代码网站模板怎么做关键词排名怎么查


🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
- 常见分类算法解析
- 1. 逻辑回归(Logistic Regression)
- 2. 朴素贝叶斯(Naive Bayes)
- 3. 决策树(Decision Tree)
- 4. 支持向量机(Support Vector Machine, SVM)
- 5. K近邻算法(K-Nearest Neighbors, KNN)
- 6. 神经网络(Neural Network)
常见分类算法解析
在机器学习领域,分类算法是用于预测数据所属类别的重要工具,它们能够对大量数据进行模式识别与分析,为复杂问题提供决策支持。本文将深入探讨几种常见的分类算法,包括逻辑回归、朴素贝叶斯、决策树、支持向量机、K近邻算法以及神经网络,通过介绍其基本原理、适用场景及优缺点,帮助读者全面理解并合理选择合适的分类方法。
1. 逻辑回归(Logistic Regression)

基本原理: 逻辑回归是一种广义线性模型,主要用于处理二分类问题,通过构建一个非线性函数(Sigmoid函数)将输入特征映射到(0,1)区间内,表示样本属于正类的概率。训练过程旨在找到使得预测概率与实际标签间误差最小化的模型参数。
适用场景: 逻辑回归适用于特征与目标变量关系相对简单、线性可分或者近似线性可分的问题,如信用评分、疾病诊断、广告点击率预测等。
优点:
- 模型解释性强,易于理解。
- 训练速度快,对大规模数据友好。
- 可通过特征缩放、引入多项式特征等方式处理非线性关系。
缺点:
- 对于非线性关系复杂的分类问题表现不佳。
- 对异常值敏感,易受过拟合影响。
2. 朴素贝叶斯(Naive Bayes)
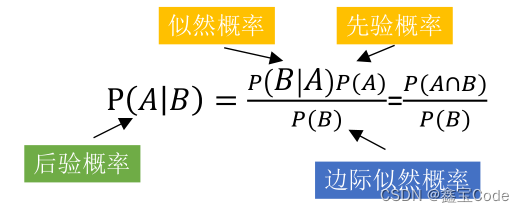
基本原理: 朴素贝叶斯算法基于贝叶斯定理和特征条件独立假设,计算给定样本属于各类别的后验概率,并选择最大后验概率对应的类别作为预测结果。尽管“特征条件独立”假设在实际中往往不成立,但朴素贝叶斯在许多情况下仍表现出良好的性能。
适用场景: 朴素贝叶斯适用于文本分类、垃圾邮件检测、情感分析等高维稀疏数据场景,尤其当数据集较小、特征之间相关性较弱时效果良好。
优点:
- 计算效率高,对大规模数据友好。
- 对缺失数据不太敏感,不需要大量的数据预处理。
- 在某些场景下,即使特征条件独立假设不严格成立,也能取得不错的效果。
缺点:
- “特征条件独立”假设过于简化,可能影响模型精度。
- 对输入数据分布有一定的假设,对非高斯分布数据或存在相关性的数据适应性较差。
3. 决策树(Decision Tree)
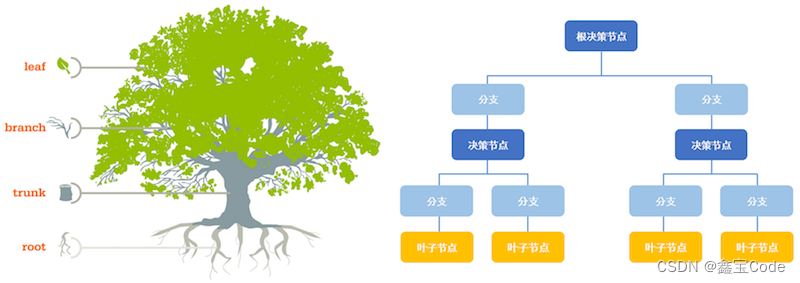
基本原理: 决策树通过递归地划分数据空间,构建一棵反映从根节点到叶节点的决策路径的树形结构。每个内部节点代表一个特征测试,每个分支对应一个特征值,叶节点则表示最终的类别预测。
适用场景: 决策树广泛应用于银行信贷风险评估、医疗诊断、客户细分等领域,尤其适合处理具有规则性和可解释性需求的任务。
优点:
- 结果易于理解和解释,可直接生成规则。
- 能够处理数值型和类别型数据,无需进行数据标准化。
- 能够处理多重输出问题,支持并行化训练。
缺点:
- 容易过拟合,需通过剪枝、设置深度限制等手段进行调整。
- 对输入数据的微小变化敏感,可能导致决策树结构发生较大变化。
- 可能偏向于选择特征数较多的特征进行分割,导致过拟合。
4. 支持向量机(Support Vector Machine, SVM)
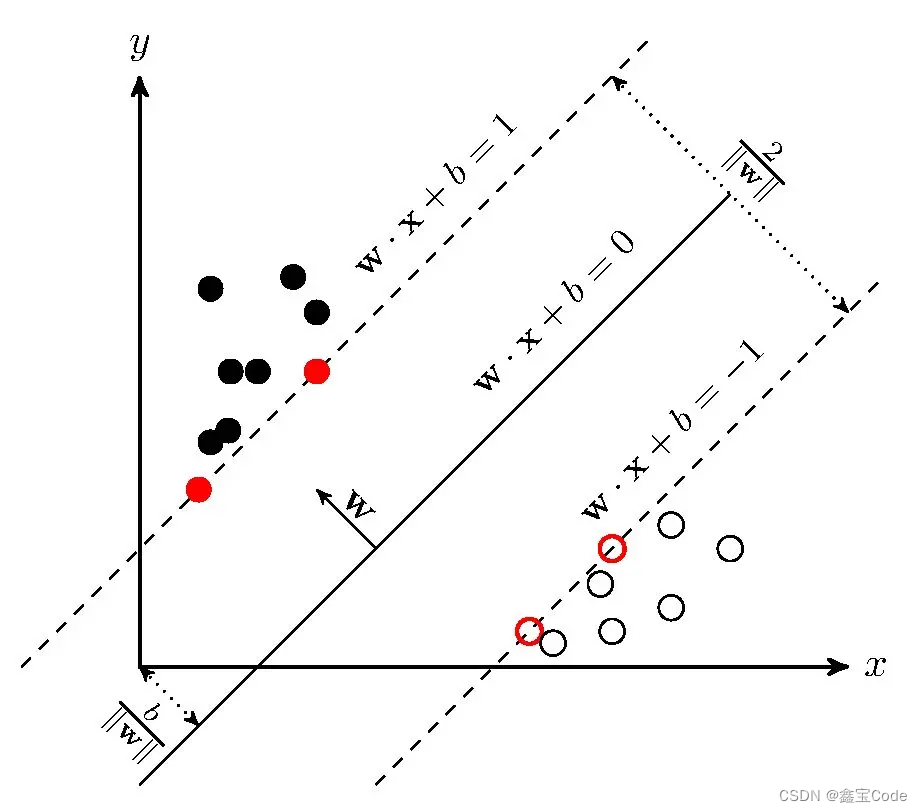
基本原理: SVM是一种基于结构风险最小化原则的分类方法,旨在寻找一个最优超平面以最大化两类样本之间的间隔。通过引入核函数,SVM可以有效处理非线性分类问题。
适用场景: SVM适用于小样本、非线性、高维数据的分类任务,如手写数字识别、文本分类、生物信息学中的序列分类等。
优点:
- 泛化能力强,对小样本数据有很好的分类效果。
- 通过核函数可以处理非线性分类问题,且无需显式地进行特征转换。
- 对异常值不敏感,鲁棒性较好。
缺点:
- 训练时间随着样本数量和特征维度增加而显著增长。
- 对大规模数据集和高维数据处理效率较低,需要进行降维或使用核函数加速。
- 参数选择对模型性能影响较大,需要通过交叉验证等方式进行调优。
5. K近邻算法(K-Nearest Neighbors, KNN)
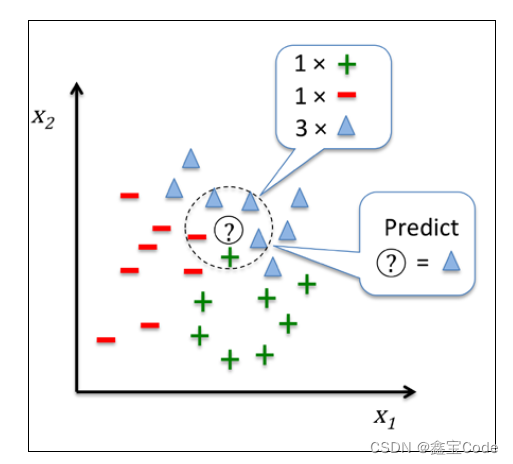
基本原理: KNN是一种基于实例的学习方法,预测时通过计算待分类样本与训练集中每个样本的距离,选取距离最近的K个邻居,根据这K个邻居中多数类别的投票结果决定待分类样本的类别。
适用场景: KNN适用于连续数值型和离散型数据的分类,常用于图像识别、推荐系统、医学诊断等领域。
优点:
- 算法原理简单,易于实现。
- 可以处理多分类任务,适用于非线性分类问题。
- 无须事先假设数据分布,对异常值不敏感。
缺点:
- 计算复杂度随样本数和特征数增加而增大,对大规模数据集效率低下。
- 需要选择合适的距离度量方法和K值,对参数敏感。
- 对输入数据的规模和维度敏感,未进行特征缩放可能导致预测结果偏差。
6. 神经网络(Neural Network)
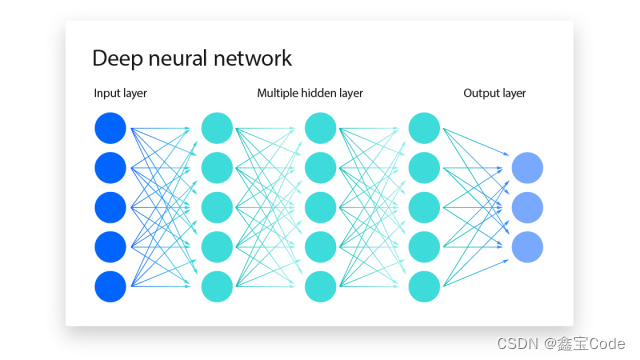
基本原理: 神经网络是一种模仿人脑神经元工作方式的非线性模型,由输入层、隐藏层(可有多个)和输出层组成。通过反向传播算法调整网络权重,使得网络输出尽可能接近真实标签。
适用场景: 神经网络适用于各种复杂分类问题,特别是在图像识别、语音识别、自然语言处理等领域表现出色。
优点:
- 具有强大的非线性表达能力,能捕获复杂的数据分布和模式。
- 通过增加网络层数和节点数,可以应对高维、大规模数据。
- 可以与其他技术(如卷积、循环等)结合,处理特定类型的数据。
缺点:
- 训练过程可能较慢,且容易陷入局部最优。
- 需要大量标注数据进行训练,对数据质量要求较高。
- 模型结构复杂,解释性相对较差。
总结来说,选择合适的分类算法应综合考虑数据特性、任务需求、计算资源等因素。逻辑回归、朴素贝叶斯适用于线性关系明显、解释性要求高的场景;决策树、KNN在中小规模数据上表现良好,易于理解;支持向量机擅长处理小样本、非线性问题;神经网络则在处理复杂、高维数据时展现强大能力。实际应用中,可能还需要结合集成学习、特征选择等技术进一步提升分类性能。

