委托做网站违反广告法短网址在线生成
一、连接查询
①:左连接left join (小表在左,大表在右)
②:右连接right join(小表在右,大表在左)
二、聚合函数
SQL 中提供的聚合函数可以用来统计、求和、求最值等等
COUNT:统计行数量
SUM:获取单个列的合计值
AVG:计算某个列的平均值
MAX:计算列的最大值
MIN:计算列的最小值
三、SQL 关键字
①分页:limit
SELECT * FROM student3 LIMIT 100,6; 查询学生表中数据,跳过100条,从第101条开始显示,取6 条
②倒序:order by ... desc
select * from user order by id desc limit 0 6
③分组:group by
SELECT sex , count(*) FROM student GROUP BY sex
④去重:distinct
select DISTINCT NAME FROM student3;
四、 SQL Select 语句完整的执行顺序
查询中用到的关键词主要包含如下展示,并且他们的顺序依次为
form...left join...on...where...group by...having..select...avg()/sum()...order by...asc/desc...limit...
from: 需要从哪个数据表检索数据
where: 过滤表中数据的条件
group by: 如何将上面过滤出的数据分组算结果
order by : 按照什么样的顺序来查看返回的数据
五、 数据库三范式(掌握)
第一范式:
1NF 原子性,列或者字段不能再分,要求属性具有原子性,不可再分解;
第二范式:
2NF主要是解决行的冗余。
1.每一行数据有唯一的主键
2. 非主键字段必须依赖于主键字段
第三范式:
3NF主要是解决 列 的冗余。
非主键字段不依赖于其它非主键字段
我们有时候并不会严格的遵守第三范式,例如我们在设计订单明细表的时候,我们冗余了商品的名称和图片,因为我们通过商品id再去查询商品表会给基础表造成压力,所以我们冗余了两个字段。
六、存储引擎 :MyISAM 存储引擎 与 InnoDB 引擎区别
①. 事务支持:MyLISAM不支持事务,InnoDB支持事务。
②. 锁定机制(锁的粒度):MyISAM 表级锁 ; InnoDB 支持行级锁。
③. 外键支持:MyISAM 不支持外键约束;而 InnoDB 支持外键约束。(一般不用外键,我们在使用外键过程中,删除的时候需要)
④. 并发性能: InnoDB 支持行级锁定和事务处理,InnoDB 的并发性能更高。
七、数据库事务(必会)
1.事务特性ACID
原子性:即不可分割性,事务要么全部被执行,要么就全部不被执行。
一致性:事务必须使数据库从一个一致性状态变换到另一个一致性状态,即一个事务执行之前和执行之后都必须处于一致性状态。拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还是5000,这就是事务的一致性。
隔离性:即一个事务执行之前和执行之后都必须处于一致性状态。
持久性:事务一旦结束,数据就持久到数据库
如何保持事务特性:
-
redo log, 持久性,当数据库对数据做修改的时候,需要把数据页从磁盘读到buffer pool中,然后在buffer pool中进行修改,那么这个时候buffer pool中的数据页就与磁盘上的数据页内容不一致,称buffer pool的数据页为dirty page脏数据,如果这个时候发生非正常的DB服务重启,那么这些数据还在内存,并没有同步到磁盘文件中,也就是会发生数据丢失,如果这个时候,能够在有一个文件,当buffer pool中的data page变更结束后,把相应修改记录记录到这个文件(注意,记录日志是顺序IO),那么当DB服务发生crash的情况,恢复DB的时候,也可以根据这个文件的记录内容,重新写到到磁盘文件,这样数据就保持一致。
-
undo log,一致性,原子性。 undo日志用于存放数据被修改前的值,如果修改出现异常,可以使用undo日志来实现回滚操作,保证事务的一致性。另外InnoDB MVCC事务特性也是基于undo日志实现的。undo日志分为insert undo log(insert语句产生的日志,事务提交后直接删除)和update undo log(delete和update语句产生的日志,由于该undo log可能提供MVVC机制使用,所以不能再事务提交时删除)
2.隔离级别
读未提交:脏读
脏读:所谓的脏读,其实就是读到了别的事务回滚前的脏数据。当前事务读到的数据是别的事务想要修改但是没有修改成功的数据。
A读了B回滚前的数据。
读已提交:不可重复读,针对update和delete
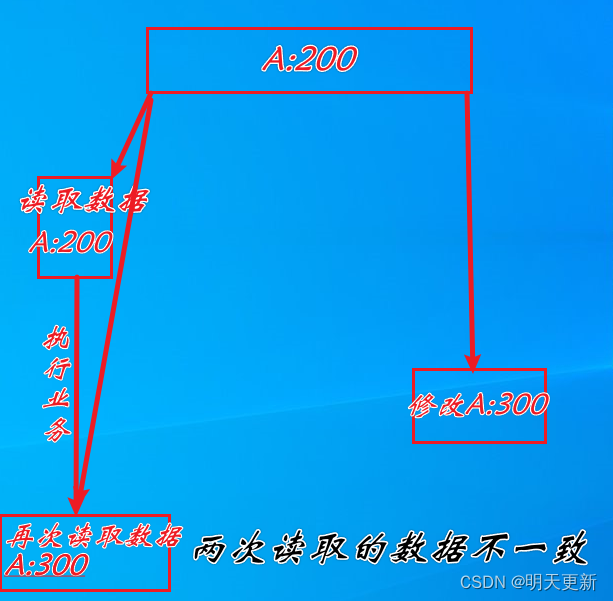
可重复读:幻读,针对insert

解决方法:采用多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。·
串行化:一个一个来,有效解决脏读,不可重复读,幻读,就是效率很低。
八、索引的优点和缺点(空间换时间)
优点:加快查询效率
缺点:占用内存空间,增删改的效率较低(删除数据的时候还需要删索引的相关数据,故效率低)
九、索引的分类
①:普通索引:值可以重复
②:唯一索引:唯一,允许有一个空值
③:主键索引:不为空,只能有一个
④:联合索引:(手机号和密码),(订单id和status)
⑤:全文索引:虽然MySQL支持全文索引但我们并没有采用,我们采用ES做搜索引擎。
十、B树与B+树的主要区别
存储数据的位置:
B树: 数据既存储在所有节点中(叶子节点和非叶子节点都有数据)
B+树: 所有的数据记录都存储在叶子节点中,非叶子节点仅包含索引信息。叶子节点包含了完整的数据和索引键。
叶子节点之间的链接:
B树: 叶子节点之间没有链接。
B+树: 叶子节点之间通过指针相互链接,形成一个链表或循环链表,这使得范围查询和遍历变得高效。
十一、MySql Explain优化命令使用
truncate table student // 自增id 从 0 开始
delete from student // 自增id 会保留 , 108
区别:
1:自增id
2:delete 可以恢复
truncate 无法恢复
通过MySQL的慢日志和skyworking进行记录所有较慢的sql语句,我们的运维通过xxl-job每天早上八点定时发送邮件,我们查看邮件看是否有自己所在组的慢日志的语句。在通过explain命令对我们的sql语句进行分析,通过查看type字段看我们的sql处于什么阶段,然后进行优化。
1、type 列(重点)
"type"列用于表示访问表时所采用的访问类型。
下面是常见的"type"值及其含义:
-
system: 表示只有一行的表,通常是系统表。 -
const: 表示通过索引只能匹配到一行数据。 explain select * from student where id = 1688
-
eq_ref: 表示使用了等值连接(例如,使用主键或唯一索引连接表)。explain SELECT * FROM student s1 JOIN student s2 ON s1.id = s2.id WHERE s1.age = 25;
-
ref: 表示使用了非唯一索引进行查找,并返回匹配的多行或一行数据。 explain select * from student where name = '张68'
-
range: 表示使用了索引进行范围查找,例如使用比较符(>, <, BETWEEN)或IN操作符。 explain select * from student where age < 1688
-
index: 表示全索引扫描,也就是说用了某一个索引的全部, 通常发生在查询使用索引覆盖的情况下。explain select count(*) from student ;explain select sum(age) from student
-
all: 表示全表扫描,即没有使用索引,需要遍历整个表进行查询。 explain select * from student
2、如何避免索引失效
①:避免使用范围条件查询(如果查询的结果数大于总数的三分之一,索引就会失效)
②:避免使用函数运算会造成索引失效(使用函数运算,在没计算出来结果之前无法确定结果)
③:字符串不加引号会造成索引失效(不加引号比较的是ASI码,加引号比较的是字符串常量)
④:尽量使用索引覆盖
索引覆盖:通过索引就能找到你想要的信息,就可以避免再次查询
回表:通过索引不能够完全查询到你要找到的信息,需要回表再查询一次
⑤:or关键字连接(or前后的列都需要有索引才会走索引,只要有一个没有使用索引,索引就是失效)
⑥:使用!=(底层就是使用函数运算,索引就会失效)
⑦:like '%张' (最左匹配原则,先%就是全表查询,先‘张’就是根据索引查询)
十二、数据库锁
1、行锁和表锁
①:粒度划分:行锁,表锁,库锁
②:行锁和表锁的区别:
表锁:开销小,加锁快,不会出现死锁,锁的粒度大,锁冲突的概率大,并发低
行锁:开销大,加锁慢,会出现死锁,粒度小,锁冲突的概率小,高并发
2、优化索引
2.1、索引设计原则:
-
对查询频次较高, 且数据量比较大的表, 建立索引.
- 索引字段的选择, 最佳候选列应当从 where 子句的条件中提取, 如果 where 子句中的组合比较多, 那么应当挑选最常用, 过滤效果最好的列的组合
-
使用唯一索引, 区分度越高, 使用索引的效率越高,能建唯一索引就建唯一索引,或者普通索引
-
索引并非越多越好, 如果该表赠,删,改操作较多, 慎重选择建立索引, 过多索引会降低表维护效率. 不是越多越好
-
使用短索引, 提高索引访问时的 I/O 效率, 因此也相应提升了 Mysql 查询效率.
-
如果 where 后有多个条件经常被用到, 建议建立复合索引, 复合索引需要遵循最左前缀法则, N 个列组合而成的复合索引, 相当于创建了 N 个索引.
3、聚簇索引和非聚簇索引
索引存储的都是key - value形式,主键索引存储的索引(key)物理表的地址(value)
非聚簇索引,key存储的是索引,value存储的是主键索引,需要再回表。
聚簇索引:我们以往使用的索引中只有主键索引是聚簇索引。主键索引是跟物理表直接连接。
非聚簇索引:除了主键索引外的都是非聚簇索引,依赖于主键索引,根据主键索引连接物理表,再进行回表。
十三、索引下推
在传统的查询语句中,当我们的查询条件有多个时,通常会将拥有的数据查出来后再进行回表操作,拿到符合的条件再比对剩下的查询条件,这会浪费大量资源,但在开启索引下推后,我们可以直接在第一次查询索引时附带上其余条件,从而减少回表的次数,增加查询效率,但索引吓退时只能附带一些简单查询规则,后续可能会慢慢优化。mysql6.5之后才有索引下推。