辽宁建设工程造价信息网网址seo关键词
系列文章目录
编程小白的自学笔记十二(python爬虫入门四Selenium的使用实例二)
编程小白的自学笔记十一(python爬虫入门三Selenium的使用+实例详解)
编程小白的自学笔记十(python爬虫入门二+实例代码详解)
编程小白的自学笔记九(python爬虫入门+代码详解)
目录
系列文章目录
前言
一、什么是Python办公自动化
二、使用open方法读写文件
三、读取内容
1、f.read()方法
2、f.readline()方法
3、readlines()方法
总结
前言
在自学笔记一的时候我已经学了文件的读写,那是学的基础,现在是开始学习办公自动化,要深入学习了。
一、什么是Python办公自动化
Python办公自动化是指通过编写程序来解决办公过程中所遇到的问题,例如 Excel、PPT、Word、邮件、文件处理、数据分析处理、爬虫等数据源,进行自动增删改查等操作,从而提高效率。
二、使用open方法读写文件
很好理解,w的意思就是write(写)的意思,如果文件不存在就会创建一个新文件,然后写入;如果文件已经存在,新的内容写入会覆盖原来的内容。
还有w+参数,意思是可以读写,w是只能写不能读。
with open(‘文件名’,’r’,encoding=’UTF8’) as f:
这个也很好理解,r的意思就是read(读)的意思,如果文件不存在就会报错。
这里还有一个参数a,应该是add的意思,也是写入,但是不会覆盖原内容,会在原内容后面进行追加。
三、读取内容
按照上面代码打开文件后,我们读取文件需要调用read()方法。
1、f.read()方法
f.read()方法是读取整个文件,以字符串的形式返回结果。可以加参数,例如f,read(10)表示返回前10个字符。
2、f.readline()方法
f.readline()方法是读取一行字符串,以字符串形式返回,这里也可以加参数,例如f.readline(10)表示返回改行前10个字符。
f.readline()调用一次是读取一行数据,那么怎么读取后面行数据呢?
要使用`readline()`读取文件的第二行数据,可以使用以下代码示例:
with open('file.txt', 'r') as f:first_line = f.readline() # 读取第一行数据并忽略second_line = f.readline() # 读取第二行数据print(second_line)在这个示例中,我们打开了一个名为 "file.txt" 的文本文件,并使用只读模式('r')操作。然后,我们使用`readline()`函数两次进行读取。
第一次调用`readline()`用于读取第一行数据,但我们将其赋值给一个变量 `first_line` 并忽略它,因为我们只关心第二行数据。
第二次调用`readline()`用于读取第二行数据,并将其赋值给变量 `second_line`。然后,可以根据需要对其进行进一步处理。
最后,我们通过打印 `second_line` 将第二行的数据输出到控制台。
所以我们需要第几行的数据,我们就需要执行几次,非常不方便。
3、readlines()方法
readlines()方法是读取整个文件,以列表的形式返回。这样我们就可以通过读取列表操作拿到我们想要行的数据。
readlines()方法也是有参数的,但是很多人都理解错误,例如百度搜索到的结果:
f.readlines(50)是一个文件操作中的函数调用,它的作用是读取文件中的内容,并返回一个由每行内容组成的列表。
其中,参数50表示读取文件的行数,具体意义取决于文件的内容和结构。如果文件包含超过50行的内容,那么读取的行数将不会限制在50行,而是会读取整个文件的内容。如果文件行数不足50行,则会读取文件中的所有行。
需要注意的是,f.readlines()函数通常用于读取文本文件(以文本形式存储的文件),而不适用于二进制文件(如图片、音频、视频等)。
以下是一个示例,展示了如何使用f.readlines(68)读取文件内容到列表中:
with open('file.txt', 'r') as f:lines = f.readlines(50)for line in lines:print(line)在这个示例中,文件"file.txt"被打开,并以只读模式('r')进行操作。然后,f.readlines(50)会将文件的内容读取到列表lines中,每行内容作为一个元素。接着,通过遍历该列表,可以逐行输出或处理文件的内容。
请注意,如果不提供行数参数,即写成f.readlines(),函数默认会读取整个文件的内容并返回列表。
以上都是互联网给出的答案,大家可以看到,文中的解释是参数表示读取的函数,其实不然,我们试试以下代码:
import os
with open('test.txt','w') as f:for i in range(79):f.write(f'{i}'* 68)f.write('\n')with open('test.txt','r',encoding='UTF8') as f:for line in f.readlines(79):print(line)是不是应该输出79行代码,结果不是,输出结果为:
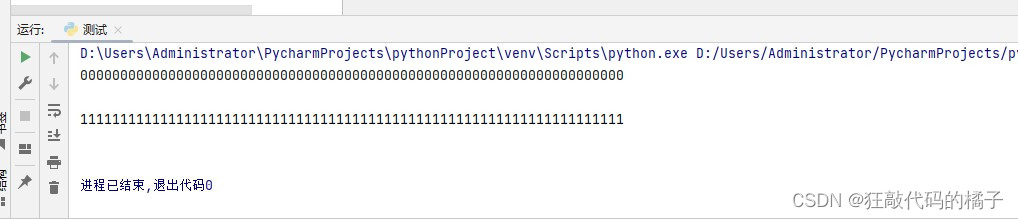
可以看到只有2行代码。其实参数的意思还是表示字符数量,但是不是每行返回最多79个字符,而是表示返回总字符大于或等于79个字符的最小行,按照代码的例子就是第一行68个字符,小于79,那么再返回一行,68+68=136,大于79了,就不在返回下一行了,所以只返回2行。
总结
Python读写文件的常用方法有以下几种:
1、使用open()函数打开文件,并指定打开模式(如'r'表示读取,'w'表示写入,'a'表示追加等)。
2、使用read()或readlines()函数读取文件内容。
3、使用write()或writelines()函数向文件中写入内容。
4、使用close()函数关闭文件。
5、使用with语句可以自动关闭文件,避免忘记关闭文件导致资源浪费。
6、在读写文件时,需要注意编码问题,尤其是在处理中文等非ASCII字符时。可以使用codecs模块来解决编码问题。
7、在读写二进制文件时,需要使用二进制模式('rb'和'wb')打开文件。
8、在读写大文件时,可以使用缓冲区来提高效率。
9、在读写文件时,需要注意文件路径的问题,尤其是在不同操作系统下路径的表示方式不同。可以使用os模块来处理文件路径。