口碑做团购网站百度上怎么做推广
爬取豆瓣(线程、Session)优化版本
该文章只是为了精进基础,对Session、threading、网站请求解析的理解。
此版本没有爬取详情页。还在学习阶段的读者可以尝试一下。
适用于基础刚开始学习爬虫的!
1.改进点:
- 将普通的
requests.get换成了requests.Session()。 - 增加了多线程
threading。
2.运行条件
pip install -i https://mirrors.aliyun.com/pypi/simple pymongo
pip install -i https://mirrors.aliyun.com/pypi/simple requests
PyCharm安装和破解
2.1.MongoDB下载地址
MongoDB打开地址选择4.4版本即可,或者其他版本。可视化工具可以下载Navicat Premium
3.Session
Session的作用在第一次请求之后,服务端响应的Cookie信息,在下次请求的时候会自动添加上去。
4.分析过程
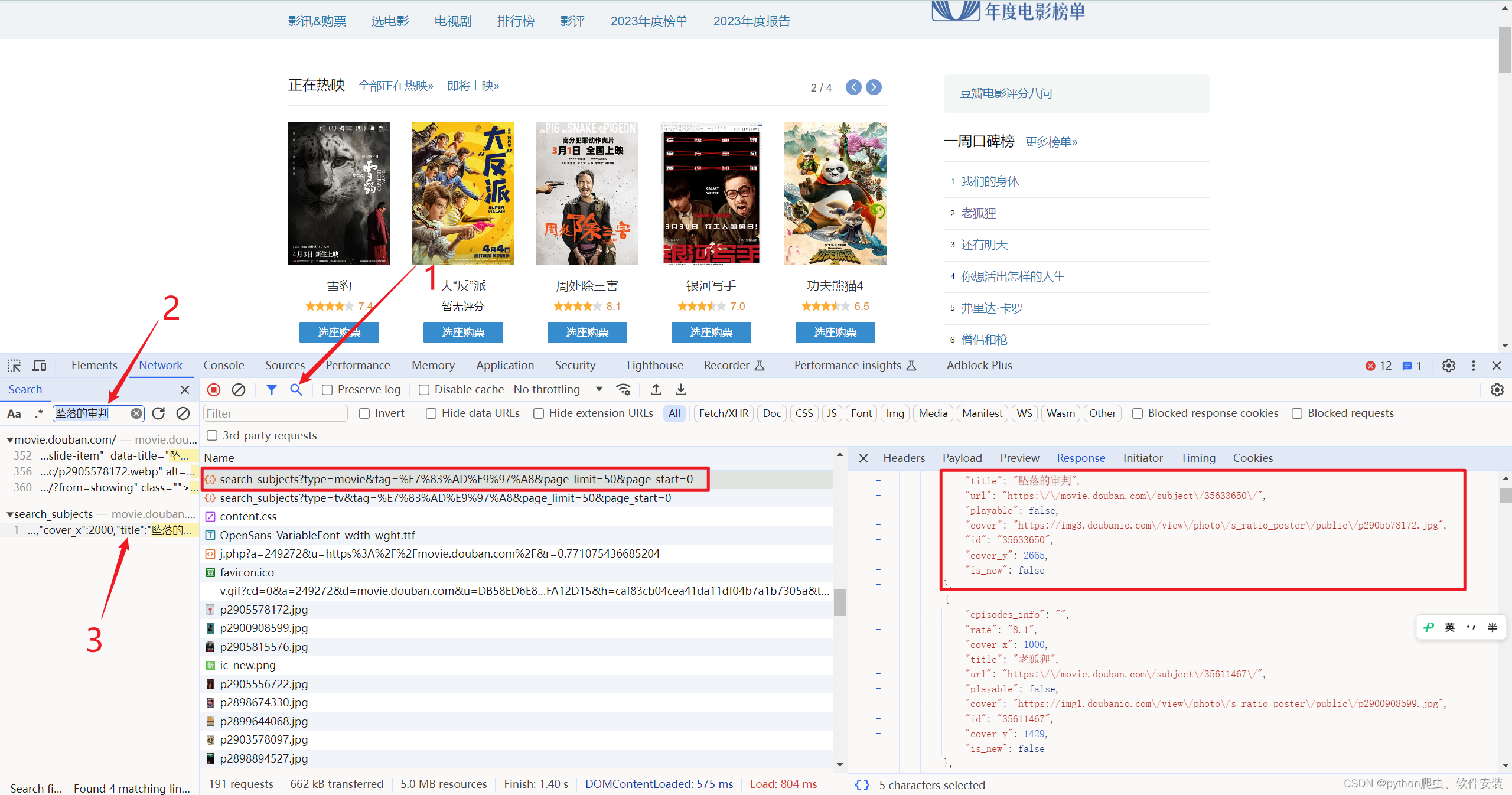
- 打开网址豆瓣电影
- F12分析请求过程。
- 根据电影名称搜索在哪个请求响应体中。
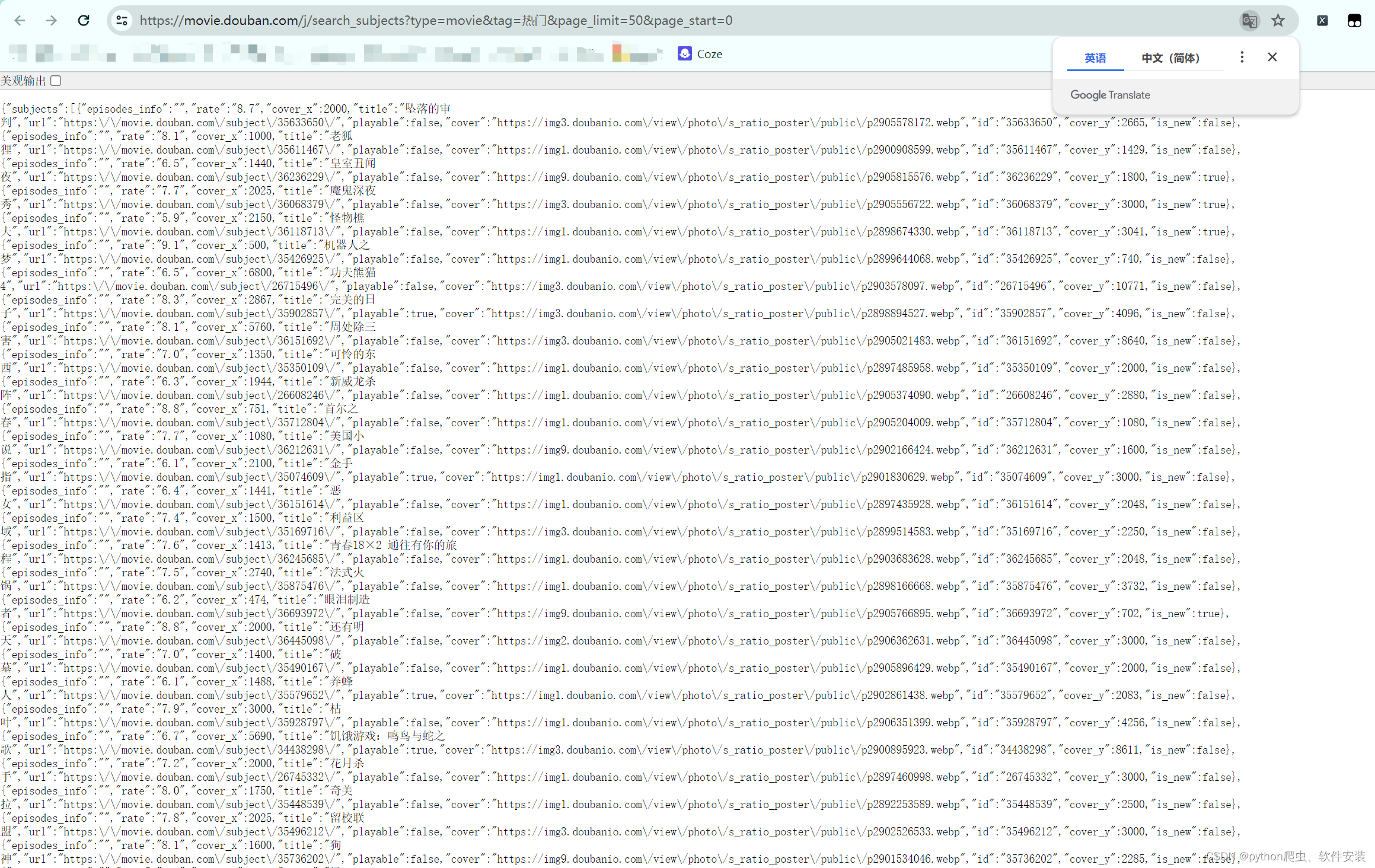
- 分析此URL,调整
tag和page_limit可以变更获取的内容。
5.配置参数
import time
import requests
from pymongo import MongoClient
import threading
import logginglogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')# 定义全局session,用于保存cookie
session = requests.Session()INDEX_URL = 'https://movie.douban.com/j/search_subjects?type=movie&tag={tag}&page_limit={page}' # 类型的url
DETAIL_URL = 'https://movie.douban.com/subject/{id}' # 详情的urlheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36','Referer': 'https://movie.douban.com/',
}# session设置某些全局请求头配置项目
session.headers = headers# 定义mongo链接
MONGO_URL = 'mongodb://localhost:27017'
MONGO_DB = 'douban_data'
COLLECTION_INDEX = 'douban_index'
COLLECTION_DETAIL = 'douban_detail'mongo = MongoClient(MONGO_URL) # 链接mongo
db = mongo[MONGO_DB] # 选择数据库
coll_index = db[COLLECTION_INDEX] # 首页的
coll_detail = db[COLLECTION_DETAIL] # 电影详情页的存储集合tags = None # 类型
6.获取电影类别信息
# 获取类型:https://movie.douban.com/j/search_tags?type=movie&source=index
def get_type():"""获取电影类型"""global tagsurl = 'https://movie.douban.com/j/search_tags?type=movie&source=index'response = session.get(url=url)tags = dict(response.json())['tags']logging.info('获取类型:%s' % tags)7.请求并获取JSON数据
其中
time.sleep()用来模拟网络请求延迟。测试多线程是否有效!
def spider_index(url):"""根据获取的类型挨个获取电影信息"""logging.info('开始获取:%s' % url)try:response_index = session.get(url=url)subjects = dict(response_index.json()).get('subjects')# logging.info('请求成功内容:%s' % subjects)time.sleep(2) # 模拟网络延迟for subject in subjects:# 写入mongodbcoll_index.insert_one(subject)except Exception as e:logging.error('请求出现异常!!!')
8.目前没有爬取详情页,后续完善!
9.完整代码
import time
import requests
from pymongo import MongoClient
import threading
import logginglogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')# 定义全局session,用于保存cookie
session = requests.Session()INDEX_URL = 'https://movie.douban.com/j/search_subjects?type=movie&tag={tag}&page_limit={page}' # 类型的url
DETAIL_URL = 'https://movie.douban.com/subject/{id}' # 详情的urlheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36','Referer': 'https://movie.douban.com/',
}# session设置某些全局请求头配置项目
session.headers = headers# 定义mongo链接
MONGO_URL = 'mongodb://localhost:27017'
MONGO_DB = 'douban_data'
COLLECTION_INDEX = 'douban_index'
COLLECTION_DETAIL = 'douban_detail'mongo = MongoClient(MONGO_URL) # 链接mongo
db = mongo[MONGO_DB] # 选择数据库
coll_index = db[COLLECTION_INDEX] # 首页的
coll_detail = db[COLLECTION_DETAIL] # 电影详情页的存储集合tags = None # 类型# 获取类型:https://movie.douban.com/j/search_tags?type=movie&source=index
def get_type():"""获取电影类型"""global tagsurl = 'https://movie.douban.com/j/search_tags?type=movie&source=index'response = session.get(url=url)tags = dict(response.json())['tags']logging.info('获取类型:%s' % tags)def spider_index(url):"""根据获取的类型挨个获取电影信息"""logging.info('开始获取:%s' % url)try:response_index = session.get(url=url)subjects = dict(response_index.json()).get('subjects')# logging.info('请求成功内容:%s' % subjects)time.sleep(2) # 模拟网络延迟for subject in subjects:# 写入mongodbcoll_index.insert_one(subject)except Exception as e:logging.error('请求出现异常!!!')if __name__ == '__main__':get_type()tasks = [INDEX_URL.format(tag=tag, page=250) for tag in tags]threads = [] # 创建线程列表for task in tasks:threads.append(threading.Thread(target=spider_index, args=(task,)))for thread in threads:thread.start()