网站建设属于移动互联网代做百度关键词排名
背景
由于项目测试需要,计划在华为hadoop集群hive上创建大量表,并且每表植入10w数据,之前分享过如何快速构造hive大表,感兴趣的可以去找一下。本次是想要快速构造多表并载入一些数据。
因为之前同事在构造相关测试数据时由于创建过多默认textfile格式的测试表,导致存储过载,集群down掉。因而本次采用表为orc格式,通过对比下textfile格式,发现有一倍的存储消耗差距。orc的压缩格式ZLIB较SNAPPY压缩率更高一些。因此采用orc的zlib压缩。
那么如何操作便捷生成大量表呢?原计划有如下两种方式:
方式一 HUE创建复制表
该方式借助hue的hivesql执行窗口,进行单表的创建和多表的复制创建。
首先创建一个orc表
`CREATE TABLE `table_hive_xntest1`(`hylbz` string, `hgjdqlbz` bigint, `hsssqlbz` binary, `cjhjywid` boolean, `cchjywid` decimal(10,0), `gxsjd` date, `sg` string, `zp` string, `csrq` timestamp, `cssj` int, `csdgjdq` int, `csdssxq` double, `csdxz` varchar(200), `dhhm` int, `jhryxm` int, `jgxz` int, `jhryzjzl` int, `jhryzjhm` int, `jhrywwx` int, `jhrywwm` int, `jhrylxdh` int, `jhrezjzl` int, `jhrezjhm` int, `jhrewwx` int, `jhrewwm` int, `jhrelxdh` int, `fqzjzl` int, `fqzjhm` int, `fqwwx` int, `zpid` int, `mlpid` int, `ryid` int, `mlpnbid` int, `yxqxqsrq` string, `yxqxjzrq` string, `qfjgint` varchar(20000))ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS orc tblproperties ("orc.compress"="ZLIB");
然后通过载入文件的方式加载入数据到表空间下(hue、hdfs-webui或者hdfs命令行均可)。
再在hue的hivesql命令行中通过批量复制创建表的方式来创建表。
create table xntest_tb_new_1 as select * from table_hive_xntest1;

在这里插入图片描述
但是执行过程中发现速度远不及预期,单表复制新建耗时约1.5s,但是批量sql执行后,越来越慢,目标需要创建上万数据表,因此速度上不满足使用需求。因此计划使用方式二
方式二 beeline执行hivesql脚本
之前使用过HDP版本的hive和beeline命令,直接在节点服务器上执行命令即可。但是华为集群有其特殊之处。登录节点服务器后。beeline查无此命令,hive命令也是如此。

后面通过请教开发得知,华为集群采kerberos认证方式,需要先安装hive客户端并在每次执行beeline前进行kerberos认证(类似登录)且仅在当前ssh会话中有效,然后再执行相关命令即可。下面介绍下如何安装hive客户端并进行kerberos认证。
第一步、登录华为MRS,下载用户登录凭据,用户需要有hive相关权限。

第二步 下载完整的hive客户端。平台类型和hadoop节点上的物理架构一致,hive客户端建议安装在集群节点上()安装在集群节点外可能需要修改一些ip映射满足host访问)
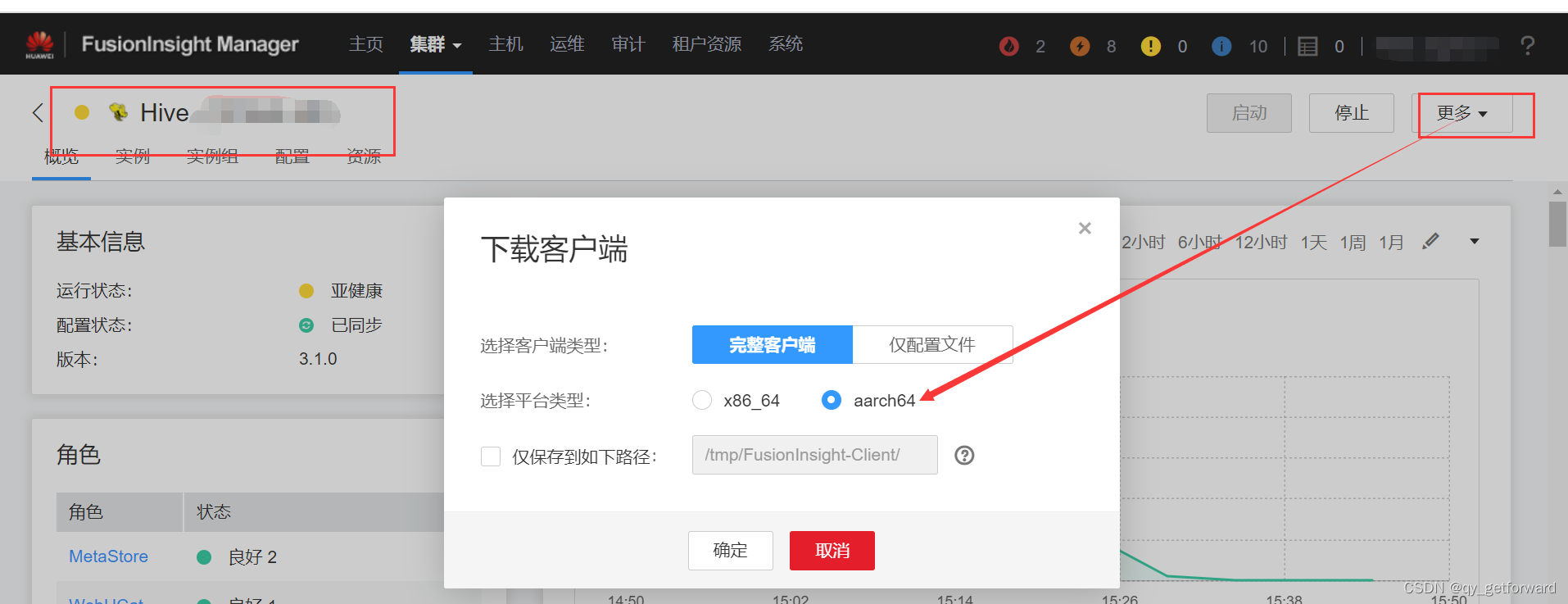
第三步 上传前两步文件到节点服务器并解压
进入hive客户端解压目录内执行安装命令,命令行参数为安装的hive客户端的路径,会自动创建
[root@HD01 FusionInsight_Cluster_1_Hive_ClientConfig]# ./install.sh /opt/hiveclient
安装成功后进入安装目录内执行环境变量初始化:
[root@HD01 hiveclient]# source bigdata_env ```到这里beeline命令已经可以执行了,但是因为没有完成认证,是无法操作hive的。
还需要执行kinit命令,使用第一步下载的认证凭据进行认证。命令如下:
kinit -kt youpath/user.keytab you_hw_username
认证完成之后,直接beeline命令即可访问执行hivesql了。通过将批量执行复制创建表的hivesql,全部存储到一个文件中去,然后beeline -f hivesql.file 即可,命令如下:
nohup beeline -f ./tc_3w.sql &
以上命令将执行进程放到后台执行,进度状态查看当前所在路径下的nohup.out实时打印输出即可。
通过查看nohup输出,基本2s复制创建完成一个表,速度基本满足需要,后台运行等待完成即可。