黑龙江网站开发公司百度seo关键词优化
目录
使用Flink处理Kafka中的数据
前提:
一, 使用Flink消费Kafka中ProduceRecord主题的数据
具体代码为(scala)
执行结果
二, 使用Flink消费Kafka中ChangeRecord主题的数据
具体代码(scala)
具体执行代码①
重要逻辑代码②
执行结果为:
使用Flink处理Kafka中的数据
前提:
创建主题 : ChangeRecord , ProduceRecord
使用kafka-topics.sh --zookeeper bigdata1:2181/kafka --list 查看主题
kafka-topics.sh --zookeeper bigdata1:2181/kafka --list

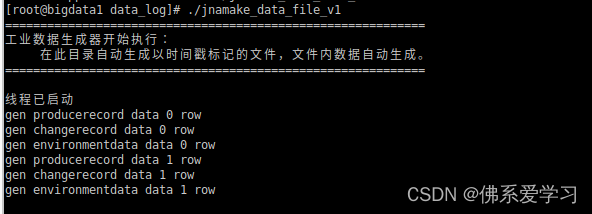
然后开启数据生成器
./jnamake_data_file_v1
一, 使用Flink消费Kafka中ProduceRecord主题的数据
启动Flume a1, a1为所赋予的名称
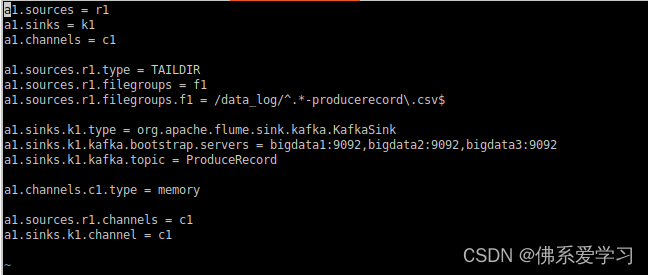
flume-ng agent --conf-file /opt/module/flume-1.9.0/job/flume-to-kafka-producerecord--name a1 -Dflume.root.logger=DEBUG,console
启动一个Kafka的消费者(consumer)来消费(读取)Kafka中的消息
kafka-console-consumer.sh --bootstrap-server bigdata1:9092 --from-beginning --topic ProduceRecord
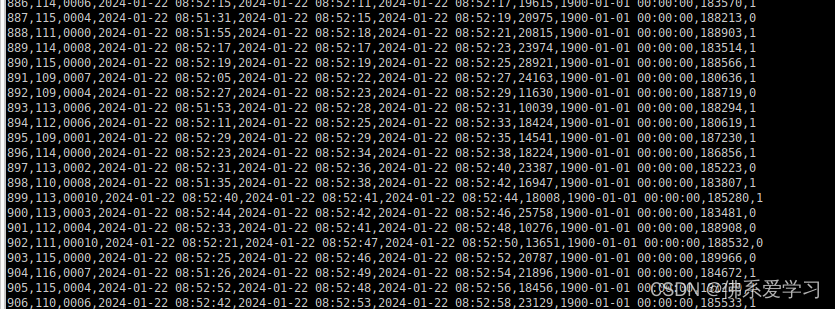
编写Scala工程代码,使用Flink消费Kafka中的数据并进行相应的数据统计计算。
一, 使用Flink消费Kafka中ProduceRecord主题的数据,统计在已经检验的产品中,各设备每五分钟生产产品总数,将结果存入Redis中,key值为“totalproduce”,value值为“设备id,最近五分钟生产总数”。使用redis cli以HGETALL key方式获取totalproduce值,将结果截图粘贴至对应报告中,需两次截图,第一次截图和第二次截图间隔五分钟以上,第一次截图放前面,第二次放后面;
注:ProduceRecord主题,生产一个产品产生一条数据;
change_handle_state字段为1代表已经检验,0代表未检验;
时间语义使用Processing Time。
具体代码为(scala):
package gyflink
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.{FlinkJedisClusterConfig, FlinkJedisPoolConfig}
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}import java.util.Properties
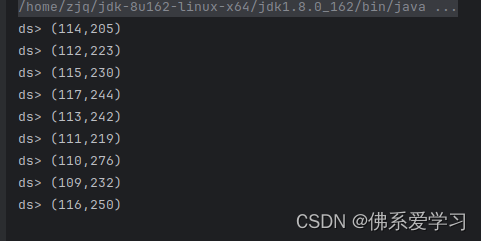
object test1{def main(args: Array[String]): Unit = {// 创建Flink流执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment// 设置并行度env.setParallelism(1)//指定时间语义env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)// kafka的属性配置val properties = new Properties()properties.setProperty("bootstrap.servers","bigdata1:9092,bigdata2:9092,bigdata3:9092")properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer")properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringSerializer")properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringSerializer")properties.setProperty("auto.offset.reset","earliest")// 读取kafka数据val FlinkKafkaConsumer = new FlinkKafkaConsumer[String]("ProduceRecord", new SimpleStringSchema(), properties)val text = env.addSource(FlinkKafkaConsumer)// TODO 使用flink算子对数据进行处理// topic的一条数据:2214,117,0002,2024-01-09 11:08:53,2024-01-09 11:08:53,2024-01-09 11:08:59,15897,1900-01-01 00:00:00,188815,0val inputMap = text.map(link => {val arr = link.split(",") // 使用‘,’作为分割符(arr(1).toInt, arr(9).toInt) // 下标取出第1个和第9个值}).filter(_._2 == 1) // 筛选条件:把第二个元素等于1.keyBy(_._1) // 将第一个元素作为key值.timeWindow(Time.minutes(5)) // 间隔5分钟进行计算.sum(1)inputMap.print("ds")// TODO 与 Redis 数据库进行连接// 创建Redis数据库的连接属性val config: FlinkJedisPoolConfig = new FlinkJedisPoolConfig.Builder() // 创建一个FlinkJedisPoolConfig对象.setHost("bigdata1") // 设置Redis数据库的主机地址.setPort(6379) // 设置Redis数据库的端口号.build()// 创建RedisSink对象,并将数据写入Redis中val redisSink = new RedisSink[(Int, Int)](config, new MyRedisMapper) // MyRedisMapper是一个自定义的映射器,将flink的数据转换为Redis的格式// 发送数据inputMap.addSink(redisSink) // 将flink的数据流和Redis数据库连接起来// 执行Flink程序env.execute("kafkaToRedis") // 向flink提交作业,开始执行}// 根据题目要求class MyRedisMapper extends RedisMapper[(Int, Int)] { // RedisMapper的方法是是将把flink的数据存储为Redis的存储格式//这里使用RedisCommand.HSET不用RedisCommand.SET,前者创建RedisHash表后者创建Redis普通的String对应表override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.HSET,"totalproduce")override def getKeyFromData(t: (Int, Int)): String = t._1 + ""override def getValueFromData(t: (Int, Int)): String = t._2 + ""}}执行结果:

二, 使用Flink消费Kafka中ChangeRecord主题的数据
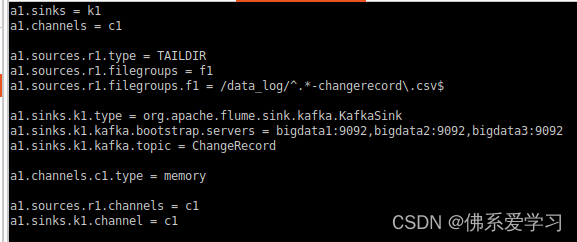
启动Flume a1, a1为所赋予的名称
flume-ng agent --conf-file /opt/module/flume-1.9.0/job/flume-to-kafka-changerecord --name a1 -Dflume.root.logger=DEBUG,console
启动一个Kafka的消费者(consumer)来消费(读取)Kafka中的消息
kafka-console-consumer.sh --bootstrap-server bigdata1:9092 --from-beginning --topic ChangeRecord
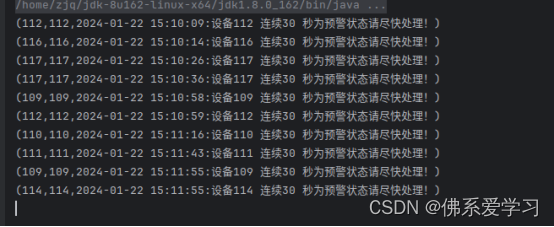
二, 使用Flink消费Kafka中ChangeRecord主题的数据,当某设备30秒状态连续为“预警”,输出预警信息。当前预警信息输出后,最近30秒不再重复预警(即如果连续1分钟状态都为“预警”只输出两次预警信息)。将结果存入Redis中,key值为“warning30sMachine”,value值为“设备id,预警信息”。使用redis cli以HGETALL key方式获取warning30sMachine值,将结果截图粘贴至对应报告中,需两次截图,第一次截图和第二次截图间隔一分钟以上,第一次截图放前面,第二次放后面;
注:时间使用change_start_time字段,忽略数据中的change_end_time不参与任何计算。忽略数据迟到问题。
Redis的value示例:115,2022-01-01 09:53:10:设备115 连续30秒为预警状态请尽快处理!
(2022-01-01 09:53:10 为change_start_time字段值,中文内容及格式必须为示例所示内容。)
具体代码(scala):
具体执行代码①:
package gyflinkimport org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.scala.createTypeInformation
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}import java.text.SimpleDateFormat// 定义一个Change类,这个类里面定义四个参数,这四个参数对应着分割后的元素
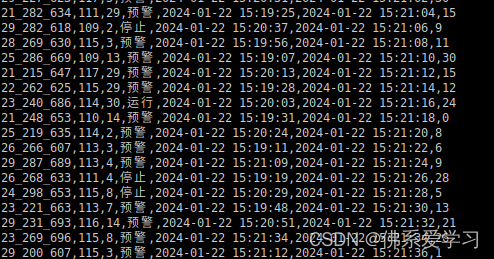
case class Change(ChangeId: Int, ChangeState:String, ChangeTime:String, timeStamp:Long)object flink_kafka_to_redis2 {def main(args: Array[String]): Unit = {/** 25_299_649,111,13,预警,2024-01-09 11:08:08,2024-01-09 11:08:52,15ChangeRecord的日志信息: 22_220_698,114,29,预警,2024-01-09 11:07:42,2024-01-09 11:09:00,15* */// TODO 创建flink的执行环境val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1) // 设置并行度为1,单节点运行// TODO 与kafka进行连接val kafkaSource = KafkaSource.builder().setBootstrapServers("bigdata1:9092") // 设置kafka服务器地址.setTopics("ChangeRecord") // flink需要订阅的主题.setValueOnlyDeserializer(new SimpleStringSchema()) // 设置只对value反序列化器,由于kafka使用网络进行传输,发送的是序列化数据,所以flink要做反序列化操作.setStartingOffsets(OffsetsInitializer.latest()) // 设置读取偏移量,从kafka最新的记录开始读取.build()// TODO 读取kafka数据,设置无水印val produceDataStream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka_flink_redis")// kafka属性 水印设置 名称val kafka_value = produceDataStream.map(x => {val data = x.split(",") // 每一条记录以‘,’进行分割val timestamp = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(data(4)).getTime // 将string类型的时间转换为timestamp类型,形成时间戳Change(data(1).toInt, data(3), data(4),timestamp) // 输出:Change(110,预警,2024-01-18 14:09:36,1705558176000)})// 设置水位线val waterTimeStream = kafka_value.assignTimestampsAndWatermarks( // 创建一个新的watermark策略,并应用与kafka数据流// 流过来的数据时间是递增的,将迟到的数据直接丢弃WatermarkStrategy.forMonotonousTimestamps() // 用于处理单调递增的时间戳(升序的时间戳).withTimestampAssigner(new SerializableTimestampAssigner[Change] { // 定义了一个时间戳分配器,从每个事件中提取时间戳override def extractTimestamp(change: Change, recordTimestamp: Long): Long = { // 定义了两个参数,第一个参数表示Change类型,第二个是个Long类型,这个函数返回值为Long的change.timeStamp // 从 change(Change) 提取timeStamp的参数}}))// 开始处理数据流val resultSteam = waterTimeStream.keyBy(_.ChangeId) // 按照ChangeId进行分组.process(new flink_kafka_to_redis2_Process) // 调用处理类// 与Redis建立连接val JedisPoolConfig = new FlinkJedisPoolConfig.Builder().setHost("bigdata1").setPort(6379)// .setDatabase(0).build()val Warning30Machine = new RedisMapper[(Int, String)] {override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.HSET, "warning30sMachine")override def getKeyFromData(t: (Int, String)): String = t._1.toStringoverride def getValueFromData(t: (Int, String)): String = t._2}// 建立Redis通道val redisSink = new RedisSink[(Int, String)](JedisPoolConfig, Warning30Machine)// 将结果流加入到通道resultSteam.addSink(redisSink)resultSteam.print()env.execute()}}重要逻辑代码②:
package gyflink
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.util.Collectorclass flink_kafka_to_redis2_Process extends KeyedProcessFunction[Int,Change, (Int, String)] {// 键类型 输入类型 输出类型// 用于保存上一条的记录的状态private lazy val lastState:ValueState[Change] = getRuntimeContext.getState( // 延迟初始化的私有变量new ValueStateDescriptor[Change]("lastState",classOf[Change]))override def processElement(Change: Change, ctx: KeyedProcessFunction[Int, Change, (Int, String)]#Context, out: Collector[(Int, String)]): Unit = {// 获取定时服务val timerService = ctx.timerService()// 如果是预警信息if (Change.ChangeState.equals("预警")){if (lastState.value() == null){lastState.update(Change)timerService.registerEventTimeTimer(Change.timeStamp + 30000)}} else {// 出现不是预警信息,删除存在的定时器,如果不存在定时器会忽略if (lastState.value() != null){timerService.deleteEventTimeTimer(lastState.value().timeStamp + 30000)lastState.update(null)}}}// 定时器逻辑override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Int, Change, (Int, String)]#OnTimerContext, out: Collector[(Int, String)]): Unit = {val record = lastState.value()// out.collect((record.ChangeId,s"${record.ChangeTime}:设备${record.ChangeId}连续30秒为预警状态请尽快处理!"))out.collect(record.ChangeId,s"${record.ChangeId},${record.ChangeTime}:设备${record.ChangeId} 连续30 秒为预警状态请尽快处理!")lastState.update(null)}}执行结果为: