韩国做美食的视频网站有哪些企点下载
论文:Asynchronous Federated Optimization(12th Annual Workshop on Optimization for Machine Learning)
链接
实现Server的异步更新。每次Server广播全局Model的时候附带一个时间戳,Client跑完之后上传将时间戳和Model同时带回来,Server收到某个Client的上传数据后马上更新,更新时Client的数据要额外乘上一个滞后函数,时间离得越远权重越小。
同时定义了三种滞后函数
- 常数滞后函数
常数滞后函数保持恒定,不随滞后量的变化而变化。 - 多项式滞后函数
多项式滞后函数随滞后量增大而单调递减。 - 锥形滞后函数
锥形滞后函数在滞后量较小时保持恒定值,当滞后量超过某一阈值后开始递减。

论文:Pisces: efficient federated learning via guided asynchronous training(ACM SoCC 2022)
链接
考虑到异步FL会导致一直有Client上传梯度,导致Server不断更新全局Model,使得算法变得低效,论文提出设置一个异步FL中同时train的Client数量上限,并提出了一个评分标准,每次优先让分高的跑。
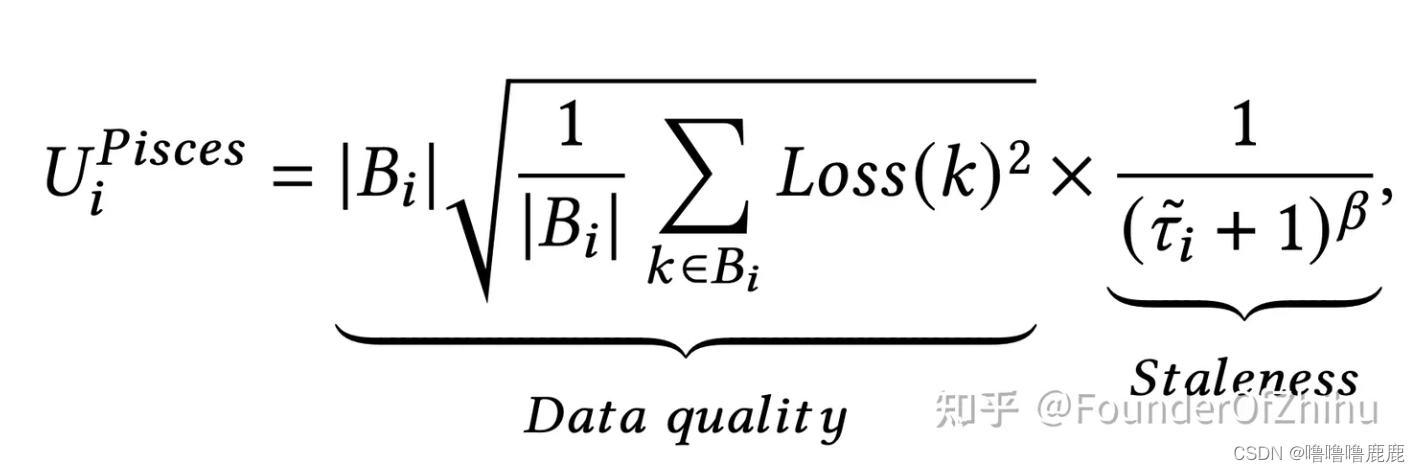
如果想评分高,就得数据量大、loss高、相隔时间短。

这是该论文的另一个算法。b是超参数,称为目标滞后边界,用于调节Server聚合的频率,Lmax是所有Client更新所需时间的最大值。二者相除得到一个I,代表最短更新间隔。如果上次更新和这次更新时间不足I,就不更新,反之更新。
论文:Towards Flexible Device Participation in Federated Learning(AISTATS 2021)
链接
文章涉及的东西比较多,主要就是考虑了新进设备、设备退出、设备没跑完一次流程这三种情况。
1.首先就是分析了设备离开,也就是某个设备在某次训练后退出了FL。
先提了一嘴全局目标函数

文章说在某个设备离开后,可以有两种操作。第一种就是让他完全退出,就是全局目标函数里也没有他了。第二种就是让他保留全局目标函数里的权重。
二者的区别是第一种情况其他的Client权重会因为这个设备的退出而变大,第二种情况其他权重不会变。据说第二种操作能保持全局目标的一致性,但会导致性能下降,所以需要取舍一下。
2.然后又定义了一个“快速重启”,就是说新设备加入时,对全局目标会有一个拉动的效果,所以需要暂时增加额外的梯度。

3.又考虑了一种Client未能跑完但是就得上传的情况,给出了三种方案。

还有个数学公式,但感觉不重要

论文:Sageflow: Robust Federated Learning against Both Stragglers and Adversaries(NeurIPS 2021)
论文聚焦于掉队者和恶意攻击。
提出基于陈旧度的分组、熵过滤、损失加权平均方法,总称Sageflow。
基于陈旧度的分组
对于每个Client根据速度进行分类,服务器每个周期T采样一次,每次只采样速度为Ti的组的模型信息。每个组内部分别先依照FedAVG聚合一下,然后再所有组全部乘上各自的陈旧度聚合起来,形成最终的全局model。

熵过滤
共享少数数据,然后利用这些少数数据跑出一个熵,熵就是用于评估两个模型之间预测分布的差异度,如果差异过大高于某个阈值则可能是恶意攻击,过滤掉。

损失加权平均
跟熵差不多,每个model计算权重的时候额外乘跟全局model的区别值,跟全局model区别越大自身的权重越低。这可以缓解轻微的恶意攻击。
论文:A General Theory for Federated Optimization with Asynchronous and Heterogeneous Clients Updates(ICML2023)
文章主要是数学分析证明算法的收敛性,算法只有很少一部分。
提出了随机权重的方法,但是没有见得哪里随机。
具体方法是Server定时收集一下Client的全部梯度,如果Client在规定时间内完成了本地计算,则权重✖️1,否则变为0。
然后每个Client的权重综合考虑了数据质量和数据量。
没有感觉创新。
论文: Sharper Convergence Guarantees for Asynchronous SGD for Distributed and Federated Learning(NeurIPS2022)
主要是提出了一个自适应步长,步长大小基于时延,时延越大,步长越小。

另外该文章有很多很有价值的数学证明。