet.getLong("id")).name(resultSet.getString("name")).size(resultSet.getString("size")).price(BigDecimal.valueOf(resultSet.getLong("price") / 100.0d)).createTime(new Date(resultSet.getDate("create_time").getTime())).updateTime(new Date(resultSet.getDate("update_time").getTime())).build();};
}
其中的 RowMapper<MenuItem> 可以直接通过 Lambda 的方式写在方法调用里,但为了能够复用这个 RowMapper,我们将它单独“抽”了出来。
一个查询操作如果要求返回多条记录,可以使用 query(String sql, RowMapper<T> rowMapper)。代码示例 6-11 的 queryAllItems() 可以返回全部的菜单内容,其中还用到了上面定义的 rowMapper()。
代码示例 6-11 返回全部菜单的 queryAllItems()
public List<MenuItem> queryAllItems() {return jdbcTemplate.query("select * from t_menu", rowMapper());
}
为了让查询能够正常执行,我们需要为 H2 数据库建表并添加一些初始数据,它们被分别放在工程 src/resources 目录的 schema.sql 和 data.sql 中,具体内容见代码示例 6-12 与代码示例 6-13。
代码示例 6-12 包含表结构定义的 schema.sql
drop table t_menu if exists;create table t_menu (id bigint auto_increment,name varchar(128),size varchar(16),price bigint,create_time timestamp,update_time timestamp,primary key (id)
);
代码示例 6-13 包含初始数据的 data.sql
insert into t_menu (name, size, price, create_time, update_time) values ('Java咖啡', '中杯', 1000, now(), now());
insert into t_menu (name, size, price, create_time, update_time) values ('Java咖啡', '大杯', 1500, now(), now());
为了保证 MenuRepository 类的功能正确,我们需要添加一些单元测试,根据上面构造的数据对方法的调用结果进行判断,就像代码示例 6-14 中演示的那样。
代码示例 6-14 MenuRepositoryTest 中的测试代码
@SpringBootTest
class MenuRepositoryTest {@Autowiredprivate MenuRepository menuRepository;@Testvoid testCountMenuItems() {assertEquals(2, menuRepository.countMenuItems());}@Testvoid testQueryAllItems() {List<MenuItem> items = menuRepository.queryAllItems();assertNotNull(items);assertFalse(items.isEmpty());assertEquals(2, items.size());}@Testvoid testQueryForItem() {MenuItem item = menuRepository.queryForItem(1L);assertItem(item, 1L, "Java咖啡", "中杯", BigDecimal.valueOf(10.00));}private void assertItem(MenuItem item, Long id, String name, String size, BigDecimal price) {assertNotNull(item);assertEquals(id, item.getId());assertEquals(name, item.getName());assertEquals(size, item.getSize());assertEquals(price, item.getPrice());}
}
单元测试中,我们通过各种断言自动验证了方法的返回内容,在自动化测试过程中无须人的介入,并且可以反复执行。断言是单元测试中 必不可少 的部分,千万不要用 “日志输出+人工观察” 的方式。
最后,编写启动后输出菜单的逻辑。我们可以通过 ApplicationRunner 来执行打印动作,如代码示例 6-15 所示。在 MenuPrinterRunner 上添加 Lombok 的 @Slf4j 注解,会自动生成一个 log 对象,即可用它来打印日志。
代码示例 6-15 MenuPrinterRunner 类代码片段
package learning.spring.binarytea.runner;// 省略import@Component
@Slf4j
public class MenuPrinterRunner implements ApplicationRunner {private final MenuRepository menuRepository;public MenuPrinterRunner(MenuRepository menuRepository) {this.menuRepository = menuRepository;}@Overridepublic void run(ApplicationArguments args) throws Exception {log.info("共有{}个饮品可选。", menuRepository.countMenuItems());menuRepository.queryAllItems().forEach(i -> log.info("饮品:{}", i));}
}
整个程序在运行后,能在日志中找到类似下面这样的内容:
2022-02-13 00:01:48.838 INFO 70291 --- [main] l.s.binarytea.runner.MenuPrinterRunner : 共有2个饮品可选。
2022-02-13 00:01:48.841 INFO 70291 --- [main] l.s.binarytea.runner.MenuPrinterRunner : 饮品:
MenuItem(id=1, name=Java咖啡, size=中杯, price=10.0, createTime=Sun Feb 13 00:00:00 CST 2022,
updateTime=Sun Feb 13 00:00:00 CST 2022)
2022-02-13 00:01:48.849 INFO 70291 --- [main] l.s.binarytea.runner.MenuPrinterRunner : 饮品:
MenuItem(id=2, name=Java咖啡, size=大杯, price=15.0, createTime=Sun Feb 13 00:00:00 CST 2022,
updateTime=Sun Feb 13 00:00:00 CST 2022)
6.2.2 变更类操作
JdbcTemplate 的 update() 方法可以用来执行修改类的 SQL 语句,比如 INSERT、 UPDATE 和 DELETE 语句。以插入数据为例,大家可以简单地使用 update(String sql, @Nullable Object... args) 方法,这个方法的返回值是更新到的记录条数。插入一条菜单内容的代码大概是代码示例 6-16 这样的。
代码示例 6-16 插入一条记录
public static final String INSERT_SQL ="insert into t_menu (name, size, price, create_time, update_time) values (?, ?, ?, now(), now())";public int insertItem(MenuItem item) {return jdbcTemplate.update(INSERT_SQL, item.getName(),item.getSize(), item.getPrice().multiply(BigDecimal.valueOf(100)).longValue());
}
其中,SQL 语句后的参数顺序对应了 SQL 中 ? 占位符的顺序。在很多时候,数据的 ID 是自增长的主键,如果我们希望在插入记录后能取得生成的 ID,这时可以使用 KeyHolder 类来持有生成的键。代码类似代码示例 6-17。
代码示例 6-17 插入一条记录并填充主键
public int insertItemAndFillId(MenuItem item) {KeyHolder keyHolder = new GeneratedKeyHolder();int affected = jdbcTemplate.update(con -> {PreparedStatement preparedStatement =con.prepareStatement(INSERT_SQL, PreparedStatement.RETURN_GENERATED_KEYS);// 也可以用PreparedStatement preparedStatement =// con.prepareStatement(INSERT_SQL, new String[] { "id" });preparedStatement.setString(1, item.getName());preparedStatement.setString(2, item.getSize());preparedStatement.setLong(3, item.getPrice().multiply(BigDecimal.valueOf(100)).longValue());return preparedStatement;}, keyHolder);if (affected == 1) {item.setId(keyHolder.getKey().longValue());}return affected;
}
更新与删除操作使用的也是类似的手法,同样也是 update() 方法,例如,代码示例 6-18 将根据主键删除一条菜单项记录。
代码示例 6-18 删除一条菜单项记录
public int deleteItem(Long id) {return jdbcTemplate.update("delete from t_menu where id = ?", id);
}
上述增加和删除方法的测试会影响表中的记录数量,随机运行会导致对结果判断的不准确,因此需要指定测试的运行顺序。JUnit 5 提供了 @TestMethodOrder 注解来指定操作的执行顺序,可以选择字母序、注解顺序和随机三种。以注解顺序为例,代码大概会是代码示例 6-19 这样的。
代码示例 6-19 指定了注解顺序的测试代码
@SpringBootTest
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
class MenuRepositoryTest {@Autowiredprivate MenuRepository menuRepository;// 省略了其他测试方法@Test@Order(1)void testInsertItem() {MenuItem item = MenuItem.builder().name("Go橙汁").size("中杯").price(BigDecimal.valueOf(12.00)).build();assertEquals(1, menuRepository.insertItem(item));assertNull(item.getId());MenuItem queryItem = menuRepository.queryForItem(3L);assertItem(queryItem, 3L, "Go橙汁", "中杯", BigDecimal.valueOf(12.00));assertEquals(1, menuRepository.insertItemAndFillId(item));queryItem = menuRepository.queryForItem(item.getId());assertItem(queryItem, 4L, "Go橙汁", "中杯", BigDecimal.valueOf(12.00));}@Test@Order(2)void testDelete() {assertEquals(1, menuRepository.deleteItem(3L));assertEquals(1, menuRepository.deleteItem(2L));}private void assertItem(MenuItem item, Long id, String name, String size, BigDecimal price) {assertNotNull(item);assertEquals(id, item.getId());assertEquals(name, item.getName());assertEquals(size, item.getSize());assertEquals(price, item.getPrice());}
}
在上面的例子里,我们的 SQL 中用到了很多 ?, ? 的数量一多,就容易在传参时搞错位置。Spring Framework 为我们提供了一个 NamedParameterJdbcTemplate 类,其中封装了很多 JdbcTemplate 的操作。 NamedParameterJdbcTemplate 可以为 SQL 中的参数设定名称,然后根据名称进行赋值。Spring Boot 同样为它进行了自动配置,在只有一个或指定了主 JdbcTemplate 的 Bean 时,Spring Boot 就会自动配置一个 NamedParameterJdbcTemplate Bean。我们可以把上面的 insertItem() 修改成代码示例 6-20 这样。
代码示例 6-20 使用了 NamedParameterJdbcTemplate 的 insertItem() 方法
public int insertItem(MenuItem item) {String sql = "insert into t_menu (name, size, price, create_time, update_time) values " +"(:name, :size, :price, now(), now())";MapSqlParameterSource sqlParameterSource = new MapSqlParameterSource();sqlParameterSource.addValue("name", item.getName());sqlParameterSource.addValue("size", item.getSize());sqlParameterSource.addValue("price", item.getPrice().multiply(BigDecimal.valueOf(100)).longValue());return namedParameterJdbcTemplate.update(sql, sqlParameterSource);
}
在代码示例 6-20 中可以看到,SQL 中的占位符被替换为了具体的参数名称。在执行语句时,通过 SqlParameterSource 来传入参数,这个接口有多种实现,比如上面例子中的 MapSqlParameterSource 会以 Map 的形式来提供参数, BeanPropertySqlParameterSource 会从 Bean 属性中提取参数。
6.2.3 批处理操作
在数据处理时,我们经常会遇到需要插入或更新一大批数据的情况。大多数 JDBC 驱动针对批量调用相同 PreparedStatement 的情况都做了特殊优化,所以在 Spring Framework 中也为批处理操作提供了多个 batchUpdate() 方法,方法的返回是一个 int[],代表每次执行语句的更新条数。
需求描述 二进制奶茶店目前的菜单内容还比较少,一条一条地添加勉强也可以接受,但内容多了之后,完整的操作过程就太慢了,效率也不高。为何不一次性添加一批菜单条目呢?搞个批量操作多好呀!
我们可以设计一个批量插入数据的接口,像代码示例 6-21 那样,在 batchUpdate() 方法中,传入 BatchPreparedStatementSetter 来设置 PreparedStatement 占位符的内容。
代码示例 6-21 批量插入方法
public int insertItems(List<MenuItem> items) {int[] count = jdbcTemplate.batchUpdate(INSERT_SQL, new BatchPreparedStatementSetter() {@Overridepublic void setValues(PreparedStatement ps, int i) throws SQLException {MenuItem item = items.get(i);ps.setString(1, item.getName());ps.setString(2, item.getSize());ps.setLong(3, item.getPrice().multiply(BigDecimal.valueOf(100)).longValue());}@Overridepublic int getBatchSize() {return items.size();}});return Arrays.stream(count).sum();
}
上述方法的测试代码如代码示例 6-22 所示。我们通过 Java 8 的流式代码创建了 3 个菜单条目,将它们放在一个 List<MenuItem> 中,随后调用 insertItems() 方法,判断是否成功插入 3 条记录,并逐条验证了每条插入记录的内容。这里设置了 @Order(3) 来控制测试用例的执行顺序,因为上面插入过几条记录,所以本次新增的记录 ID 从 5 开始。如果是单独运行 testInsertItems(),那么 ID 要从 3 开始。
代码示例 6-22 MenuRepositoryTest 中关于 insertItems() 的测试代码
@Test
@Order(3)
void testInsertItems() {List<MenuItem> items = Stream.of("Go橙汁", "Python气泡水", "JavaScript苏打水").map(n -> MenuItem.builder().name(n).size("中杯").price(BigDecimal.valueOf(12.00)).build()).collect(Collectors.toList());assertEquals(3, menuRepository.insertItems(items));assertItem(menuRepository.queryForItem(3L), 3L, "Go橙汁", "中杯", BigDecimal.valueOf(12.00));assertItem(menuRepository.queryForItem(4L), 4L, "Python气泡水", "中杯", BigDecimal.valueOf(12.00));assertItem(menuRepository.queryForItem(5L), 5L, "JavaScript苏打水", "中杯", BigDecimal.valueOf(12.00));
}
batchUpdate() 方法还有其他几种形式,用起来也相对容易些,例如 batchUpdate(String sql, List<Object[]> batchArgs), Object[] 就是按给定的顺序替换内容。 insertItems() 可以改写成下面这样:
public int insertItems(List<MenuItem> items) {List<Object[]> batchArgs = items.stream().map(item -> new Object[]{item.getName(), item.getSize(), item.getPrice().multiply(BigDecimal.valueOf(100)).longValue()}).collect(Collectors.toList());int[] count = jdbcTemplate.batchUpdate(INSERT_SQL, batchArgs);return Arrays.stream(count).sum();
}
NamedParameterJdbcTemplate 中也提供了 batchUpdate() 方法,我们能使用 SqlParameterSource 来代表一条对应的内容。辅助类 SqlParameterSourceUtils 中有一些方法,可以帮我们把一批对象转换为 SqlParameterSource[]。同样的,我们可以用 NamedParameterJdbcTemplate 来改写 insertItems() 方法:
public int insertItems(List<MenuItem> items) {String sql = "insert into t_menu (name, size, price, create_time, update_time) values " +"(:name, :size, :price * 100, now(), now())";int[] count = namedParameterJdbcTemplate.batchUpdate(sql, SqlParameterSourceUtils.createBatch(items));return Arrays.stream(count).sum();
}
这里我们实际使用的是 BeanPropertySqlParameterSource,从对象中提取属性对应到 SQL 中的命名参数上, price 的类型是 BigDecimal,单位是元,而数据库中我们的单位是分,所以在 SQL 语句中做了些小调整。
6.2.4 自动配置说明
上文提到 Spring Boot 提供了 JdbcTemplate 和 NamedParameterJdbcTemplate 的自动配置,接下来让我们详细看一下它的具体配置:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ DataSource.class, JdbcTemplate.class })
@ConditionalOnSingleCandidate(DataSource.class)
@AutoConfigureAfter(DataSourceAutoConfiguration.class)
@EnableConfigurationProperties(JdbcProperties.class)
@Import({ DatabaseInitializationDependencyConfigurer.class, JdbcTemplateConfiguration.class,
NamedParameterJdbcTemplateConfiguration.class })
public class JdbcTemplateAutoConfiguration {}
当 CLASSPATH 中存在 DataSource 和 JdbcTemplate,同时能明确一个主要的 DataSource Bean 时, JdbcTemplateAutoConfiguration 才会生效,而它的配置内容要看 DatabaseInitializationDependencyConfigurer、 JdbcTemplateConfiguration 和 NamedParameterJdbcTemplateConfiguration,重点是后面两个。
JdbcTemplateConfiguration 会在没有配置 JdbcOperations 的实现 Bean 时生效,它的作用是提供一个 JdbcTemplate Bean,这个 Bean 会自动注入现有的 DataSource,并将 spring.jdbc.template.* 的配置项内容设置进来,相关配置及其说明见表 6-6。
表 6-6 spring.jdbc.template.* 的配置项
| 配置项 | 默认值 | 说明 |
|---|---|---|
spring.jdbc.template.fetch-size | -1 | 每次从数据库获取的记录条数, -1 表示使用驱动的默认值 |
spring.jdbc.template.max-rows | -1 | 一次查询可获取的最大记录条数, -1 表示使用驱动的默认值 |
spring.jdbc.template.query-timeout | 查询的超时时间,没有配置的话使用 JDBC 驱动的默认值,如果没有加时间单位,默认为秒 |
NamedParameterJdbcTemplateConfiguration 则比较简单,在能确定一个主要的 JdbcTemplate,同时又没有手动配置 NamedParameterJdbcOperations Bean 时,自动创建一个 NamedParameter-JdbcTemplate Bean,并将 JdbcTemplate 注入其中。
如果我们不希望 Spring Boot 为我们做自动配置,只需要自己创建一个 JdbcTemplate 就可以了,比如像下面这样:
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource) {return new JdbcTemplate(dataSource);
}
6.3 事务管理
说起数据库事务,相信大家一定不会陌生,网上是这么解释它的:
数据库事务是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务由事务开始与事务结束之间执行的全部数据库操作组成。
我们平时接触的系统一般都需要与数据库打交道,管理好操作中的事务就是一道绕不过去的“坎”。直接使用 JDBC 的话,同样会有很多模板化的代码。Spring Framework 又一次展现出了自己在问题抽象上的能力,为我们提供了一套统一的事务抽象,它有声明式和编程式两种使用方式。本节,就让我们来了解一下 Spring Framework 是如何管理事务的。
6.3.1 Spring Framework 的事务抽象
在 Java EE 环境中,事务可以是使用 JTA(Java Transaction API)这样的全局事务,也可以是基于 JDBC 连接的本地事务。实际上,大家日常工作中使用的大多是本地事务。随着分布式系统的发展,很多人会聊到分布式事务的话题,这时可以使用两阶段提交,常见的选择是 TCC。但 如果可以的话,还是建议避免分布式事务,降低系统的复杂度。如无特殊说明,本书中提到的所有事务均指本地事务。
为了消除不同事务对代码的影响,Spring Framework 对事务管理做了一层抽象:无论是全局事务还是本地事务,无论 JDBC 直接操作 SQL 还是对象关系映射,都能在一个模型中去理解和管理事务。这个抽象的核心是事务管理器,即 TransactionManager,它是一个空接口,通常都会将 PlatformTransactionManager 作为核心接口,其中包含了获取事务、提交事务和回滚事务的方法。它的定义是这样的:
public interface PlatformTransactionManager extends TransactionManager {TransactionStatus getTransaction(@Nullable TransactionDefinition definition)throws TransactionException;void commit(TransactionStatus status) throws TransactionException;void rollback(TransactionStatus status) throws TransactionException;
}
DataSourceTransactionManager、 JtaTransactionManager 和 HibernateTransactionManager 这些底层事务管理器都实现了上述接口。对上层业务来说,只要知道能调用 PlatformTransaction-Manager 接口的这几个方法来操作事务就行,事务的差异就这样被屏蔽了。以本地数据源的事务为例,可以像下面这样来配置 DataSourceTransactionManager:
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><property name="dataSource" ref="dataSource"/>
</bean>
用来描述事务定义的 TransactionDefinition 接口中包含了几个与事务密切相关的属性:
- 传播性
- 隔离级别
- 超时时间
- 是否只读
“超时时间”和“是否只读”比较容易理解,而“传播性”和“隔离级别”需要再展开说明一下。
-
传播性
事务传播性分为 7 个级别,对应的,在
TransactionDefinition中定义了 7 个常量,具体信息如表 6-7 所示。表 6-7 事务传播性的相关定义与说明
传播性 值 描述 PROPAGATION_REQUIRED0当前有事务就用当前事务,没有事务就新启动一个事务 PROPAGATION_SUPPORTS1事务不是必需的,可以有事务,也可以没有 PROPAGATION_MANDATORY2一定要存在一个事务,不然就报错 PROPAGATION_REQUIRES_NEW3新启动一个事务,如果当前存在一个事务则将其挂起 PROPAGATION_NOT_SUPPORTED4不支持事务,以非事务的方式运行 PROPAGATION_NEVER5不支持事务,如果当前存在一个事务则抛异常 PROPAGATION_NESTED6如果当前存在一个事务,则在该事务内再启动一个事务 默认的事务传播性会使用
PROPAGATION_REQUIRED,正常情况下这就够了。在上面的 7 种情况中,需要再特殊说明一下PROPAGATION_REQUIRES_NEW和PROPAGATION_NESTED的异同点:它们都会启动两个事务,但前者的两个事务是不相关的,而后者的两个事务存在包含关系。假设使用PROPAGATION_NESTED时两个事务分别为事务 A 和事务 B,事务 A 包含事务 B,事务 B 如果回滚了,事务 A 可以不受事务 B 的影响继续提交,但如果事务 A 回滚了,哪怕事务 B 是提交状态也会被回滚。 -
事务隔离级别
数据库的事务有 4 种隔离级别,隔离级别越高,不同事务相互影响的概率就越小,具体就是出现脏读、不可重复读和幻读的情况。这三种情况的具体描述如下。
- 脏读:事务 A 修改了记录 1 的值但未提交事务,这时事务 B 读取了记录 1 尚未提交的值,但后来事务 A 回滚了,事务 B 读到的值并不会存在于数据库中,这就是脏读。
- 不可重复读:事务 A 会读取记录 1 两次,在两次读取之间,事务 B 修改了记录 1 的值并提交了,这时事务 A 第一次与第二次读取到的记录 1 的内容就不一样了,这就是不可重复读。
- 幻读:事务 A 以某种条件操作了数据表中的一批数据,这时事务 B 往表中插入并提交了 1 条记录,正好也符合事务 A 的操作条件,当事务 A 再次以同样的条件操作这批数据时,就会发现操作的数据集变了,这就是幻读。以
SELECT count(*)为例,发生幻读时,如果两次以同样的条件来执行,结果值就会不同。
不可重复读与幻读看起来很像,但不可重复读强调的是同一条数据在两次读取之间被修改了,而幻读强调的是数据集发生了数据增加或数据删除的情况。
同样的, TransactionDefinition 中也对事务隔离级别做了具体的定义,引用了 JDBC Connection 中的常量,具体信息如表 6-8 所示。
表 6-8 事务隔离级别的相关定义与说明
| 隔离性 | 值 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
ISOLATION_READ_UNCOMMITTED | 1 | 存在 | 存在 | 存在 |
ISOLATION_READ_COMMITTED | 2 | 不存在 | 存在 | 存在 |
ISOLATION_REPEATABLE_READ | 3 | 不存在 | 不存在 | 存在 |
ISOLATION_SERIALIZABLE | 4 | 不存在 | 不存在 | 不存在 |
TransactionDefinition 中的默认隔离级别设置为 -1,使用底层数据源的配置,比如,MySQL 默认的隔离级别是 REPEATABLE_READ,Oracle 默认的隔离级别则是 READ_COMMITTED。
6.3.2 Spring 事务的基本配置
通过 6.3.1 节的介绍,我们知道 Spring Framework 的核心类是 TransactionManager,并且在上下文中需要一个 PlatformTransactionManager Bean,例如, DataSourceTransactionManager 或者 JpaTransactionManager。可以像下面这样来定义一个 PlatformTransactionManager:
@Configuration
public class TransactionConfiguration {@Beanpublic DataSourceTransactionManager transactionManager(DataSource dataSource) {return new DataSourceTransactionManager(dataSource);}
}
这节的标题没有用 Spring Framework 是有原因的—— Spring Boot 为我们提供了一整套事务的自动配置,这远比自己动手配置方便。主要的自动配置类是 DataSourceTransactionManagerAutoConfiguration 和 TransactionAutoConfiguration。
DataSourceTransactionManagerAutoConfiguration 的作用主要是自动配置 DataSourceTransactionManager,具体代码如下所示:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ JdbcTemplate.class, TransactionManager.class })
@AutoConfigureOrder(Ordered.LOWEST_PRECEDENCE)
@EnableConfigurationProperties(DataSourceProperties.class)
public class DataSourceTransactionManagerAutoConfiguration {@Configuration(proxyBeanMethods = false)@ConditionalOnSingleCandidate(DataSource.class)static class DataSourceTransactionManagerConfiguration {@Bean@ConditionalOnMissingBean(TransactionManager.class)DataSourceTransactionManager transactionManager(Environment environment, DataSource dataSource,ObjectProvider<TransactionManagerCustomizers> transactionManagerCustomizers) {// 省略具体代码}// 省略部分代码}
}
当 Spring 上下文中提供了明确的一个 DataSource(只有一个或者标明了一个主要的 Bean),且没有配置 PlatformTransactionManager 时,Spring Boot 会自动创建一个 DataSourceTransactionManager。这里需要特别说明一下 TransactionManagerCustomizers,它是 Spring Boot 的自动配置留下的扩展点,可以让我们通过创建 TransactionManagerCustomizers 来对自动配置的 DataSourceTransactionManager 进行微调。在 Spring Boot 中类似的 XXXCustomizer 还有很多,比如在 Web 相关章节里会看到的 RestTemplateCustomizer。
TransactionAutoConfiguration 会为事务再提供进一步的配置,它主要做了两件事:第一是创建了编程式事务需要用到的 TransactionTemplate;第二是开启了基于注解的事务支持,这部分是由内部类 EnableTransactionManagementConfiguration 来定义的,具体代码如下:
@Configuration(proxyBeanMethods = false)
@ConditionalOnBean(TransactionManager.class)
@ConditionalOnMissingBean(AbstractTransactionManagementConfiguration.class)
public static class EnableTransactionManagementConfiguration {@Configuration(proxyBeanMethods = false)@EnableTransactionManagement(proxyTargetClass = false)@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "false",matchIfMissing = false)public static class JdkDynamicAutoProxyConfiguration {}
@Configuration(proxyBeanMethods = false)@EnableTransactionManagement(proxyTargetClass = true)@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true",matchIfMissing = true)public static class CglibAutoProxyConfiguration {}
}
在配置类上添加 @EnableTransactionManagement 注解就能开启事务支持。Spring Framework 的声明式事务是通过 AOP 来实现的,因此根据 AOP 配置的不同,需要选择是否开启对类的代理。当 spring.aop.proxy-target-class=true 时,可以直接对没有实现接口的类开启声明式事务支持,这也是默认的配置。
实际上,如果我们去翻看 AopAutoConfiguration 的代码,也能看到其中有类似的自动配置。可见,在 Spring Boot 中基于 CGLIB 的 AOP 就是默认的 AOP 代理方式:
@Configuration(proxyBeanMethods = false)
@ConditionalOnProperty(prefix = "spring.aop", name = "auto", havingValue = "true", matchIfMissing = true)
public class AopAutoConfiguration {@Configuration(proxyBeanMethods = false)@ConditionalOnClass(Advice.class)static class AspectJAutoProxyingConfiguration {@Configuration(proxyBeanMethods = false)@EnableAspectJAutoProxy(proxyTargetClass = false)@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "false",matchIfMissing = false)static class JdkDynamicAutoProxyConfiguration {}
@Configuration(proxyBeanMethods = false)@EnableAspectJAutoProxy(proxyTargetClass = true)@ConditionalOnProperty(prefix = "spring.aop", name = "proxy-target-class", havingValue = "true",matchIfMissing = true)static class CglibAutoProxyConfiguration {}}// 其他内容省略
}
TransactionProperties 是事务的属性配置,其中只有两个配置: spring.transaction.default-timeout 用于配置默认超时时间,默认单位为秒; spring.transaction.rollback-on-commit-failure 配置在提交失败时是否回滚。
6.3.3 声明式事务
通常在没有特殊需求的情况下,我们建议使用 Spring Framework 的声明式事务来管理事务。而且如果有一大堆类需要配置事务,声明式事务也会比编程式事务更方便一些。所以,我们会着重介绍声明式事务的使用方式。
-
基于注解的方式
Spring Framework 提供了一个
@Transactional注解,它可以在类型和方法上标注与事务相关的信息。同时,我们也可以使用 JTA 中的@Transactional注解(在javax.transaction包里),两者的作用基本是一样的。在注解中可以设置很多事务属性,具体如表 6-9 所示。表 6-9
@Transactional注解可以设置的事务属性
| 属性 | 默认值 | 描述 |
|---|---|---|
transactionManager | 默认会找名为 transactionManager 的事务管理器 | 指定事务管理器 |
propagation | Propagation.REQUIRED | 指定事务的传播性 |
isolation | Isolation.DEFAULT | 指定事务的隔离性 |
timeout | -1,即由具体的底层实现来设置 | 指定事务超时时间 |
readOnly | false | 是否为只读事务 |
rollbackFor / rollbackForClassName | 空 | 指定需要回滚事务的异常类型 |
noRollbackFor / noRollbackForClassName | 空 | 指定无须回滚事务的异常类型 |
请注意 默认情况下,事务只会在遇到
RuntimeException和Error时才会回滚,碰到受检异常(checked exception)时并不会回滚。例如,我们定义了一个业务异常BizException,它继承的是Exception类,在代码抛出这个异常时,事务不会自己回滚,但我们可以手动设置回滚,或者在rollbackFor中进行设置。
要开启注解驱动的事务支持,有两种方式,在上一节里已经看到过了在配置类上添加 @EnableTransactionManagement 的方式,这里来介绍一下第二种:通过 <tx:annotation-driven/> 这个 XML 标签来启用注解支持,具体如下所示:
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:tx="http://www.springframework.org/schema/tx"xsi:schemaLocation="http://www.springframework.org/schema/beanshttps://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/txhttps://www.springframework.org/schema/tx/spring-tx.xsd">
<!-- 开启事务注解支持,可以明确设置一个TransactionManager --><tx:annotation-driven transaction-manager="txManager"/></beans>
在开启注解驱动事务支持时,除了配置 TransactionManager,还可以进行一些其他配置。 @EnableTransactionManagement 和 <tx:annotation-driven/> 拥有一些共同的配置,如表 6-10 所示。
表 6-10 注解驱动事务支持的部分配置
| 配置项 | 默认值 | 含义 |
|---|---|---|
mode | proxy | 声明式事务 AOP 的拦截方式,默认 proxy 是代理方式,也可以改为 aspectj |
order | Ordered.LOWEST_PRECEDENCE | 声明式事务 AOP 拦截的顺序,值越小,优先级越高 |
proxyTargetClass / proxy-target-class(XML) | false | 是否使用 CGLIB 的方式拦截类 |
虽然这里的默认值是
false,但通过 6.3.2 节的介绍,我们已经知道了在 Spring Boot 中,默认会使用 CGLIB 的方式来做拦截。
在 <tx:annotation-driven/> 中还有一个 transacation-manager 属性,在事务管理器的名字不是 transactionManager 时用来指定事务要使用的事务管理器。但 @EnableTransactionManagement 里却没有这一属性,它会根据类型来做注入。如果希望明确指定使用哪个 TransactionManager,可以让 @Configuration 类实现 TransactionManagementConfigurer 接口,在 annotationDrivenTransactionManager() 方法里返回希望使用的那个 TransactionManager。
在介绍事务传播性时,我们有讲到 PROPAGATION_REQUIRED、 PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的区别。下面我们通过基于注解的声明式事务来实际感受一下它们之间的差别。
通过 Spring Initializr 创建一个新工程,依赖项选择 JDBC API、H2 和 Lombok。在 src/main/resources 目录中创建 schema.sql,添加代码示例 6-23 中的建表语句。
代码示例 6-23 schema.sql 中的建表语句
create table t_demo (id bigint auto_increment,name varchar(128),create_time timestamp,update_time timestamp,primary key (id)
);
接下来我们的试验就是操作 t_demo 表,在不同的事务传播性下插入记录,查看结果,对表的操作如代码示例 6-24 所示。三个插入方法分别使用不同的事务传播性, showNames() 方法返回表中所有的 name 内容。
代码示例 6-24 提供不同事务传播性插入方法的 DemoService 类
package learning.spring.transaction;// 省略import@Servicepublic class DemoService {public static final String SQL ="insert into t_demo (name, create_time, update_time) values(?, now(), now())";@Autowiredprivate JdbcTemplate jdbcTemplate;@Transactional(readOnly = true)public String showNames() {return jdbcTemplate.queryForList("select name from t_demo;", String.class).stream().collect(Collectors.joining(","));}@Transactional(propagation = Propagation.REQUIRED)public void insertRecordRequired() {jdbcTemplate.update(SQL, "one");}@Transactional(propagation = Propagation.REQUIRES_NEW)public void insertRecordRequiresNew() {jdbcTemplate.update(SQL, "two");}@Transactional(propagation = Propagation.NESTED)public void insertRecordNested() {jdbcTemplate.update(SQL, "three");throw new RuntimeException(); // 让事务回滚}}
再用另一个类来组合几个插入方法,不同的组合会有不同的效果,如代码示例 6-25 所示。
代码示例 6-25 调用插入方法的 MixService 类
package learning.spring.transaction;// 省略import@Servicepublic class MixService {@Autowiredprivate DemoService demoService;@Transactionalpublic void trySomeMethods() {demoService.insertRecordRequired();try {demoService.insertRecordNested();} catch(Exception e) {}}}
工程的主类就比较简单了,执行 MixService 的 trySomeMethods() 方法,如代码示例 6-26 所示。
代码示例 6-26 AnnotationDemoApplication 类代码片段
@SpringBootApplication@Slf4jpublic class AnnotationDemoApplication implements ApplicationRunner {@Autowiredprivate MixService mixService;@Autowiredprivate DemoService demoService;public static void main(String[] args) {SpringApplication.run(AnnotationDemoApplication.class, args);}@Overridepublic void run(ApplicationArguments args) throws Exception {try {mixService.trySomeMethods();} catch (Exception e) {}log.info("Names: {}", demoService.showNames());}}
在目前的 trySomeMethods() 中,程序会输出 Names: one,内嵌事务回滚不影响外部事务。如果将 trySomeMethods() 调整为下面这样:
@Transactional
public void trySomeMethods() {demoService.insertRecordRequired();demoService.insertRecordRequiresNew();throw new RuntimeException();
}
那输出就会是 Names: two, Propagation.REQUIRES_NEW,会新启动一个与当前事务无关的事务,提交后如果当前事务回滚了,不会影响已提交内容。
茶歇时间:通常事务加在哪层比较合适?
Spring Framework 虽然为我们提供了声明式的事务,可以将事务与代码剥离,但它并没有告诉我们究竟将事务拦在哪里更合适。
通常情况下,我们会对应用进行分层,划分出 DAO 层、Service 层、View 层等。如果了解过领域驱动设计(Domain-Driven Design,DDD),就会知道其中也有 Repository 和 Service 的概念。一次业务操作一般都会涉及多张表的数据,因此在单表的 DAO 或 Repository 上增加事务,粒度太细,并不能实现业务的要求。而在对外提供的服务接口上增加事务,整个事务的范围又太大,一个请求从开始到结束都在一个大事务里,着实又有些浪费。
所以,事务一般放在内部的领域服务上,也就是 Service 层上会是比较常见的一个做法,其中的一个方法,也就对应了一个业务操作。
-
基于 XML 的方式
看过了注解驱动的事务,再来了解一下如何通过 XML 配置实现相同的功能。
@Transactional注解需要添加在代码里,而 XML 则可以从业务代码剥离,将事务配置与业务逻辑解耦。Spring Framework 提供了一系列
<tx/>的 XML 来配置事务相关的 AOP 通知。有了 AOP 通知后,我们就可以像普通的 AOP 配置那样对方法的执行进行拦截和增强了。其中,
<tx:advice/>用来配置事务通知,如果事务管理器的名字是transactionManager,那就可以不用设置transaction-manager属性了。具体的事务属性则通过<tx:attributes/>和<tx:method/>来设置。<tx:method/>可供设置的属性和@Transactional注解的基本一样,具体见表 6-11。表 6-11
<tx:method/>的属性清单
| 属性 | 默认值 | 含义 |
|---|---|---|
name | 无 | 要拦截的方法名称,可以带通配符,是唯一的必选项 |
propagation | REQUIRED | 事务传播性 |
isolation | DEFAULT | 事务隔离性 |
timeout | -1 | 事务超时时间,单位为秒 |
read-only | false | 是否是只读事务 |
rollback-for | 无 | 会触发回滚的异常清单,以逗号分隔,可以是全限定类名,也可以是简单类名 |
no-rollback-for | 无 | 不触发回滚的异常清单,以逗号分隔,可以是全限定类名,也可以是简单类名 |
可以将前面提到的 annotation-demo 修改一下,去掉所有的 @Transactional 注解,改用 XML 的方式来配置事务,代码放在示例的 ch6/xml-transaction-demo 中。具体的 XML 配置如代码示例 6-27 所示。由于用到了 AspectJ 的切入点,工程中还需要引入 org.springframework.boot:spring-boot-starter-aop 依赖。
代码示例 6-27 完整的 applicationContext.xml 配置示例
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:aop="http://www.springframework.org/schema/aop"xmlns:tx="http://www.springframework.org/schema/tx"xsi:schemaLocation="http://www.springframework.org/schema/beanshttps://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/txhttps://www.springframework.org/schema/tx/spring-tx.xsdhttp://www.springframework.org/schema/aophttps://www.springframework.org/schema/aop/spring-aop.xsd"><tx:advice id="demoTxAdvice"><tx:attributes><tx:method name="showNames" read-only="true"/><tx:method name="insertRecordRequired" propagation="REQUIRED"/><tx:method name="insertRecordRequiresNew" propagation="REQUIRES_NEW"/><tx:method name="insertRecordNested" propagation="NESTED"/></tx:attributes></tx:advice><tx:advice id="mixTxAdvice"><tx:attributes><tx:method name="*" /></tx:attributes></tx:advice><aop:config><aop:pointcut id="demoServiceMethods"expression="execution(* learning.spring.transaction.DemoService.*(..))"/><aop:pointcut id="mixServiceMethods"expression="execution(* learning.spring.transaction.MixService.*(..))"/><aop:advisor advice-ref="demoTxAdvice" pointcut-ref="demoServiceMethods"/><aop:advisor advice-ref="mixTxAdvice" pointcut-ref="mixServiceMethods"/></aop:config></beans>
上面的 XML 中,针对 DemoService 的不同方法配置了不同的传播性,而 DemoService 和 MixService 的事务配置也有所不同。我们可以在工程主类,或者其他带有 @Configuration 注解的配置类上增加 @ImportResource("applicationContext.xml"),导入 XML 配置。程序的运行效果与之前注解驱动的事务一模一样。
茶歇时间:声明式事务背后的原理
Spring Framework 的声明式事务,其本质是对目标类和方法进行了 AOP 拦截,并在方法的执行前后增加了事务相关的操作,比如启动事务、提交事务和回滚事务。
既然是通过 AOP 实现的,那它就必定遵循了 AOP 的各种规则和限制。Spring Framework 的 AOP 增强通常都是通过代理的方式来实现的,这就意味着事务也是在代理类上的。 我们必须调用增强后的代理类中的方法,而非原本的对象,这样才能拥有事务。也就是说调用下面的
methodWithoutTx()并不会启动一个事务:public class Demo {@Trasactionalpublic void methodWithTx() {...}public void methodWithoutTx() {this.methodWithTx();} }我们在第 3 章的 基于代理的“小坑” 中也提到过类似的场景,请务必注意避免这种情况。如果一定要调用自己的方法,可以从
ApplicationContext中获取自己的代理对象,操作这个对象上的方法,而不是使用this。或者,也可以在适当配置下,通过AopContext.currentProxy()来获得当前的代理。
6.3.4 编程式事务
在看过了声明式事务之后,理解编程式事务就不是什么难事了。正如本节标题字面上的意思,Spring Framework 还支持用编程的方式来控制事务,但绝不是简单地调用 Connection 的 setAutoCommit(false) 来启动事务,结束时调用 commit() 或 rollback() 提交或回滚事务,而是将这些流程固化到了模板类中。和 JdbcTemplate 类似,Spring Framework 为事务提供了一个 TransacationTemplate。
Spring Boot 在 TransactionAutoConfiguration 中包含了一个内部类 TransactionTemplateConfiguration,会自动基于明确的 PlatformTransactionManager 创建 TransactionTemplate,手动创建也很简单:
@Configuration
public class TxConfiguration {@Beanpublic TransactionTemplate transactionTemplate(PlatformTransactionManager transactionManager) {return new TransactionTemplate(transactionManager);}
}
在使用时,我们主要用它的 execute() 和 executeWithoutResult() 方法,方法的声明形式如下所示:
public <T> T execute(TransactionCallback<T> action) throws TransactionException;
public void executeWithoutResult(Consumer<TransactionStatus> action) throws TransactionException;
TransactionCallback 接口就一个 doInTransaction() 方法,通常都是直接写个匿名类,或者是 Lambda 表达式。我们简单修改一下代码示例 6-24 中的几个方法,看看编程式事务该怎么写。查询类方法 showNames() 可以改写成代码示例 6-28 的样子。
代码示例 6-28 查询方法示例
// Lambda形式
public String showNamesProgrammatically() {return transactionTemplate.execute(status -> jdbcTemplate.queryForList("select name from t_demo;", String.class).stream().collect(Collectors.joining(",")));
}// 匿名类形式
public String showNamesProgrammatically() {return transactionTemplate.execute(new TransactionCallback<String>() {@Overridepublic String doInTransaction(TransactionStatus status) {return jdbcTemplate.queryForList("select name from t_demo;", String.class).stream().collect(Collectors.joining(","));}});
}
如果是更新类的操作,则没有返回值,比如 insertRecordRequired(),可以改写为代码示例 6-29 的样子。通过这两个例子,相信大家一定发现了,Lambda 表达式比起匿名类的形式要简洁很多,因此建议大家平时多多考虑 Lambda 表达式。
代码示例 6-29 没有返回值的示例
// Lambda形式
public void insertRecordRequiredProgrammatically() {transactionTemplate.executeWithoutResult(status -> jdbcTemplate.update(SQL, "one"));
}// 匿名类形式
public void insertRecordRequiredProgrammatically() {transactionTemplate.execute(new TransactionCallbackWithoutResult() {@Overrideprotected void doInTransactionWithoutResult(TransactionStatus status) {jdbcTemplate.update(SQL, "one");}});
}
如果希望修改事务的属性,可以直接调用 TransactionTemplate 的对应方法,或者在创建时将其作为 Bean 属性配置进去,这里建议使用对应的常量,而非写成固定的一个数字。这些属性是设置在对象上的,如果要在不同的代码中复用同一个 TransactionTemplate 对象,请确认它们可以使用相同的配置。
在代码中设置传播性与隔离性,可以使用 setPropagationBehavior() 和 setIsolationLevel() 方法,如果是在 XML 配置中设置 Bean 属性,则可以选择对应的 propagationBehaviorName 和 isolationLevelName 属性。
6.4 异常处理
在使用传统的 JDBC 操作数据库时,我们不得不面对异常处理的问题,只捕获 SQLException 的粒度太粗,根据其中的 SQLState 和 ErrorCode 可以大致分析出特定数据库的错误,但换了一个数据库,错误码一改就得重头来过。
不同数据库的 JDBC 驱动中也会定义一些 SQLException 的子类,只是捕获特定数据库的异常类就会把代码和底层数据库彻底“绑死了”,万一遇到变更底层数据库类型的情况,就会非常被动,例如碰上了公司要“去 O”,那这些异常处理逻辑几乎得重写。
Spring Framework 为我们提供了一套统一的数据库操作异常体系,它独立于具体的数据库产品,甚至也不依赖 JDBC,支持绝大多数常用数据库。它能将不同数据库的返回码翻译成特定的类型,开发者只需捕获并处理 Spring Framework 封装后的异常就可以了。
6.4.1 统一的异常抽象
Spring Framework 的数据库操作异常抽象从 DataAccessException 这个类开始,所有的异常都是它的子类。无论是使用 JDBC,还是后续要介绍到的对象关系映射,都会涉及这套抽象,图 6-1 展示了其中部分常用的异常类。

图 6-1 统一数据库操作异常抽象中部分常用的异常类
可以看到,这套异常覆盖了绝大部分的常见异常,例如,违反了唯一性约束就会抛出的 DataIntegrityViolationException,针对主键冲突的异常,还有一个 DuplicateKeyException 子类,我们可以根据这些异常清晰地判断究竟发生了什么问题。
那 Spring Framework 又是怎么来理解和翻译这么多不同类型的数据库异常的呢?这背后的核心接口就是 SQLExceptionTranslator,它负责将不同的 SQLException 转换为 DataAccessException。 SQLExceptionTranslator 及其重要实现类的关系如图 6-2 所示。
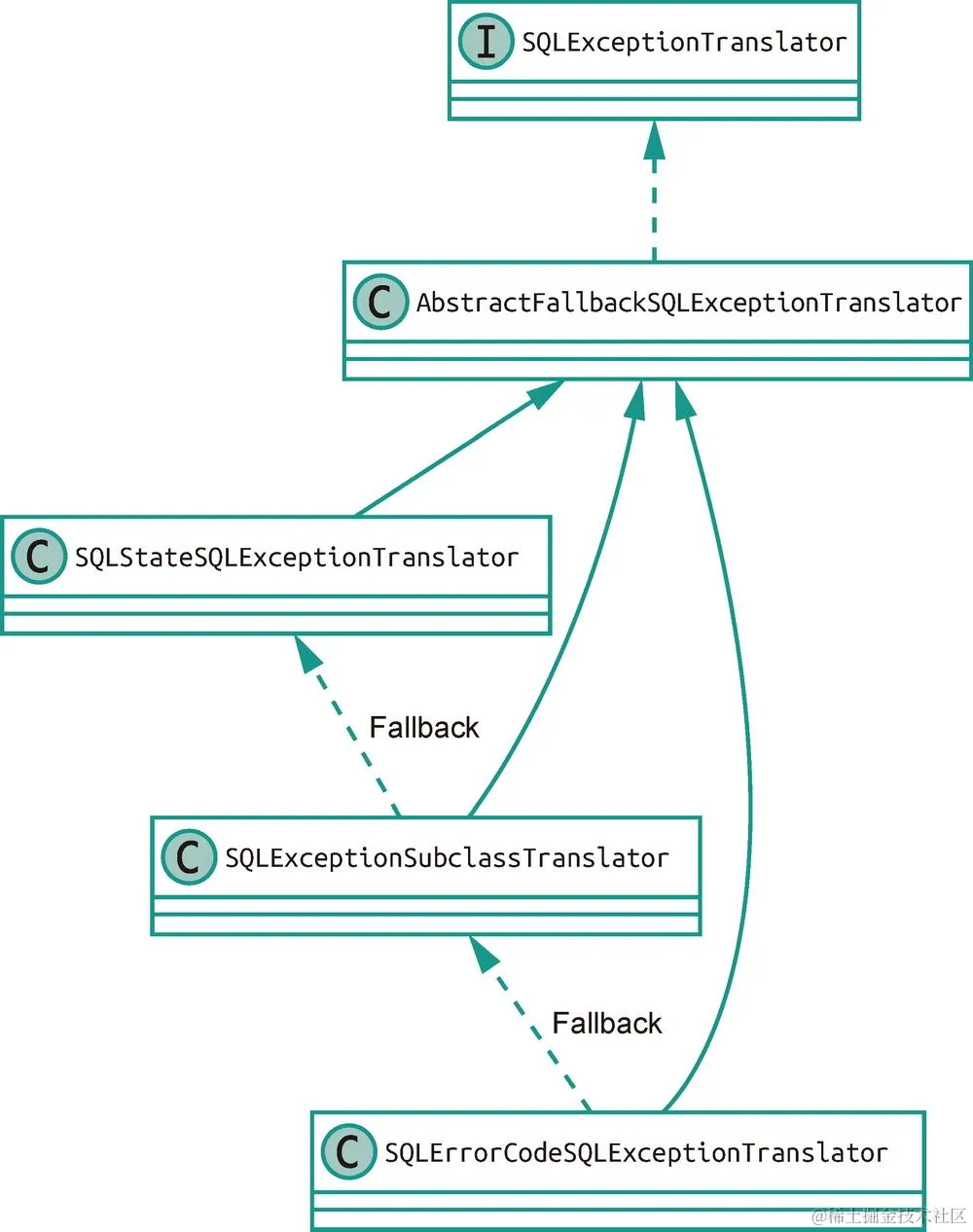
图 6-2 SQLExceptionTranslator 及其重要实现类的关系
图中的 SQLStateSQLExceptionTranslator 会分析异常中的 SQLState,根据标准 SQLState 和常见的特定数据库 SQLState 进行转换; SQLExceptionSubclassTranslator 根据 java.sql.SQLException 的子类类型进行转换;而 SQLErrorCodeSQLExceptionTranslator 则是根据异常中的错误码进行转换的。
JdbcTemplate 中会创建一个默认的 SQLErrorCodeSQLExceptionTranslator,根据数据库类型选择不同配置来进行实际的异常转换,所以让我们来具体看看它的实现。 SQLErrorCodeSQLExceptionTranslator 会通过 SQLErrorCodesFactory 来获取特定数据库的错误码信息, SQLErrorCodesFactory 默认从 CLASSPATH 的 org/springframework/jdbc/support/sql-error-codes.xml 文件中加载错误码配置,这是一个 Bean 的配置文件,其中都是 SQLErrorCodes 类型的 Bean。这个文件中包含了 MySQL、Oracle、PostgreSQL、MS-SQL 等 10 余种常见数据库的错误码信息,例如下面就是 MySQL 的配置,可以看到它将错误码与具体的异常类型关联了起来:
<bean id="MySQL" class="org.springframework.jdbc.support.SQLErrorCodes"><property name="databaseProductNames"><list><value>MySQL</value><value>MariaDB</value></list></property><property name="badSqlGrammarCodes"><value>1054,1064,1146</value></property><property name="duplicateKeyCodes"><value>1062</value></property><property name="dataIntegrityViolationCodes"><value>630,839,840,893,1169,1215,1216,1217,1364,1451,1452,1557</value></property><property name="dataAccessResourceFailureCodes"><value>1</value></property><property name="cannotAcquireLockCodes"><value>1205,3572</value></property><property name="deadlockLoserCodes"><value>1213</value></property>
</bean>
SQLErrorCodeSQLExceptionTranslator 会先尝试 SQLErrorCodes 中的 customSqlExceptionTranslator 来转换,接着再尝试 SQLErrorCodes 中的 customTranslations,最后再根据配置的错误码来判断。如果最后还是匹配不上,就降级到其他 SQLExceptionTranslator 上。
6.4.2 自定义错误码处理逻辑
Spring Framework 针对常见数据库异常的处理已经比较完善了,但在一些特殊场景中,默认的逻辑并不能满足我们的需求。假设在公司内部有一套自己的数据库代理中间件,能在应用与实际的数据库之间提供连接收敛、请求路由、分库分表等功能,对外提供 MySQL 协议,但又扩展了一些其他的功能:通过特定的错误码向上返回某些扩展的状态,这些错误码超出了默认的范围。
在看过了 Spring Framework 处理数据库错误码的逻辑之后,我们很快就能想到去扩展 SQLErrorCodes。 SQLErrorCodesFactory 其实也预留了扩展点,它会加载 CLASSPATH 根目录中的 sql-error-codes.xml 文件,用其中的配置覆盖默认配置。 CustomSQLErrorCodesTranslation 提供了根据错误码来映射异常的功能,代码示例 6-30 演示了如何通过它来扩展 MySQL 的异常配置。
代码示例 6-30 使用 CustomSQLErrorCodesTranslation 来扩展 MySQL 异常码逻辑
<bean id="MySQL" class="org.springframework.jdbc.support.SQLErrorCodes"><property name="databaseProductNames"><list><value>MySQL</value><value>MariaDB</value></list></property><property name="badSqlGrammarCodes"><value>1054,1064,1146</value></property><property name="duplicateKeyCodes"><value>1062</value></property><property name="dataIntegrityViolationCodes"><value>630,839,840,893,1169,1215,1216,1217,1364,1451,1452,1557</value></property><property name="dataAccessResourceFailureCodes"><value>1</value></property><property name="cannotAcquireLockCodes"><value>1205,3572</value></property><property name="deadlockLoserCodes"><value>1213</value></property><property name="customTranslations"><bean class="org.springframework.jdbc.support.CustomSQLErrorCodesTranslation"><property name="errorCodes" value="123456" /><property name="exceptionClass" value="learning.spring.data.DbSwitchingException" /></bean></property>
</bean>
当然,还有另一种做法,即直接继承 SQLErrorCodeSQLExceptionTranslator,覆盖其中的 customTranslate(String task, @Nullable String sql, SQLException sqlEx) 方法,随后在 JdbcTemplate 中直接注入我们自己写的类实例。不过,在大部分情况下,前一种方法已经能够满足我们的需求了,大家可以根据实际情况来选择具体的方案。
6.5 小结
本章我们学习了 Spring Framework 中数据库操作的基础知识,尤其是聚焦在了数据源配置、JDBC 基础操作、事务管理和异常处理这四点上。
其中,我们详细了解了 Spring Boot 2. x 推荐的 HikariCP 数据库连接池及其配置,以及如何用 Druid 来替换 HikariCP。并且我们还了解了 Spring 是如何帮助我们来简化 JDBC 操作的, JdbcTemplate 在各种场景中都非常好用。在事务管理和异常处理部分,不仅学习到了怎么运用这些东西,更是深入了解了它们背后的实现逻辑。
下一章,我们将从 JDBC 切换到通过对象关系映射来操作数据库,看看在 Spring 中如何来使用 Hibernate 与 MyBatis。
二进制奶茶店项目开发小结
本章我们为二进制奶茶店的核心服务 BinaryTea 增加了一个数据源,在其中存储了店铺中的菜单信息。此外,还为菜单表提供了相应的增加、删除和查询方法,并且在启动工程时还会初始化菜单并打印菜单的内容。
在实际工作中,直接使用 JDBC 来做增删改查操作并不友好,更多的情况下还是会使用对象关系映射框架,下一章会对本章的 JDBC 代码进行比较大的重构。