工信部网站备案要求厦门最快seo
说到 Linux 内核 TCP 性能(不单指 TCP,但以 TCP 为最佳实例),VJ(范·雅各布森) 早年(2006 年)有个 talk:Speeding up Networking,提出:
- 让使用数据的 task 所在的 CPU 在 task context 处理 TCP 数据;
配套 lwn 参见 Van Jacobson’s network channels:
The key to better networking scalability, says Van, is to get rid of locking and shared data as much as possible, and to make sure that as much processing work as possible is done on the CPU where the application is running. It is, he says, simply the end-to-end principle in action yet again. This principle, which says that all of the intelligence in the network belongs at the ends of the connections, doesn’t stop at the kernel. It should continue, pushing as much work as possible out of the core kernel and toward the actual applications.
导图如下,我只将相关截图拼接在了一起,来龙去脉自行阅读上述链接:
VJ 将端到端原则发挥到了极致,但忽略了一个因素,彼时 CPU 即将被网卡超越,CPU 即将成为超级瓶颈。锁,cacheline 等单机指标相对 CPU 瓶颈根本不值得一提。
所以,虽然 “pushing as much work as possible out of the core kernel and toward the actual applications.”,但这 application 所在的 CPU 太拥挤了怎么办?我给出与 VJ 基调一致但不太认同的观点:
- 让单独的 CPU 处理 TCP,让使用 TCP 数据的 task 运行在与 TCP 共享 cache 的其它核心,二者通过 ring-buffer 交互;
- 如 VJ 所说,Linux 内核协议栈没坏,不需要修复,它真的不需要修复,要改的是应用程序使用数据的方式。
- TCP 协议与 CPU 同构的串行本质是性能 issue 的占比巨大的主因,而不是 CPU 处理它的方式;
同样基于端到端原则,在由 CPU 连接而成的瓶颈管道中串联起 TCP 数据的接收和 TCP 数据的使用。
以下正文部分可看作 15 年前自己写的一篇散装文字 评价 Linux 协议栈 TCP 实现中的 prequeue 连同上述 VJ’s talk 的读后感。相同的话题再说一遍,但这次侧重分析 Linux 内核 TCP 本身。
一个进程(线程)接收 TCP 数据最好的方式就是仅从接收 buffer 将数据取出(最好是个支持原子取的 ring-buffer),而 TCP 的协议处理全部在协议栈的另一个 CPU 上进行,但 Linux 内核 TCP 偏不是这样,相反,其 socket 层实现就像个抽水泵,将 TCP 的处理几乎完全吸附到进程上下文,进而增加了时延,降低了吞吐。
Linux 内核 TCP 实现的结构如下:
// kernel TCP(softirq)
int tcp_v4_rcv(struct sk_buff *skb)
{if (!sock_owned_by_user(sk)) {ret = tcp_v4_do_rcv(sk, skb);} else {tcp_add_backlog(sk, skb)) {}
}// socket(task context)
void __release_sock(struct sock *sk)
{while ((skb = sk->sk_backlog.head) != NULL) {tcp_v4_do_rcv(sk, skb); }
}
不管一条 TCP 流 ingress 流量初始如何,只要它越来越大,task 势必花更多时间 own socket 处理 recv,就会有更多数据被送入 backlog,这将花费 task 更多时间在 release_sock 中处理 backlog,最终形成正反馈,一台抽水泵产生,数据包被吸附在 task,直逼 task 所在的 CPU 触发瓶颈。
应用程序自以为一次 recv 只是一次 socket 系统调用,但事实上 recv 花掉大量时间处理 TCP 逻辑,本该给 task 的时间被 TCP 分走,一个 CPU 干了两件事,吞吐自然降低,而内核 TCP 本应该直接回 ack 的行为被延迟到了 task 上下文,又增加了时延,真是赔了夫人又折兵。
在前面 40 多年,这一直不是问题,因为大部分时间的瓶颈在网卡而不是 CPU,进入 1000Mbps 时代问题才刚凸显,而这不过十多年。在大多数时间内,内核的 TCP 处理和 task 处理均可默契地 pingpong 接力,各占均匀部分。
可从 VJ’s tcp prequeue 这个历史机制感受曾经的田园牧歌时代。彼时 CPU 上的 task 总在 waiting,那么 prequeue 的技巧就在于,把 TCP 处理交给 task,谁空闲谁集中做事,用好 cacheline,这样 softirq 也好立马返回取下一个数据包。
下面是裁剪后的逻辑,注释(就是 VJ 提的)代码一起看:
// kernel TCP(softirq)
int tcp_v4_rcv(struct sk_buff *skb)
{if (!sock_owned_by_user(sk)) {if (!tcp_prequeue(sk, skb)) // 尽量推给 task contextret = tcp_v4_do_rcv(sk, skb);} else if (tcp_add_backlog(sk, skb)) {goto discard_and_relse;}
}/* Packet is added to VJ-style prequeue for processing in process* context, if a reader task is waiting. Apparently, this exciting* idea (VJ's mail "Re: query about TCP header on tcp-ip" of 07 Sep 93)* failed somewhere. Latency? Burstiness? Well, at least now we will* see, why it failed. 8)8) --ANK**/
bool tcp_prequeue(struct sock *sk, struct sk_buff *skb)
{if (sysctl_tcp_low_latency) return false;__skb_queue_tail(&tp->ucopy.prequeue, skb);wake_up_interruptible_sync_poll(sk_sleep(sk),POLLIN | POLLRDNORM | POLLRDBAND);if (!inet_csk_ack_scheduled(sk))inet_csk_reset_xmit_timer(sk, ICSK_TIME_DACK,(3 * tcp_rto_min(sk)) / 4,TCP_RTO_MAX);return true;
}
考虑到 prequeue 对时延敏感类应用的影响,比如时延峰值造成的抖动以及其它未知影响,Linux 内核保留了:
- sysctl 参数 tcp_low_latency,一个可以取消 prequeue 的配置;
- 最长 ack 延迟 timer,确保 ack 不会由于 task 未被 schedule 而耽误太久;
关于 prequeue 的一个讨论,参见 TCP prequeue performance。
随着编程模型的发展,task 不再阻塞接收:
This only works if the socket being processed belongs to a process that
blocks in recv on this socket. In practice, this doesn’t happen anymore that
often, as servers normally use an event driven (epoll) model.
于是 prequeue 就下课了:[RFC,net-next,1/6] tcp: remove prequeue support。此后 Linux 内核空留一个僵尸配置 tcp_low_latency 很久,显然它早就没了用。
但 task context 作为处理 TCP 大泵继续强力抽取数据包,最终能预料到的就是 busy-polling 被引入。反正 softirq 也没什么机会处理 TCP 而只是转交一下,socket API(在 tcp_recvmsg 函数) 在 task context 直接调用 netif_receive_skb,直到 tcp_v4_rcv,亲自处理 TCP 更高尚。
在 task context 处理 TCP 的意义(“意义” 并非 “好处” 的代名词)在于,它能最大限度将 TCP 连接公平性保证交给 task 调度公平性,Linux 内核网络协议栈处理(不局限于 TCP,特别是小包)确实存在公平性问题,比如 softirq 干满 CPU 而饿死进程,但公平性的代价就是 TCP 连接的时延,抖动将不可控,task 调度也是一个统计复用系统,跟 buffer 中排队一样。
另一方面,无论在哪里处理 TCP,尽量 batch 可减少元处理及其带来的上下文切换,抠出那么一点性能,比如 TSO/GRO,Big TCP,最近的一个这方面的优化在 tcp: defer regular ACK while processing socket backlog,说的是 “try to send a cumulative ACK at the end. Increase single TCP flow performance on a 200Gbit NIC by 20%”, 很棒,虽然这些也都是还要付出些时延抖动的代价。
可见,在高速网络环境,Linux 内核 TCP 的处理实际上成了一个内核零存,task 整取的过程,若 CPU 能力一定,当整个 CPU 核全忙时,处理 TCP 的时间越多,处理业务时间越少,反之如果 CPU 花时间处理业务,留给处理 TCP 的时间就会少,如果将 task 亦看作端到端(数据视角,从数据的产生到消亡)处理一环的话,这里就是个瓶颈点,CPU 能力限制了整体吞吐的上限。
既然 TCP 的接收处理逻辑总被吸到 task context,在你的代码改成下面的架构前还没资格说 Linux 内核 TCP 慢:
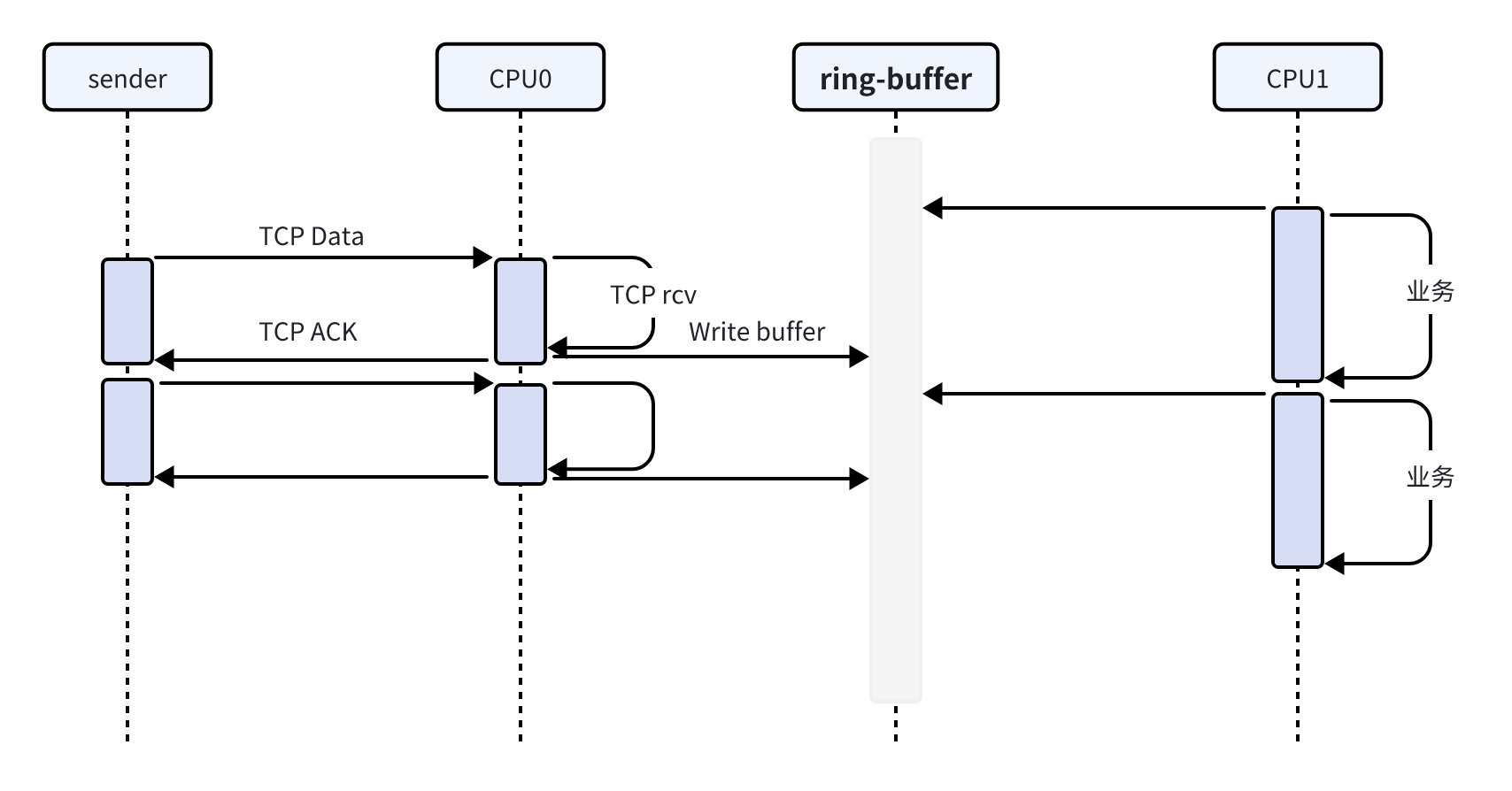
Linux 内核 TCP 本意并非一开始就想将接收逻辑吸到 task context,理想情况下,内核 TCP 当然希望在单独 CPU 的 BH 上下文中处理 TCP 接收,将按序数据送入应用程序的 receive_queue 中准备好,wakeup 在睡眠等待数据的 task 收取数据,自己返回做下一轮,这种接力显然就是上述时序图展示的。
在早期的应用编程模型中,阻塞接收很常见,前文提到,那时瓶颈在网络,往往求数据而不得,又没其它事务做,只能等。讽刺的是,恰恰这种低时延高吞吐的 pipeline 生不逢时,到网络性能反超,CPU 成为瓶颈,TCP 被吸入 task CPU 时,反而降低了吞吐效率,优化手段恰恰要用高时延峰值带来的抖动来换吞吐,还换不了太多。
最后要说的是一些不限于 TCP 的 Linux 内核常规优化。
常规优化手段典型的是拆解一把 spinlock,无非 per-cpu 化,RW 化,Hash 化,RCU 化,但不要期待 TCP 处理也能因此大幅提高性能。除了建连阶段 inet_check_established 需互斥外,established 传输期间几乎不会遭遇锁害,看似要用锁互斥的其实都不需要,比如 scoreboard 和 rtxq,因为 TCP 全程加锁,分别是 spinlock 和 owner 两类,task context 处理 TCP 期间,BH 的 TCP spinlock 则可瞬间拿到。仍需注意 TCP 处理期间公共数据的分配和释放涉及的锁,如 skb,则尽量使用 per-cpu 甚至开辟 per-connection 的池子,但这并不太重要。
至于 TCP 下层的协议栈逻辑,包括不限于 Netfilter,demux,IP 处理,Linux 内核协议栈早已被鄙视多年,经理们纷纷用替换 Linux 内核协议栈而为自己获得卷案,不关注。
当优化手段如这么拧巴挤牙膏时,除了考虑架构问题,连 TCP 本身都要被质疑。
本质上,还是因为 TCP 必须串行的协议,就一定会受限于单 CPU 瓶颈,因为 CPU 本身就是串行的。将一条 TCP 分拆到多个 CPU 上跟在一个 CPU 上多线程跑计算密集型任务一样没意义,代价太大且没收益。
对于 MPTCP,前文说过,设所有路径中最长传输时延为 T maxdelay \text{T}_{\text{maxdelay}} Tmaxdelay,重排序时延为 T reorder \text{T}_{\text{reorder}} Treorder,那么只要 T maxdelay + T reorder < W ⋅ 2 ⋅ T maxdelay \text{T}_{\text{maxdelay}}+\text{T}_{\text{reorder}}<W\cdot2\cdot\text{T}_{\text{maxdelay}} Tmaxdelay+Treorder<W⋅2⋅Tmaxdelay,就是值得的,但让 Linux 内核 TCP 并不支持多 CPU 并行处理多路径,Linux MPTCPv1 虽然每个 subflow 有一把独立的锁,但依然会把 subflow TCP 流程吸附到 task context(在 mptcp_recvmsg 函数),在 subsocket release 时处理:
static void mptcp_push_release(struct sock *ssk, struct mptcp_sendmsg_info *info)
{tcp_push(ssk, 0, info->mss_now, tcp_sk(ssk)->nonagle, info->size_goal);release_sock(ssk);
}
而 MPTCPv0 则是直接 lock meta:
if (!sock_owned_by_user(meta_sk)) {ret = tcp_v4_do_rcv(sk, skb);
} else if (tcp_add_backlog(meta_sk, skb)) {goto discard_and_relse;
}
另一些 MPTCP 实现可参考各大厂纷纷卷出来的 DPDK MPTCP,而更广泛的 OpenWRT 聚合路由器,则完全基于 Linux 内核 TCP 实现,既无性能,也无声望。
总之,无论主机端,还是网络,并行处理怎么都不容易。
总结一下 Linux 内核 TCP(不管是标准 TCP 还是 MPTCP) 的特点和经验。
Linux 内核 TCP 的特征在于将 TCP 吸附到 task context 处理,这挤压了 CPU 处理业务的时间,经验倾向于让单独的 CPU 全力处理 TCP 逻辑而完全不处理业务逻辑,这意味 Linux 内核 TCP 并没有坊间传的拉跨被 DPDK TCP 降维吊打,错的可能是你的应用架构,而 DPDK 则利用独占 CPU 核心的理念,或强制,或设置障碍让单独 CPU 不能既处理 TCP 逻辑又处理业务逻辑。
比较 Linux 内核 TCP 和 DPDK TCP 相当于让雅典面对斯巴达,当它们共同面对波斯而被历史打分时,雅典表现的赢面很大,当它们在伯罗奔尼撒战争对局死磕时,斯巴达能赢,但也废了。
So?TCP 是串行的,CPU 亦串行,网络更好时,CPU 是瓶颈,反之网络是瓶颈,恰好概率极低,因此总有一个利用率不足,单独优化哪个都不行,这又印证了 TCP 是个 scale out 协议,不适用 CPU,网卡的 scale up 扩展而获得最高性价比的性能提升。
再看 Homa 作者对 TCP 特征的总结(虽然负面居多):It’s Time to Replace TCP in the Datacenter,对 TCP 的性能就会有更深刻的认知,这无关实现,这是协议的事。增加不能让一台手术变得高效反而弄巧成拙,但对于搬砖却是经理越多越好,跟人无关,事的属性决定。
回到文初 VJ-style 主机优化,用下一段总结并结束。
以太网进化到 800Gbps+,其内部逐渐绑定多路串行通道而不再试图优化单串行通道,如 4×100G,16×100G,8×200G,而 CPU 早就开始了部署多个很难再提升性能的单核到一个封装以至众核处理器,这是个趋势,但在软件方面,却一直有人希望让数据中心里 TCP 在网卡和 CPU 军备竞赛的夹缝里不断适应,而不是设计新协议也学它们的样子,并行多个串行流,再充分利用网卡和 CPU 的算力去串行化重组。
在高速网络时代优化 TCP,同源同核,cacheline 利用,无锁化,TSO,RSS,… 无论再怎么折腾,都类似在高铁时代快马加鞭。但在数据中心的另一侧,广域网端到端带宽还在百 Mbps 不过 Gbps 时代,这仍是 TCP 的舞台。
顺便提一句,我反对任何用户态 TCP(不限于 DPDK) 的理由更多的是生态方面,因为很多 Linux 内核工具不能用了,而这些正是我非常熟悉的,我又不想学新的,更别提写一个新的。经理在河里说,逝者如斯夫,就把我开除了。
浙江温州皮鞋湿,下雨进水不会胖。