公司网站建设接单精准引流推广
题目
链接
爬虫往往不能在一个页面里面获取全部想要的数据,需要访问大量的网页才能够完成任务。
这里有一个网站,还是求所有数字的和,只是这次分了1000页。
思路
- 找到调用接口
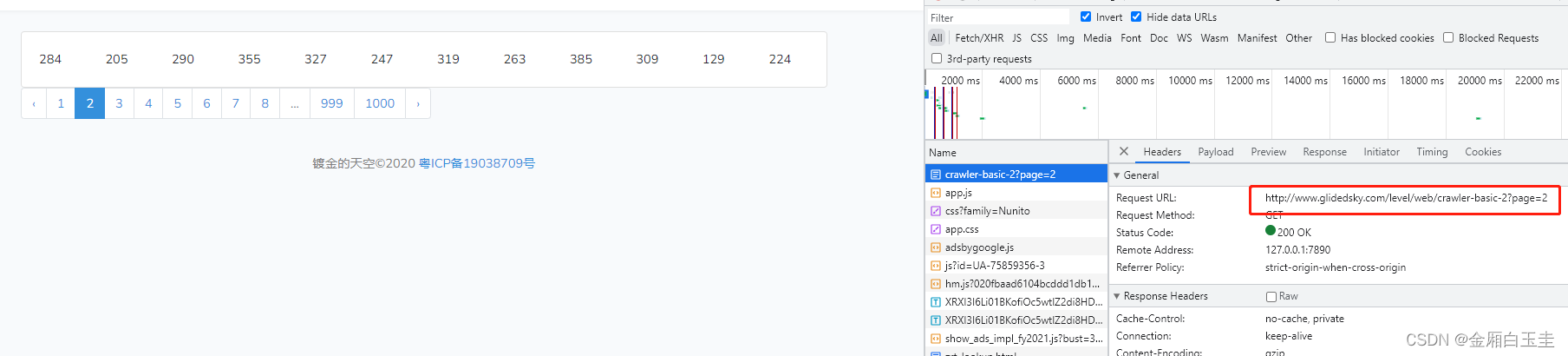
可以看到后面有个参数page来控制页码
代码实现
import requests
import reurl = 'http://www.glidedsky.com/level/web/crawler-basic-2'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.54','Cookie': ''
}res = 0
for i in range(1, 1001):temp_url = url + '?page=' + str(i)response = requests.get(temp_url, headers=headers)html = response.textpattern = re.compile('<div class="col-md-1">.*?(\d+).*?</div>', re.S)n_list = re.findall(pattern, html)for n in n_list:res += int(n)print(f'Result: {res}')
使用多线程实现更快爬取:
import requests
import re
import threadingurl = 'http://www.glidedsky.com/level/web/crawler-basic-2'
total_threads = 10 # 设置线程数量
lock = threading.Lock() # 创建一个锁,用于线程间的数据同步
res = 0def worker(thread_id):global resfor i in range(thread_id, 1001, total_threads):temp_url = url + '?page=' + str(i)response = requests.get(temp_url, headers=headers)html = response.textpattern = re.compile('<div class="col-md-1">.*?(\d+).*?</div>', re.S)n_list = re.findall(pattern, html)with lock:for n in n_list:res += int(n)threads = []
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.54','Cookie': ''
}# 创建并启动线程
for i in range(total_threads):thread = threading.Thread(target=worker, args=(i,))thread.start()threads.append(thread)# 等待所有线程执行完成
for thread in threads:thread.join()print(f'Result: {res}')
使用异步函数
import aiohttp
import asyncio
import reurl = 'http://www.glidedsky.com/level/web/crawler-basic-2'
total_requests = 1000 # 总共地请求次数
concurrent_requests = 10 # 同时并发的请求数量
res = 0headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.54','Cookie': ''
}async def fetch_url(session, temp_url):async with session.get(temp_url, headers=headers) as response:html = await response.text()pattern = re.compile('<div class="col-md-1">.*?(\d+).*?</div>', re.S)n_list = re.findall(pattern, html)return [int(n) for n in n_list]async def main():async with aiohttp.ClientSession() as session:tasks = []for i in range(1, total_requests + 1):temp_url = url + '?page=' + str(i)tasks.append(fetch_url(session, temp_url))if len(tasks) >= concurrent_requests or i == total_requests:results = await asyncio.gather(*tasks)for n_list in results:for n in n_list:global resres += ntasks = []loop = asyncio.get_event_loop()
loop.run_until_complete(main())print(f'Result: {res}')
时间统计:同步的方式大概80s,多线程和异步时间差不多都是20s左右