今天上午北京发生了什么网站网页的优化方法
交叉验证是一种统计分析方法,它的目的是通过在同一数据集上重复并分割训练和测试数据,来评估机器学习模型的性能。以下是这三种交叉验证方法的区别:
-
KFold(K-折叠)
- 在KFold交叉验证中,原始数据集被分为K个子集。
- 每次,其中的一个子集被用作测试集,而其余的K-1个子集合并后被用作训练集。
- 这个过程重复进行K次,每次选择不同的子集作为测试集。
- KFold不保证每个折叠的类分布与完整数据集中的分布相同。
-
Stratified-KFold(分层K-折叠)
- Stratified-KFold是KFold的变体,它会返回分层的折叠:每个折叠中的标签分布都尽可能地与完整数据集中的标签分布相匹配。
- 这种方法特别适用于类分布不均衡的情况,确保每个折叠都有代表性的类比例。
- 就像KFold一样,每个折叠轮流被用作测试集,其他折叠用作训练集。
-
StratifiedShuffleSplit(分层随机分割)
- StratifiedShuffleSplit是另一种分层抽样技术,它也确保了每次分割中都能维持原始数据集中各个类的比例。
- 与Stratified-KFold不同,StratifiedShuffleSplit将数据集随机打乱,然后切分为训练集和测试集。这个过程会根据需要重复多次。
- 这种方法提供了更多的随机性,并可以通过指定测试集的大小来控制训练集和测试集的比例。
接下来我们用代码来解释他们的区别:
一. Kfold
先来创建数据集:
splits = 5
tx = range(10)
ty = [0] * 5 + [1] * 5再来导入相应的模块:
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit,
from sklearn import datasets先实例化一个KFold,shuffle = Flase的情况:
Kfold = KFold (n_splits=splits, shuffle=False)再来看看Kfold是如何来做交叉验证的:
print("Fold")
for train_index, test_index in Kfold.split(tx, ty):print("TRAIN:", train_index, "TEST:", test_index)输出结果为:

可以看到,Kfold的测试集是按照顺序不重复的每次取出两个,一共做5次训练。
当shuffle = true时再来运行一次代码:
Kfold = KFold (n_splits=splits, shuffle=False)print("Fold")
for train_index, test_index in Kfold.split(tx, ty):print("TRAIN:", train_index, "TEST:", test_index)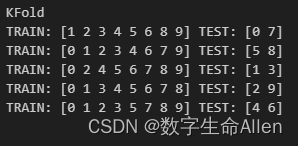
可以看到Kfold的测试集是无规则不重复的每次取出两个,一共做5次训练。
二. Stratified-KFold
我们用相同的数据集,先来看看shuffle = False的情况:
stratKfold = StratifiedKFold(n_splits=splits, shuffle=False)
print("stratKFold")
for train_index, test_index in stratKfold.split(tx, ty):print("TRAIN:", train_index, "TEST:", test_index)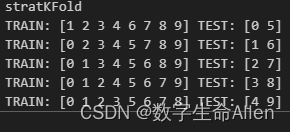
可以看到测试集被分层了。因为我们是二分类数据,所以每次都是从0类中抽一个,1类中抽一个,而且是按顺序抽取,即从0类的第一个数据,1类的第一个数据组合形成一个测试集。数据是不重复的。
先来看看shuffle = true的情况:

可以看到测试集依然被分层抽取,但不是按照顺序抽取,且依旧保证数据是不重复的。
三. StratifiedShuffleSplit
先来实例化一个StratifiedShuffleSplit并分隔数据集:
shufflesplit = StratifiedShuffleSplit(n_splits=splits, random_state=42, test_size=2)
for train_index, test_index in shufflesplit.split(tx, ty):print("TRAIN:", train_index, "TEST:", test_index)
可以看到测试集被分层了,同时我们可以根据test_size选择测试集的比例,并且数据是可以重复的,可以看到测试集3出现了2次。但我们把test_size设置为0.3时:

可以看到测试集有3个样本,多个数据发生了重复。
总结一下:Kfold交叉验证不考虑样本标签是否均衡的问题,仅是单纯的将样本分为K份,1份是测试,k-1份做训练;Stratified-KFold会根据样本标签分类,让训练集和测试集都保持原有样本的标签分类情况,shuffle = False or true决定的是分隔是顺序分隔还是随机分隔,同时数据是不可重复利用的;StratifiedShuffleSplit可以对数据进行重复利用,也只有StratifiedShuffleSplit可以控制测试集和训练集的比例。