高校建设主流的校园网站网页设计成品源代码
前言:
有关Clickhouse的前置知识详见:
1.ClickHouse的安装启动_clickhouse后台启动_THE WHY的博客-CSDN博客
2.ClickHouse目录结构_clickhouse 目录结构-CSDN博客
Cickhouse创建表时必须指定表引擎
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
数据一般存储在本地,默认路径是
/var/lib/clickhouse/
除此之外也可以集成一些外部的数据库,如Hive,MySQL等
- 支持哪些查询以及如何支持
数组在mergetree引擎中无法使用
- 并发数据访问
- 索引的使用(如果存在)
- 是否可以执行多线程请求
- 数据复制参数
TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,生产环境上作用有限。可以用于平时练习测试用
Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过 10G/s)。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概 1 亿行)的场景
MergeTree*(合并树)
MergeTree支持索引和分区
建表语句如下:
create table t_order_mt(id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime)engine = MergeTree partition by toYYYYMMDD(create_time) primary key(id) order by (id,sku_id);需要注意的是,clickhouse中主键会自动创建索引,但并不唯一;
而且order by设置的排序是在分区内排序
插入数据
insert into t_order_mt values \
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,\
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),\
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',600.00,'2020-06-02 12:00:00');进行查询:

可以看到通过命令行查询出的数据可以明显观察到分区
语法知识
MergeTree | ClickHouse Docs
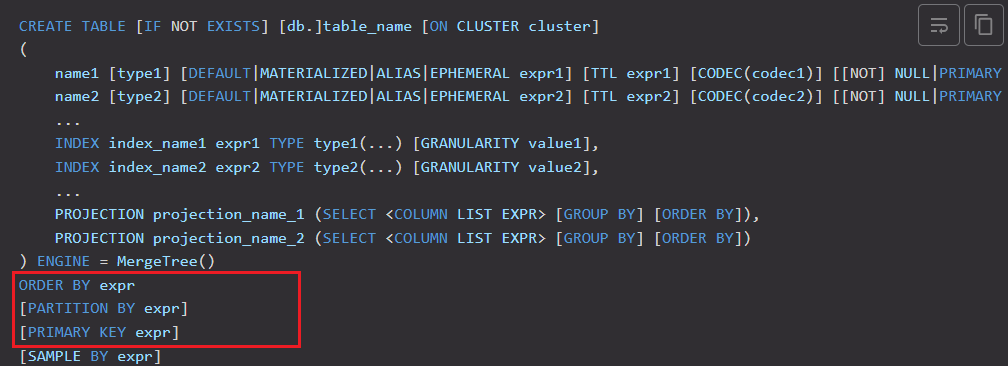
可以看到,primary key 和 partition by字段都不是必须的,但order by字段是必须的
分区合并
分区的目的主要是降低扫描的范围,优化查询速度
在hive中,分区是通过HDFS中分目录实现的;clickhouse中也是通过分目录实现的,只不过是在本地磁盘
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中
具体操作
向表中插入数据:
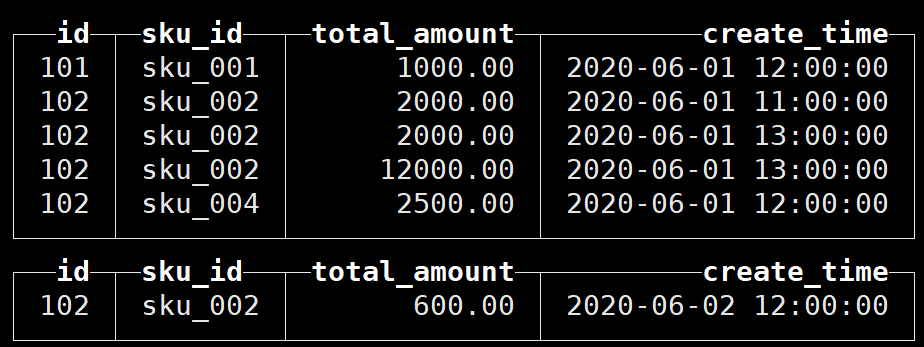
在本地按分区存储数据:

再次插入数据:
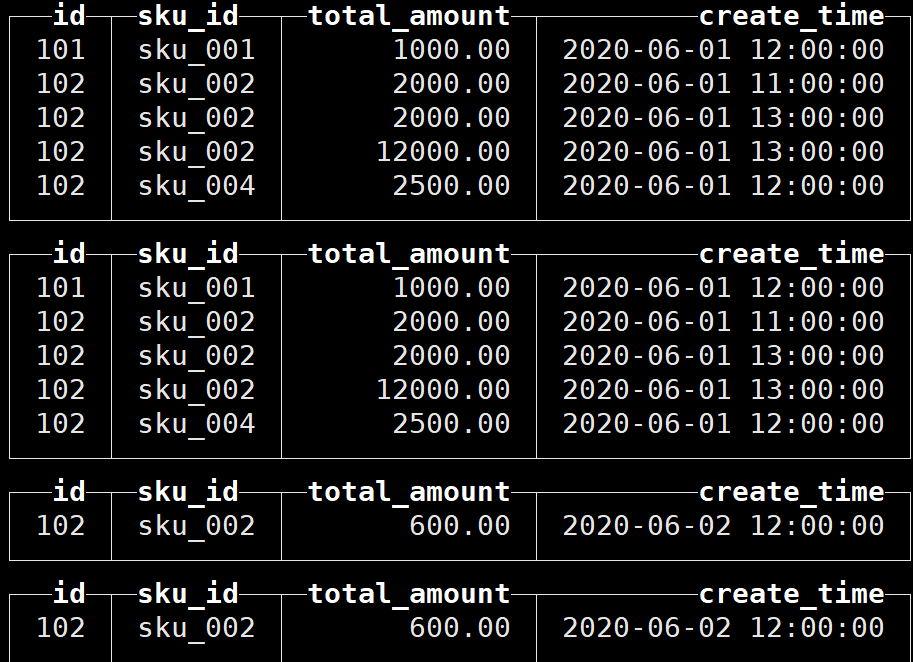
可以看到数据并没有纳入任何分区,这是因为任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区;写入后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作
也可以手动通过 optimize 执行,把临时分区的数据,合并到已有分区中:
optimize table xxxx final
详细语法见:OPTIMIZE Statement | ClickHouse Docs
查看数据文件可以看到合并后的分区数据:
可以看到最小分区块编号、最大分区块编号和合并层级都发生了变化
需要注意:手动执行分区合并后会生成新的数据文件,但过期数据不会立即删除
等到自动合并操作执行后,过期数据就会被删除了;因此过一段时间再去查看:

除此之外,optimize还可以指定要合并的分区:
optimize table xxxx PARTITION partition final;
示例:
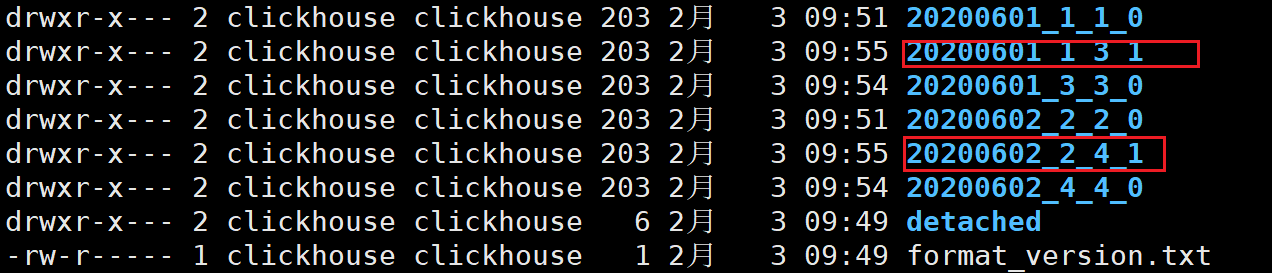
插入一些数据,目前的分区如下:
接下来只合并分区id为20200601的数据:
optimize table t_order_mt partition '20200601' final;
合并结果如下:
primary key
MergeTree | ClickHouse Docs
- 只提供了数据的一级索引,但是却不是唯一约束
- 主键的设定主要依据是查询语句中的 where 条件,根据条件通过对主键进行某种形式的二分查找,能够定位到对应的
index granularity避免了全表扫描
index granularity:索引粒度;也就是在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse 中的 MergeTree 默认是 8192;官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据
稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描
order by
- order by进行分区内排序,是必须设置的(因为clickhouse使用稀疏索引,如果数据无序,无法根据索引来进行定位)
- 主键必须是 order by 字段的前缀字段
比如 order by 字段是 (id,sku_id) 那么主键必须是 id 或者(id,sku_id)
假如主键是sku_id,那么可以发现数据在主键维度上是无序的,索引依然无法定位
二级索引
clickhouse从v20.1.2.4 开始全面支持二级索引
创建二级索引的语法:
INDEX a total_amount TYPE minmax GRANULARITY 5索引名 对应的列 二级索引的类型 粒度
注意:这里的粒度指的是二级索引相对于一级索引的粒度
测试
建表
create table t_order_mt2( \id UInt32,\sku_id String,\total_amount Decimal(16,2),\create_time Datetime,\
INDEX a total_amount TYPE minmax GRANULARITY 5\
) engine =MergeTree\partition by toYYYYMMDD(create_time)\primary key (id)\order by (id, sku_id);插入数据:
insert into t_order_mt2 values \
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,\
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),\
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',600.00,'2020-06-02 12:00:00');测试二级索引是否发挥作用:
clickhouse-client --send_logs_level=trace <<< 'select * from t_order_mt2 where total_amount > toDecimal32(900., 2)';可以看到:

index a在查询过程中起到了粒度划分的作用;
TTL
MergeTree | ClickHouse Docs
TTL 即 Time To Live,MergeTree 提供了可以管理数据表或者列的生命周期的功能
对于表和列都可以指定TTL;
指定列的TTL(建表时)
TTL time_column + interval
建表测试:
create table t_order_mt3(\id UInt32,\sku_id String,\total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,\create_time Datetime \
) engine =MergeTree\
partition by toYYYYMMDD(create_time)\primary key (id)\order by (id, sku_id);对total_amount列设置了TTL
插入数据:
insert into t_order_mt3 values \
(106,'sku_001',1000.00,'2023-07-31 20:45:10'),\
(107,'sku_002',2000.00,'2023-07-31 20:45:10'),\
(110,'sku_003',600.00,'2023-07-31 20:45:10');插入完成后可以正常查询到数据:
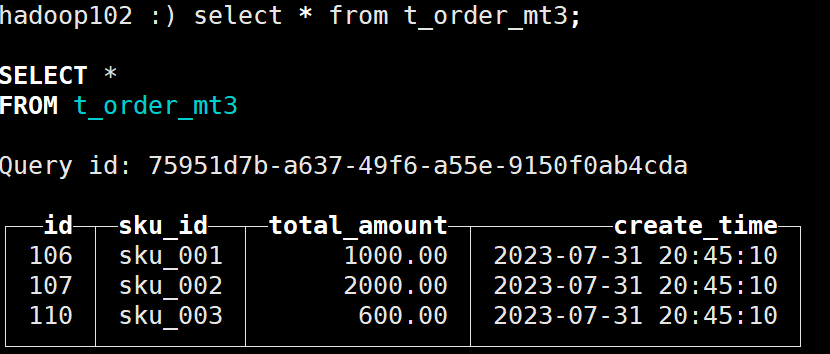
等待到20:45:20之后再次查询:
发现依然能查询到数据:
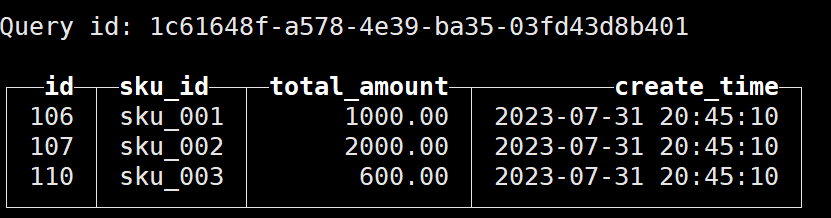
可能是因为尚未合并导致的,因此手动合并:
optimize table t_order_mt3 final
发现字段值已经清空:
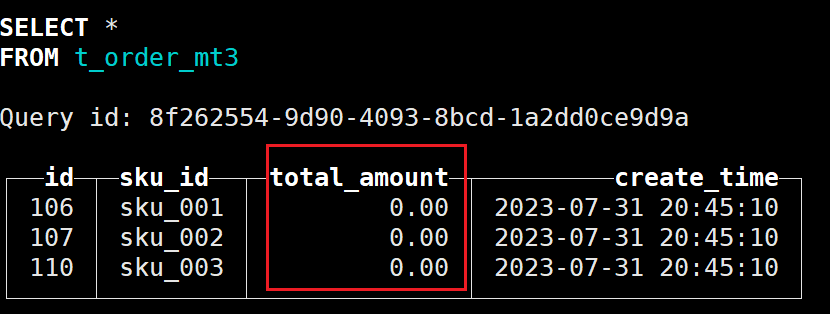
如果没有反应,可以尝试重启以下clickhouse的服务器,因为TTL操作是单独开启一个进程去完成的,如果机器资源较少,可能出现应答不及时的情况;
修改列的TTL
语法:
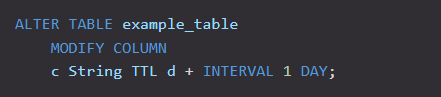
通过MODIFY COLUMN实现,简单来说就是重新定义一下这个列;
指定表的TTL
语法:

就是在ORDER BY后面设置TTL即可
官网给出了TTL到达后的三种策略
DELETE:删除对应数据
TO DISK 'aaa':将数据移动到磁盘'aaa'
TO VOLUME 'bbb':将数据移动到磁盘'bbb'
修改表的TTL
语法:

ReplacingMergeTree(去重)
ReplacingMergeTree 是 MergeTree 的一个变种,它存储特性完全继承 MergeTree,只是
多了一个去重的功能(根据order by字段进行去重,而不是主键)
去重时机:数据的去重只会在合并的过程中出现(合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理)
在新版本中插入数据时会先进行一次去重
去重范围:分区内去重,无法跨分区去重
测试
创建表,指定引擎为ReplacingMergeTree
create table t_order_rmt(\id UInt32,\sku_id String,\total_amount Decimal(16,2) ,\create_time Datetime \
) engine =ReplacingMergeTree(create_time)\partition by toYYYYMMDD(create_time)\primary key (id)\order by (id, sku_id);ReplacingMergeTree() 填入的参数为版本字段,重复数据保留版本字段值最大的
如果不填版本字段,默认按照插入顺序保留最后一条
插入数据:
insert into t_order_rmt values\
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,\
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),\
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),\
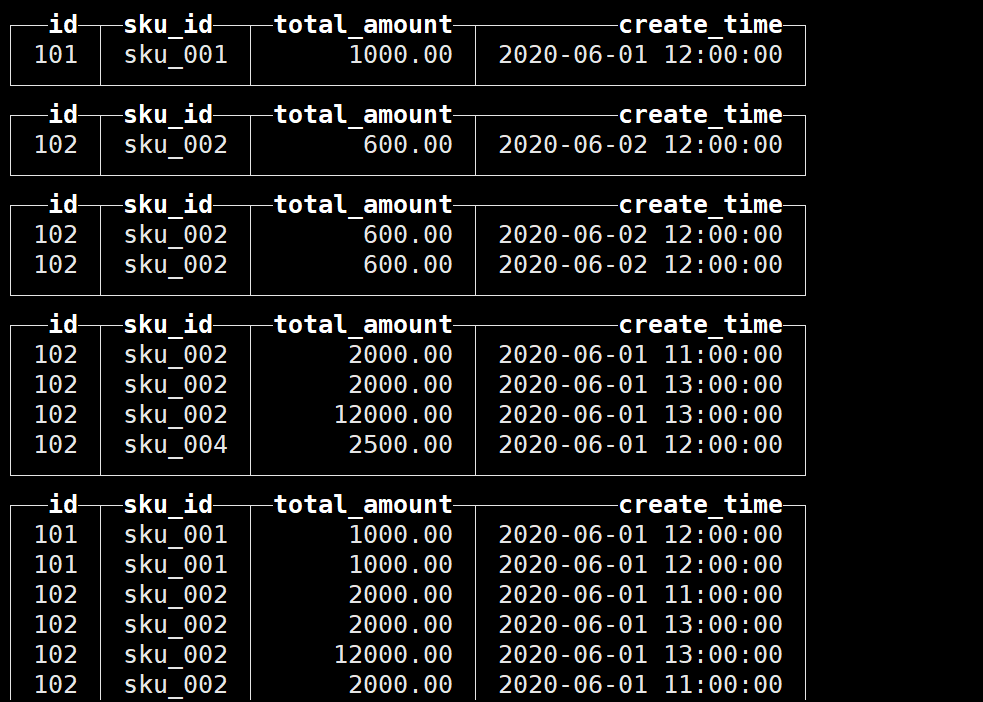
(102,'sku_002',600.00,'2020-06-02 12:00:00');查询结果如下:
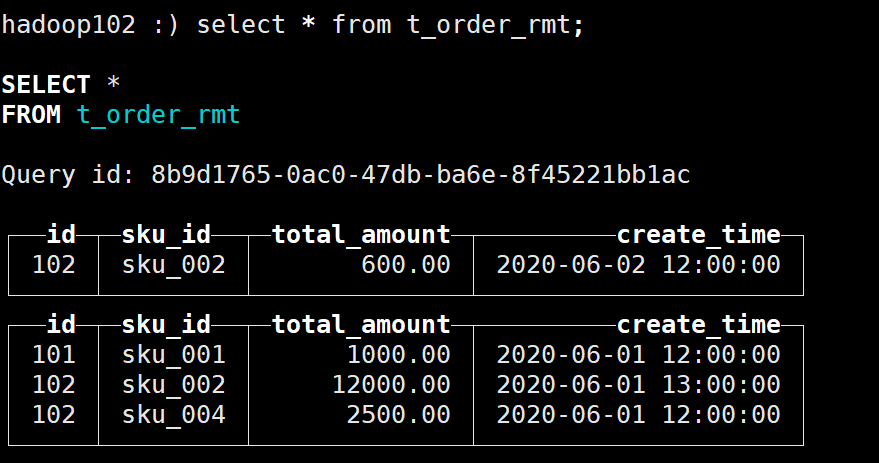
与下图对比可知在插入数据时已经进行了去重
注意到有两条数据的版本字段相同:

最终保留的数据是:
![]()
因此可以看到,但版本字段相同时,按照插入顺序保留最后一条
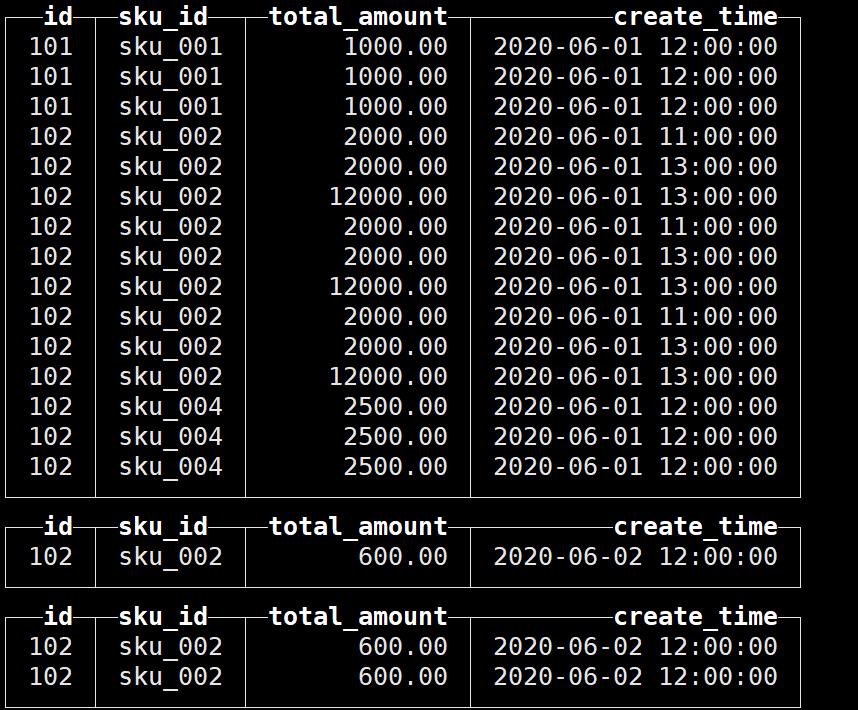
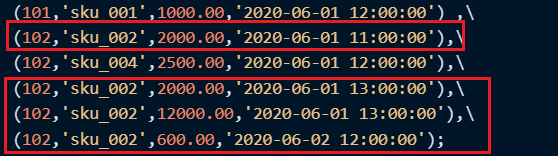
接下来再次插入数据,查询结果如下:
可以看到同一分区内的数据并未进行去重
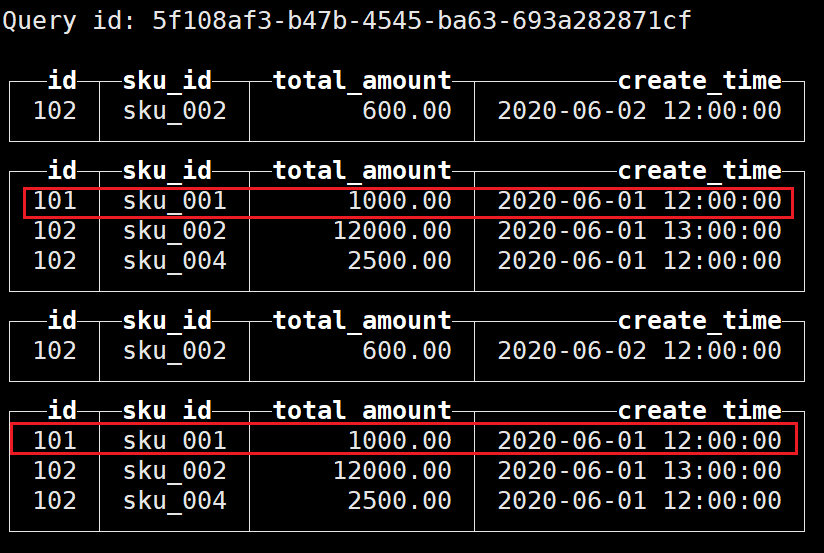
因此手动执行合并后再查询:

可以看到已经进行了去重;
SummingMergeTree(聚合)
适用于不查询明细,只关心以维度进行汇总聚合结果的场景,可以避免因临时聚合而带来的开销
测试
创建表,指定引擎为SummingMergeTree
create table t_order_smt(\id UInt32,\sku_id String,\total_amount Decimal(16,2) ,\create_time Datetime \
) engine =SummingMergeTree(total_amount)\partition by toYYYYMMDD(create_time)\primary key (id)\order by (id,sku_id );注意,SummingMergeTree()中的字段为聚合字段,即在哪一维度上进行聚合,这里指定的是total_amount,也可以指定多个字段,但必须是数值类型;
如果不填,以所有非维度列且为数字列的字段为汇总数据列
插入数据:
insert into t_order_smt values\
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),\
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),\
(102,'sku_002',600.00,'2020-06-02 12:00:00');查询结果如下:
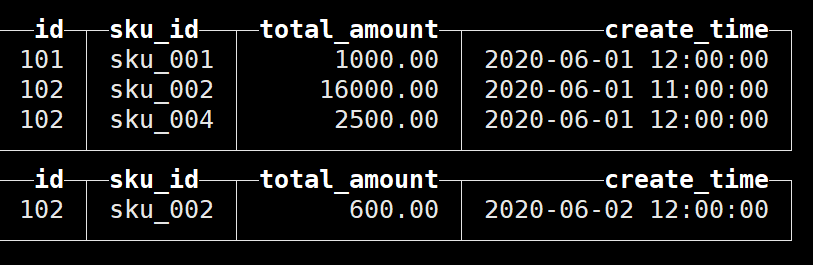
首先可以发现,SummingMergeTree是以order by的列作为维度列进行聚合的,而且是分区内聚合;
同时可以看到,同一分区内的相应数据已经进行了聚合:
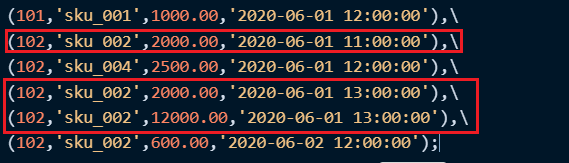
👇
![]()
除了维度列和聚合字段之外,create_time这一列保留最早插入的一行;
再次插入数据进行测试:
可以看到并未进行聚合:
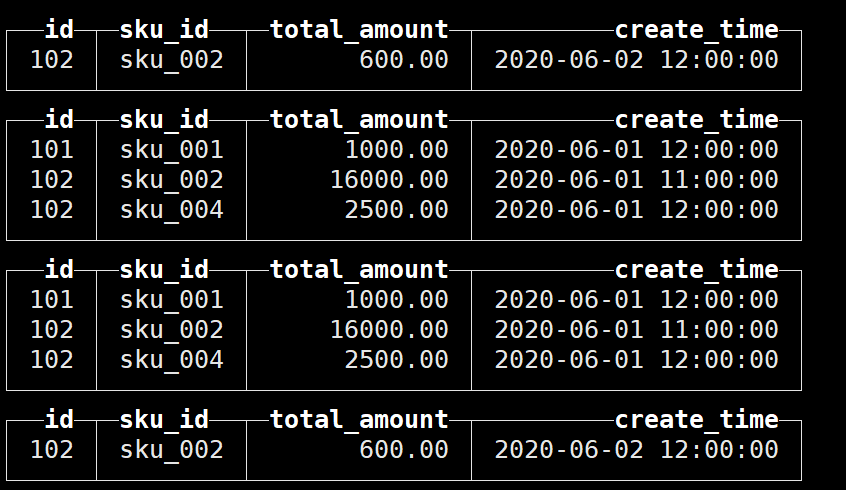
这是因为SummingMergeTree和ReplacingMergeTree一样,都是只有在同一批次插入(新版本)或分片合并时才会进行聚合
因此手动执行合并:optimize table t_order_smt final
可以看到成功聚合:
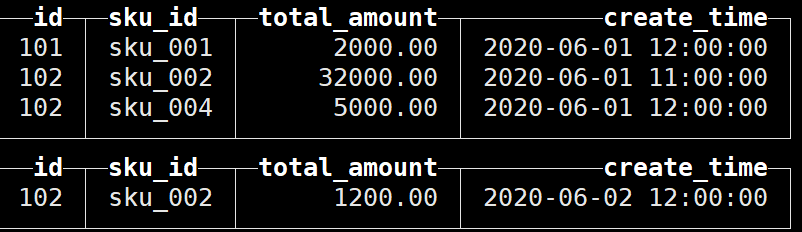
根据聚合表的特性,在实际开发中设计聚合表时,唯一键值、流水号可以去掉,所有字段全部是维度、度量或者时间戳