哪家公司做移动网站最新的销售平台

数据的截图,数据的说明:
# 字段 数据类型 # 城市 string # 名称 string # 星级 string # 评分 float # 价格 float # 销量 int # 省/市/区 string # 坐标 string # 简介 string # 是否免费 bool # 具体地址 string
拿到数据第一步我们先导入数据,查看一下数据的分布,类型等
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltdata = pd.read_excel("旅游景点.xlsx")
pd.set_option("display.max_columns",100)
# print(data.head())print(data.info())
print(data.isnull().sum())接下来我们来看具体的问题:
# 问题(先大概分析一下) # 1、全国景点分布 (我们分析城市的分布即可) # 2、国民出游分析 (我们可以分析评分,城市,销量之间的关系 ) # 3、景区价格分析 (我们分析价格因素)
# 问题看完之后,我们开始对数据进行预处理 # 由于星级对我们问题的分析帮助很大,所以我们无法用删除,或者众数等方式填充,因此我们用无来填充,将其划分为一个新的类别
data["星级"] = data["星级"].fillna("无")
print(data["星级"].isnull().sum())至于简介和地址,缺失数据无关紧要,这里我们可以选择用无来填充,也可以用删除来处理,为了不破坏数据的完整性,这里我选择用无来填充
data = data.fillna("无")
# print(data.isnull().sum())
# 这样我们的数据就没有了缺失值
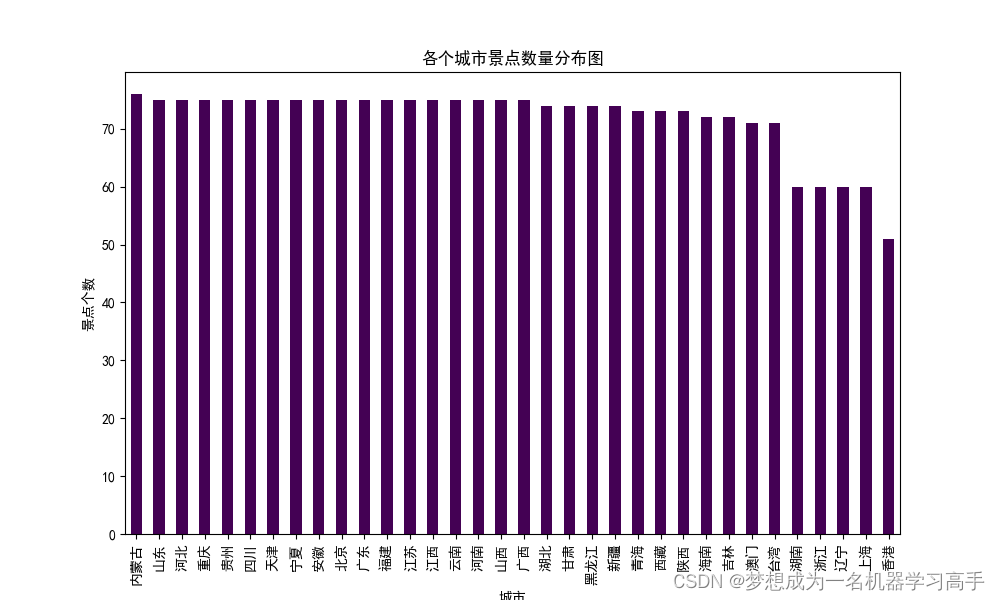
# print(data.info())# 1、全国景点分布 (我们分析城市的分布即可)
scenic = data['城市'].value_counts().sort_values(ascending=False)
plt.figure()
scenic.plot(kind='bar',stacked=False,colormap='viridis',figsize=(10,6))
plt.title("各个城市景点数量分布图")
plt.xlabel('城市')
plt.ylabel('景点个数')
# plt.show()# 2、国民出游分析 (我们可以分析评分,城市,销量之间的关系 )
# data['销量'] = data['销量'].astype(int) 这种转换类型的方法,如果有无法转换的值,则无法转换
data['评分'] = pd.to_numeric(data['评分'], errors='coerce')
data['销量'] = pd.to_numeric(data['销量'],errors='coerce')
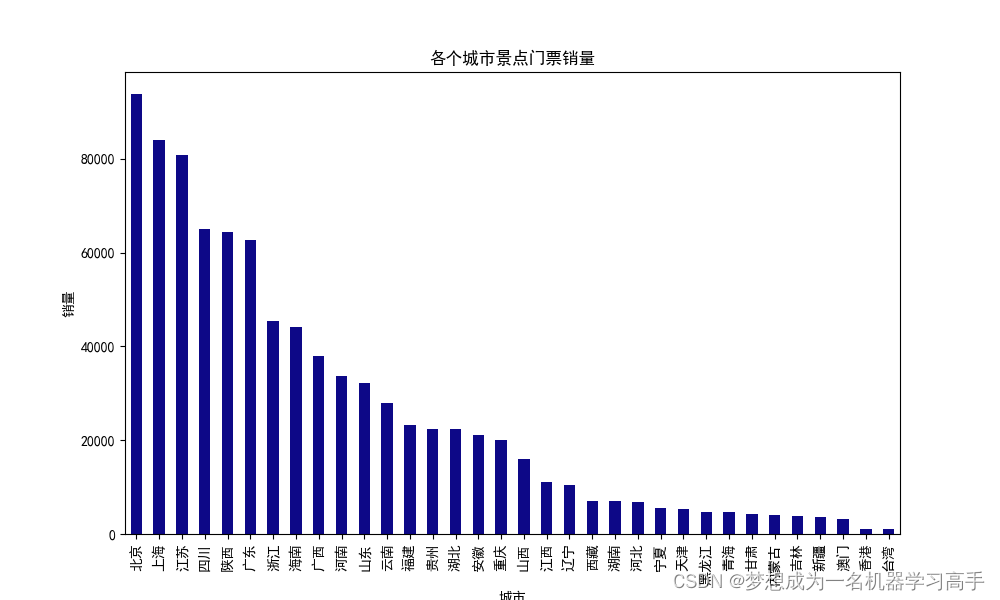
data['价格'] = pd.to_numeric(data['价格'],errors='coerce')city_sales = data.groupby('城市')['销量'].sum()
city_sales = city_sales.sort_values(ascending=False)plt.figure()
city_sales.plot(kind='bar',stacked=True,colormap='plasma',figsize=(10,6))
plt.title('各个城市景点门票销量')
plt.xlabel('城市')
plt.ylabel('销量')
# 从销量可以看出北京,上海,江苏,四川,陕西,广东的销量较高,因此,我们着重分析这六个地方的景点评分
shanghai = data[data['城市'].str.contains('上海')]
beijing = data[data['城市'].str.contains('北京')]
jiangsu = data[data['城市'].str.contains('江苏')]
sichuan = data[data['城市'].str.contains('四川')]
shanxi = data[data['城市'].str.contains('陕西')]
guangdong = data[data['城市'].str.contains('广东')]shanghai_group = shanghai.groupby('名称')['销量'].sum().reset_index()
beijing_group = beijing.groupby('名称')['销量'].sum().reset_index()
jiangsu_group = jiangsu.groupby('名称')['销量'].sum().reset_index()
sichuan_group = sichuan.groupby('名称')['销量'].sum().reset_index()
shanxi_group = shanxi.groupby('名称')['销量'].sum().reset_index()
guangdong_group = guangdong.groupby('名称')['销量'].sum().reset_index()shanghai_sort = shanghai_group.merge(shanghai[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
beijing_sort = beijing_group.merge(beijing[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
jiangsu_sort = jiangsu_group.merge(jiangsu[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
sichuan_sort = sichuan_group.merge(sichuan[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
shanxi_sort = shanxi_group.merge(shanxi[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)
guangdong_sort = guangdong_group.merge(guangdong[['名称','评分']].drop_duplicates(),on='名称').sort_values(by='销量', ascending=False).head(10)shanghai_sort.reset_index(drop=True,inplace=True)
beijing_sort.reset_index(drop=True,inplace=True)
jiangsu_sort.reset_index(drop=True,inplace=True)
sichuan_sort.reset_index(drop=True,inplace=True)
shanxi_sort.reset_index(drop=True,inplace=True)
guangdong_sort.reset_index(drop=True,inplace=True)plt.figure()
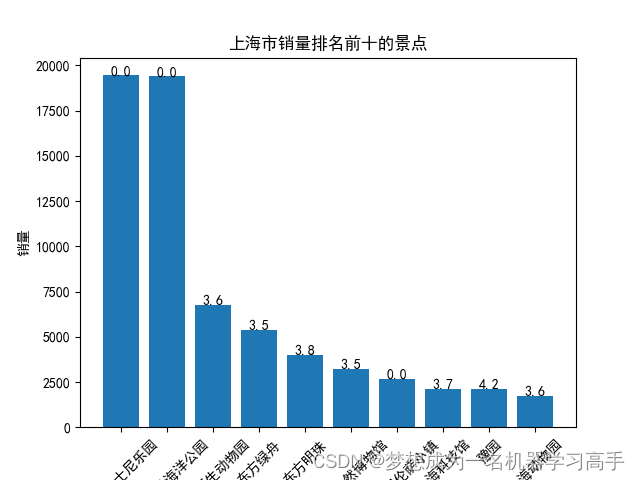
plt.bar(shanghai_sort['名称'],shanghai_sort['销量'])
for i, v in enumerate(shanghai_sort['评分']):plt.text(i, shanghai_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('上海市销量排名前十的景点')
plt.xticks(rotation=45)plt.figure()
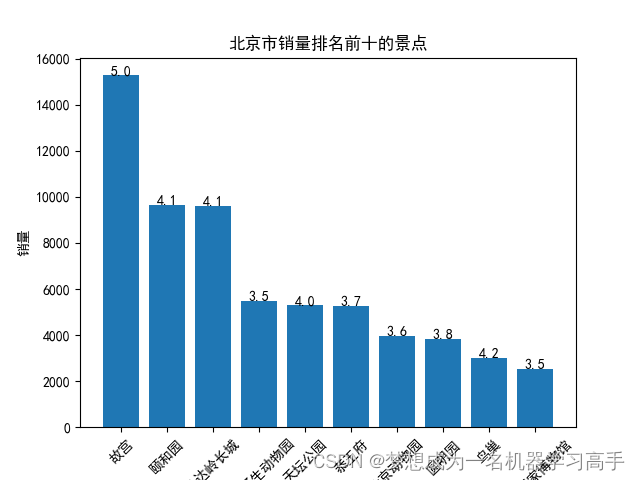
plt.bar(beijing_sort['名称'], beijing_sort['销量'])
for i, v in enumerate(beijing_sort['评分']):plt.text(i, beijing_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('北京市销量排名前十的景点')
plt.xticks(rotation=45)plt.figure()
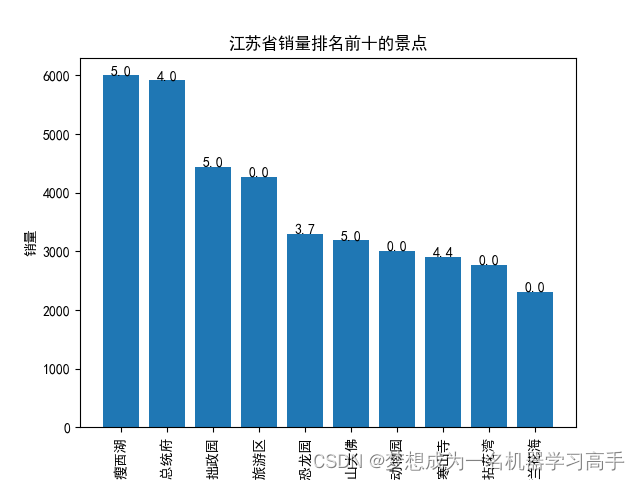
plt.bar(jiangsu_sort['名称'], jiangsu_sort['销量'])
for i, v in enumerate(jiangsu_sort['评分']):plt.text(i, jiangsu_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('江苏省销量排名前十的景点')
plt.xticks(rotation='vertical')plt.figure()
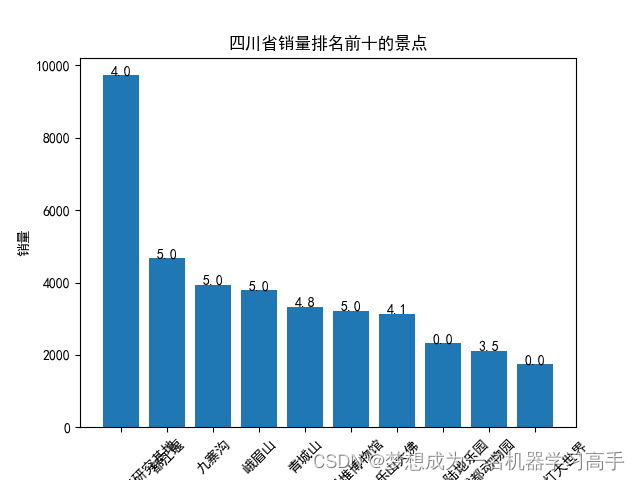
plt.bar(sichuan_sort['名称'], sichuan_sort['销量'])
for i, v in enumerate(sichuan_sort['评分']):plt.text(i, sichuan_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('四川省销量排名前十的景点')
plt.xticks(rotation=45)plt.figure()
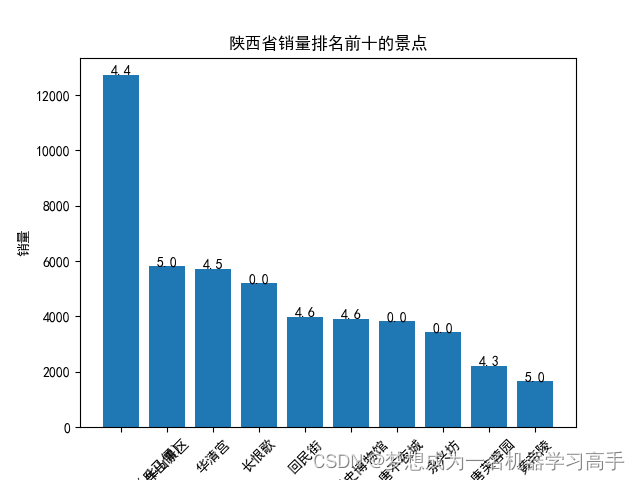
plt.bar(shanxi_sort['名称'], shanxi_sort['销量'])
for i, v in enumerate(shanxi_sort['评分']):plt.text(i, shanxi_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('陕西省销量排名前十的景点')
plt.xticks(rotation=45)plt.figure(figsize=(10,6))
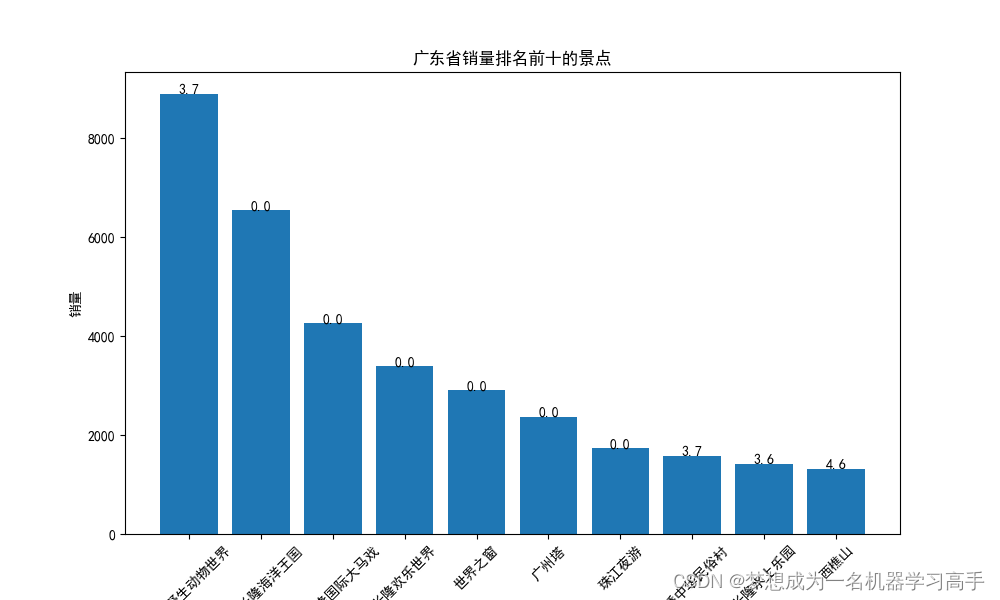
plt.bar(guangdong_sort['名称'], guangdong_sort['销量'])
for i, v in enumerate(guangdong_sort['评分']):plt.text(i, guangdong_sort['销量'][i] + 0.2, str(v), ha='center')plt.xlabel('名称')
plt.ylabel('销量')
plt.title('广东省销量排名前十的景点')
plt.xticks(rotation=45)由此,我们结合这几个分析来回答这几个问题: